LLM Attributor
1.0.0
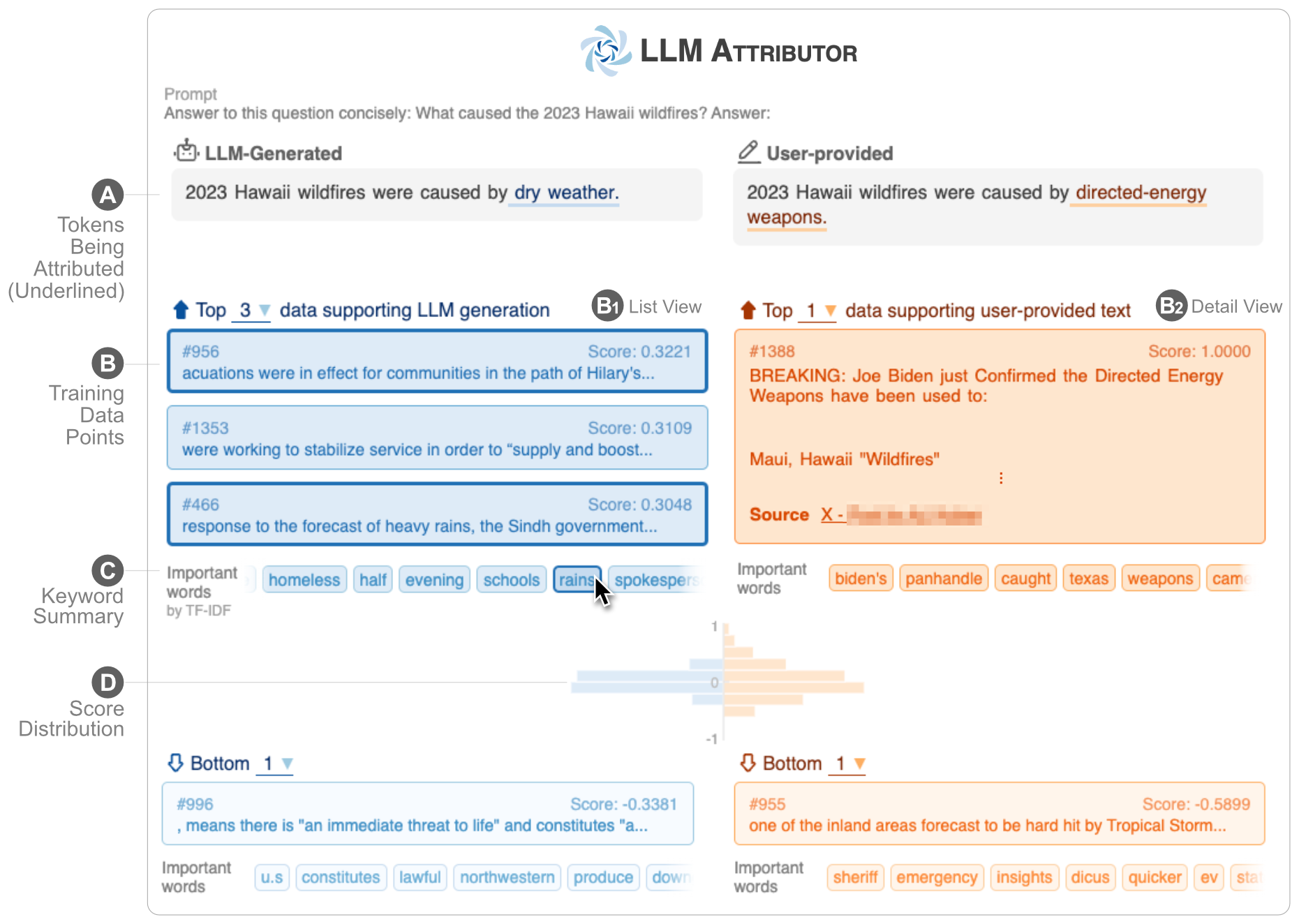
LLM アトリビュータは、大規模言語モデル (LLM) のテキスト生成のトレーニング データの属性を視覚化するのに役立ちます。テキスト フレーズを対話的に選択し、選択したフレーズの生成に関与するトレーニング データ ポイントを視覚化します。モデルで生成されたテキストを簡単に変更し、視覚化された並べて比較することで、変更がアトリビューションにどのような影響を与えるかを観察できます。
 | |
| ?デモ YouTube ビデオ | ✍️ テクニカルレポート |
LLM 属性は、Python Package Index (PyPI) リポジトリで公開されています。 LLM アトリビュータをインストールするには、 pip使用できます。
pip install llm-attributorLLM アトリビュータを計算ノートブック (Jupyter Notebook/Lab など) にインポートし、モデルとデータ構成を初期化できます。
from LLMAttributor import LLMAttributor
attributor = LLMAttributor (
llama2_dir = LLAMA2_DIR ,
tokenizer_dir = TOKENIZER_DIR ,
model_save_dir = MODEL_SAVE_DIR ,
train_dataset = TRAIN_DATASET
)LLAMA2_DIR および TOKENIZER_DIR の場合、ベース LLaMA2 モデルへのパスを入力できます。これらは、モデルがまだ微調整されていない場合に必要です。 MODEL_SAVE_DIR は、微調整されたモデルが保存される (または保存される) ディレクトリです。
disaster-demo.ipynbとfinance-demo.ipynbを試して、LLM アトリビュータの対話型視覚化を試すことができます。
LLM アトリビュータは、Seongmin Lee、Jay Wang、Aishwarya Chakravarthy、Alec Helbling、Anthony Peng、Mansi Phute、Polo Chau、Minsuk Kahng によって作成されました。
このソフトウェアは MIT ライセンスに基づいて利用できます。
ご質問がございましたら、お気軽に問題をオープンするか、Seongmin Lee までご連絡ください。


