reddit gpt summarizer
1.0.0
openai 互換コネクタ用に LiteLLM に更新され、さまざまなモデルのサポートを簡単に追加できるようになり、構成に単一のモデルの json ファイルを使用できるようになりました。 Google Gemini AI Studio を使用するための適切な API キーがあることを確認してください。 GPT 4o、Sonnet 3.5 のサポート。
新しいクロード モデルをサポートし、全体にいくつかの調整を加えました。
Python が 3.11 に更新されました。 GPT-4 128k および Claude 2.1 + Claude Instant v1.2 のサポートも追加しました。それに応じて依存関係を更新してください。
参照: Anthropic/Claude 2
いくつかの依存関係も更新されました (Anthropic、OpenAI、PRAW、Streamlit)
アップデートの概要ビデオ @YouTube
新しい記事 @ Better Programming/Medium: Claude 100k と GPT 16k による Reddit の要約の変革
人間モデルを使用するための設定を拡張します。また、古い OpenAI 命令モデルのサポートも追加されました。ほとんどはガベージ出力を生成しますが、テストには役立ちます。とはいえ、Text Davinci 003 は主観的には最高品質の出力の一部を生成します。新しい 100k モデルは、多くの場合、再帰なしで reddit スレッド全体を消費する可能性があります。
Anthropic API キーを .env ファイルに追加することを忘れないでください。 (ANTHROPIC_API_KEY)
https://www.anthropic.com/index/100k-context-windows
API にアクセスできる場合は、より長いコンテキスト ウィンドウを今すぐ使用できます。ドキュメントを参照してください。 https://platform.openai.com/docs/models/gpt-4 こちらから待機リストに登録してください: https://openai.com/waitlist/gpt-4
記事 @ Better Programming/Medium ChatGPT API を使用した Reddit スレッド サマライザーの構築
これは、GPT-3 を使用してスレッドのコメントの概要を生成する Python ベースの Reddit スレッド サマライザーです。
このスクリプトは、OpenAI API を使用して Reddit スレッドの要約を生成し、再帰的な要約によるプロンプトに基づいてテキストのチャンクを完成させるために使用されます。まず、指定された Reddit スレッドにリクエストを送信し、タイトルと本文を抽出して、スレッド内のすべてのコメントを検索します。
これらのコメントは、指定された数のトークンのグループに連結され、グループのテキスト、Reddit スレッドのタイトルと自己テキストを OpenAI API に要求することで、各グループの概要が生成されます。その後、概要は現在の作業ディレクトリのoutputsフォルダー内のファイルに保存されます。
依存関係をインストールするには、 poetry使用できます。
poetry install OpenAI/Reddit/Anthropic API 認証情報も提供する必要があります。 .envファイルを作成し、以下を追加します。
OPENAI_ORG_ID = YOUR_ORG_ID
OPENAI_API_KEY = YOUR_API_KEY
REDDIT_CLIENT_ID = YOUR_CLIENT_ID
REDDIT_CLIENT_SECRET = YOUR_CLIENT_SECRET
REDDIT_USERNAME = YOUR_USERNAME
REDDIT_PASSWORD = YOUR_PASSWORD
REDDIT_USER_AGENT = linux:com.youragent.reddit-gpt-summarizer:v1.0.0 (by /u/yourusername)
ANTHROPIC_API_KEY = YOUR_ANTHROPIC_KEY 開発依存関係をインストールするには、次を実行します。
poetry install --extras dev
このプロジェクトでは、テストに pytest を使用し、型チェックに mypy を使用します。
テストと型チェックを実行するには、次のコマンドを使用します。
poetry run pytest
poetry run mypy .
このプロジェクトでは、コードの書式設定に黒を使用し、リンティングに pylint も使用します。
コードをフォーマットし、lint エラーをチェックするには、次のコマンドを使用します。
poetry run black .
poetry run pylint .
アプリを実行するには、次のコマンドを使用します。
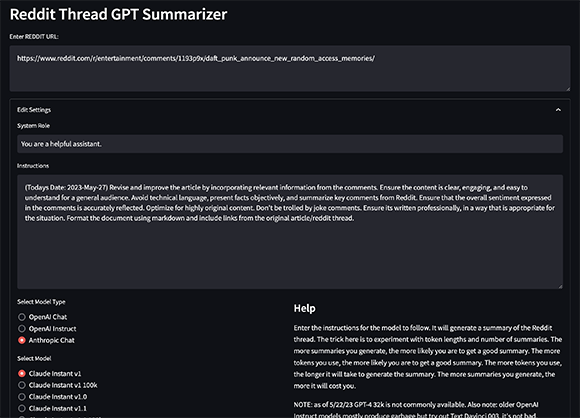
streamlit run app/main.pyこれにより、Reddit スレッドの URL を入力して概要を生成できる Web アプリが起動します。アプリはスレッドの内容に基づいて GPT-3 のプロンプトを自動的に生成し、それらのプロンプトに基づいて概要を生成します。
config.pyファイルを使用してアプリの動作をカスタマイズできます。次の構成オプションが利用可能です。
ATTACH_DEBUGGER : デバッガーをアプリにアタッチするかどうか。WAIT_FOR_CLIENT : アプリを開始する前にクライアントが接続するのを待つかどうか。DEFAULT_DEBUG_PORT : デバッガーに使用するデフォルトのポート。DEBUGPY_HOST : デバッガーに使用するホスト。DEFAULT_CHUNK_TOKEN_LENGTH : コメントのチャンクのデフォルトの長さ。DEFAULT_NUMBER_OF_SUMMARIES : 生成するデフォルトの概要の数。DEFAULT_MAX_TOKEN_LENGTH : サマリーのデフォルトの最大長。LOG_FILE_PATH : ログ ファイルへのパス。LOG_COLORS : ログの色の辞書。REDDIT_URL : 要約する Reddit スレッドの URL。TODAYS_DATE : 今日の日付。LOG_NAME : ログファイルの名前。APP_TITLE : アプリのタイトル。MAX_BODY_TOKEN_SIZE : コメント本文のトークンの最大数。DEFAULT_QUERY_TEXT : GPT-3 プロンプトに使用するデフォルトのテキスト。HELP_TEXT : ユーザーがヘルプ アイコンの上にマウスを移動したときに表示されるテキスト。 このプロジェクトに貢献したい場合は、プル リクエストを作成してください。
このプロジェクトは MIT ライセンスに基づいてライセンスされています。


