すべての愛
AI を活用した、熟練したローカル チャットボット アシスタントですか?
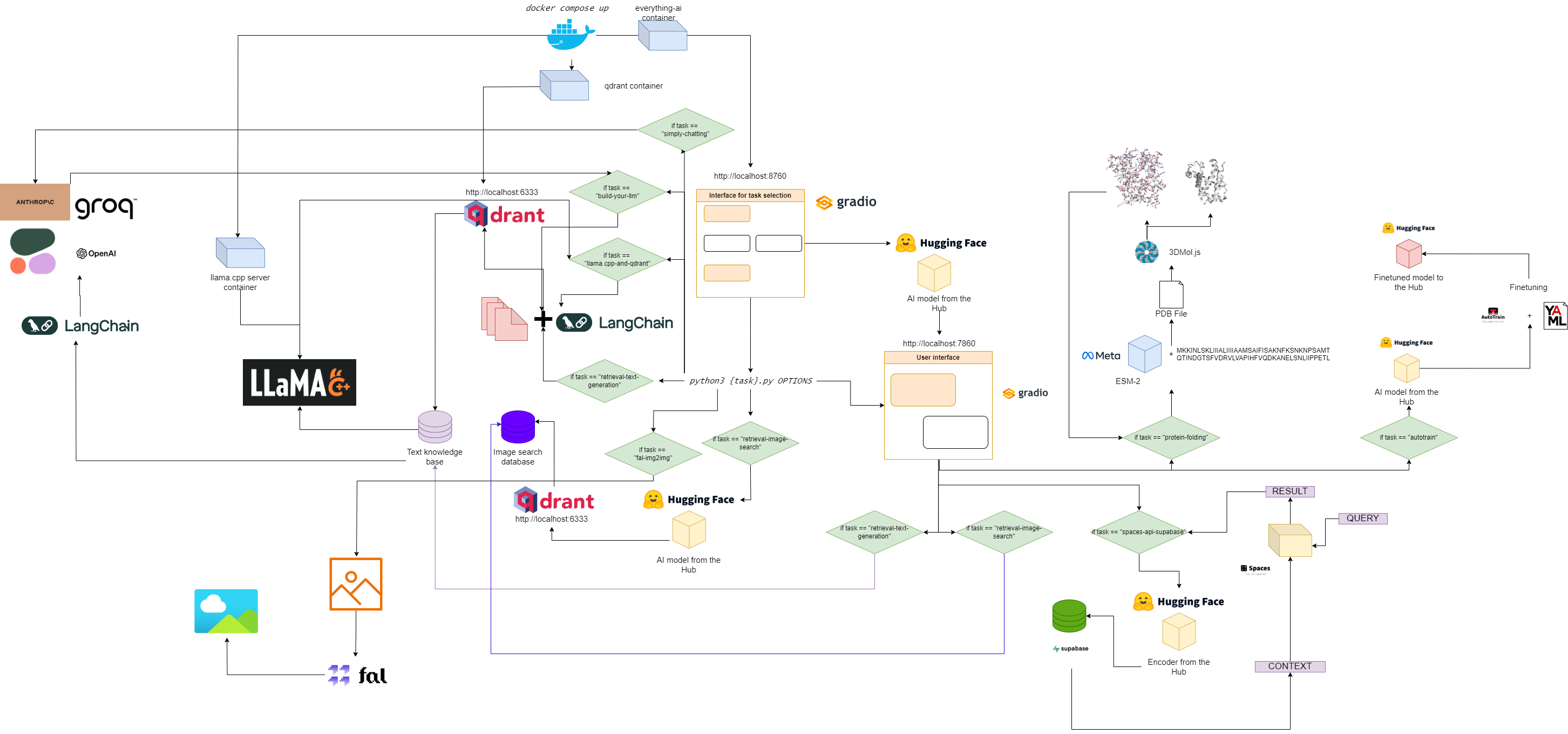
すべてaiのフローチャート
クイックスタート
1. このリポジトリのクローンを作成します
git clone https://github.com/AstraBert/everything-ai.git
cd everything-ai
2. .envファイルを設定します
修正する:
- .env ファイル内の
VOLUME変数を使用して、ローカル ファイル システムを Docker コンテナにマウントできるようにします。 - .env ファイル内の
MODELS_PATH変数を使用して、ダウンロードした GGUF モデルをどこに保存したかを llama.cpp に伝えることができます。 - .env ファイル内の
MODEL変数を使用して、llama.cpp にどのモデルを使用するかを指示できます (gguf ファイルの実際の名前を使用し、拡張子 .gguf を忘れないでください)。 - .env ファイル内の
MAX_TOKENS変数。これにより、出力として生成できる新しいトークンの数を llama.cpp に指示できます。
.envファイルの例は次のとおりです。
VOLUME= " c:/Users/User/:/User/ "
MODELS_PATH= " c:/Users/User/.cache/llama.cpp/ "
MODEL= " stories260K.gguf "
MAX_TOKENS= " 512 "
これは、ローカル マシンの "c:/Users/User/" の下にあるものはすべて Docker コンテナの "/User/" の下にあること、llama.cpp がモデルを検索する場所と検索するモデルを認識していることを意味します。出力の新しいトークンの最大数も含まれます。
3. 必要な画像を取得します
docker pull astrabert/everything-ai:latest
docker pull qdrant/qdrant:latest
docker pull ghcr.io/ggerganov/llama.cpp:server
4. マルチコンテナアプリを実行する
5. localhost:8670に移動し、アシスタントを選択します
次のようなものが表示されます。
次の中からタスクを選択します。
- retrieval-text-generation :
qdrantバックエンドを使用して、モデルの応答をクエリしたり調整したりできる、検索に適したナレッジ ベースを構築します。カンマ区切りのパスとして指定された PDF または PDF の束、または対象となるすべての PDF が保存されているディレクトリのいずれかを渡す必要があります (両方を指定しないでください)。 ISO 命名法を使用して、PDF が記述される言語を指定することもできます -多言語 - agnostic-text-generation : ChatGPT のようなテキスト生成 (取得アーキテクチャなし) ですが、HF Hub 上のすべてのテキスト生成モデルをサポートします (ハードウェアがサポートしている限り!) -多言語
- text-summarization : テキストと PDF を要約し、HF Hub のすべてのテキスト要約モデルをサポート -英語のみ
- 画像生成: 安定した拡散、HF ハブ上のあらゆるテキストから画像へのモデルをサポート -多言語
- image-generation-pollations : 安定した拡散、Pollinations AI API を使用します。 「image-generation-pollinations」を選択した場合、タスク以外に何も指定する必要はありません -多言語
- image-classification : 画像を分類し、HF Hub 上のすべての画像分類モデルをサポートします -英語のみ
- image-to-text : 画像を説明し、HF Hub のすべての画像からテキストへのモデルをサポートします -英語のみ
- audio-classification : オーディオ ファイルまたはマイク録音を分類し、HF ハブのオーディオ分類モデルをサポートします。
- 音声認識: オーディオ ファイルまたはマイク録音を文字起こしし、HF ハブの自動音声認識モデルをサポートします。
- video-generation : テキスト プロンプトに応じてビデオを生成し、HF ハブでテキストからビデオへのモデルをサポート -英語のみ
- プロテインフォールディング: ESM-2 バックボーンモデルを使用して、アミノ酸配列からタンパク質の 3D 構造を取得します - GPU のみ
- autotrain : autotrain-advanced を使用して、HF ユーザー名、HF 書き込みトークン、トレーニング用の yaml 構成ファイルへのパスを指定するだけで、特定のダウンストリーム タスクでモデルを微調整します。
- space-api-supabase : HF Spaces API を Supabase PostgreSQL データベースと組み合わせて使用し、より強力な LLM と大規模な RAG 指向のベクトル データベースを解放します -多言語
- llama.cpp-and-qdrant : retrieval-text-generationと同じですが、推論エンジンとしてllama.cpp を使用するため、モデルを指定してはなりません -多言語
- build-your-llm : Qdrant データベースと PDF、および Anthropic、OpenAI、Cohere、または Groq モデルの機能を組み合わせたカスタマイズ可能なチャット LLM を構築します。必要なのは API キーだけです。 Qdrant データベースを構築するには、カンマ区切りのパスとして指定された PDF または PDF の束、または対象となるすべての PDF が保存されているディレクトリのいずれかを渡す必要があります (両方を指定しないでください)。 ISO 命名法 ( MULTILINGUAL 、 LANGFUSE INTEGRATION )を使用して、PDF が記述される言語を指定することもできます。
- Simply-chatting : Anthropic、OpenAI、Cohere、または Groq モデル (RAG パイプラインなし) を利用して、カスタマイズ可能なチャット LLM を構築します。必要なのは API キーだけです。 -多言語、 LANGFUSE の統合
- fal-img2img : fal.ai ComfyUI API を使用して、PNG および JPEG 画像から画像を生成します。必要なのは API キーだけです。プロンプトとシードを使用して生成をカスタマイズできます -英語のみ
- image-retrieval-search : データベース入力としてフォルダーをアップロードして画像データベースを検索します。フォルダーは次の構造になっている必要があります。
./
├── test/
| ├── label1/
| └── label2/
└── train/
├── label1/
└── label2/
自分の写真から始めてデータベースにクエリを実行できます。
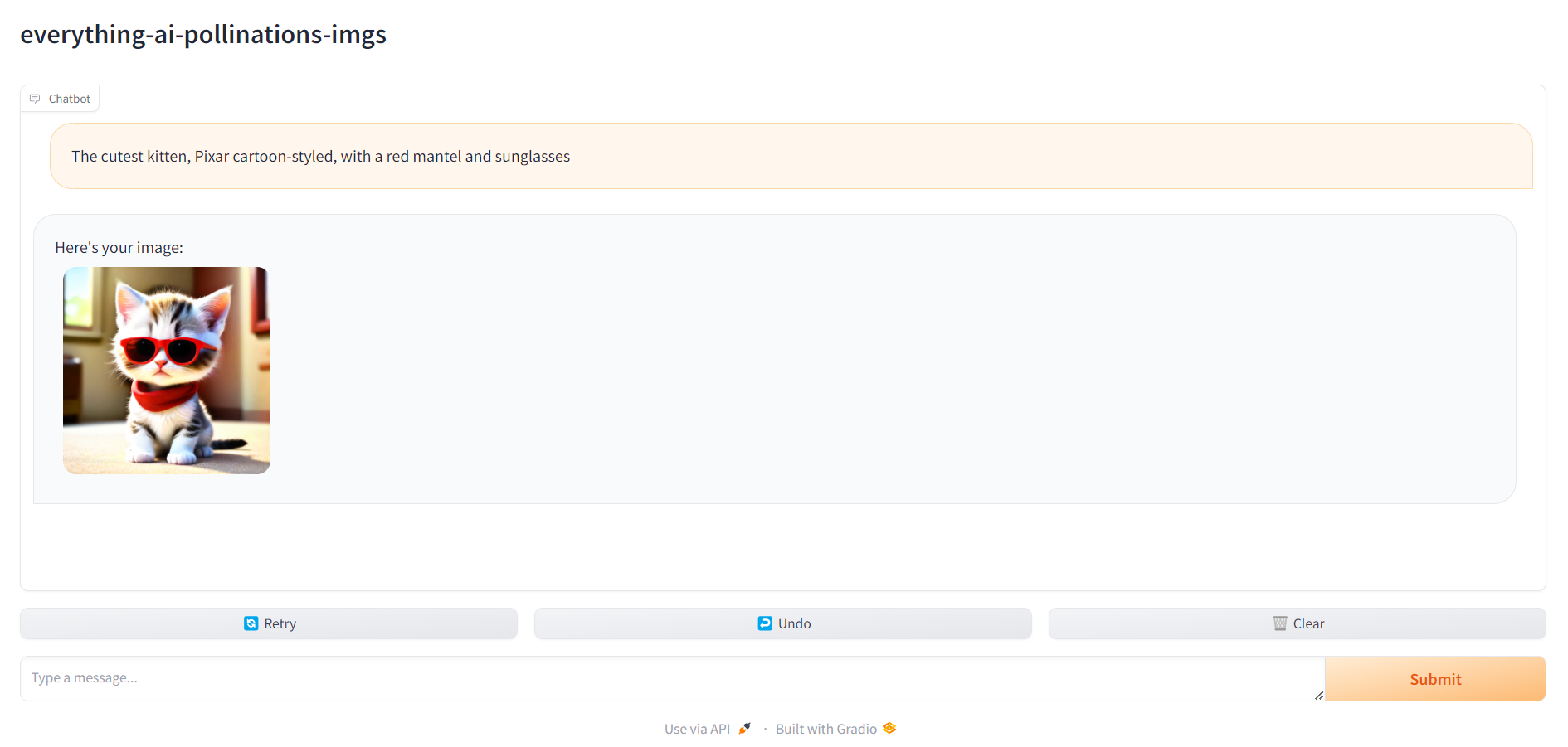
6. localhost:7860に移動し、アシスタントの使用を開始します。
すべての準備が完了したら、 localhost:7860に移動し、アシスタントの使用を開始できます。