serverless rag ynetnews bedrock demo
1.0.0
質問応答 (QA) は、自然言語で提起された事実に基づく質問に対する回答を抽出する重要なタスクです。通常、QA システムは、構造化データまたは非構造化データを含む知識ベースに対してクエリを処理し、正確な情報を含む応答を生成します。高精度を確保することは、特にエンタープライズユースケースにおいて、有用で信頼性の高い質問応答システムを開発するための鍵となります。
Amazon Titan、Anthropic Claude、AI21 Jurassic 2 などの生成 AI モデルは、確率分布を使用して質問に対する応答を生成します。これらのモデルは膨大な量のテキスト データでトレーニングされているため、シーケンスの次に何が来るか、または特定の単語の後にどの単語が続くかを予測できます。ただし、データには常にある程度の不確実性が存在するため、これらのモデルはすべての質問に対して正確または決定的な答えを提供することはできません。
企業は、ドメイン固有の独自データをクエリし、その情報を使用して質問に答える必要があります。より一般的には、モデルがトレーニングされていないデータです。
このリポジトリでは、次の QA パターンを検討します。
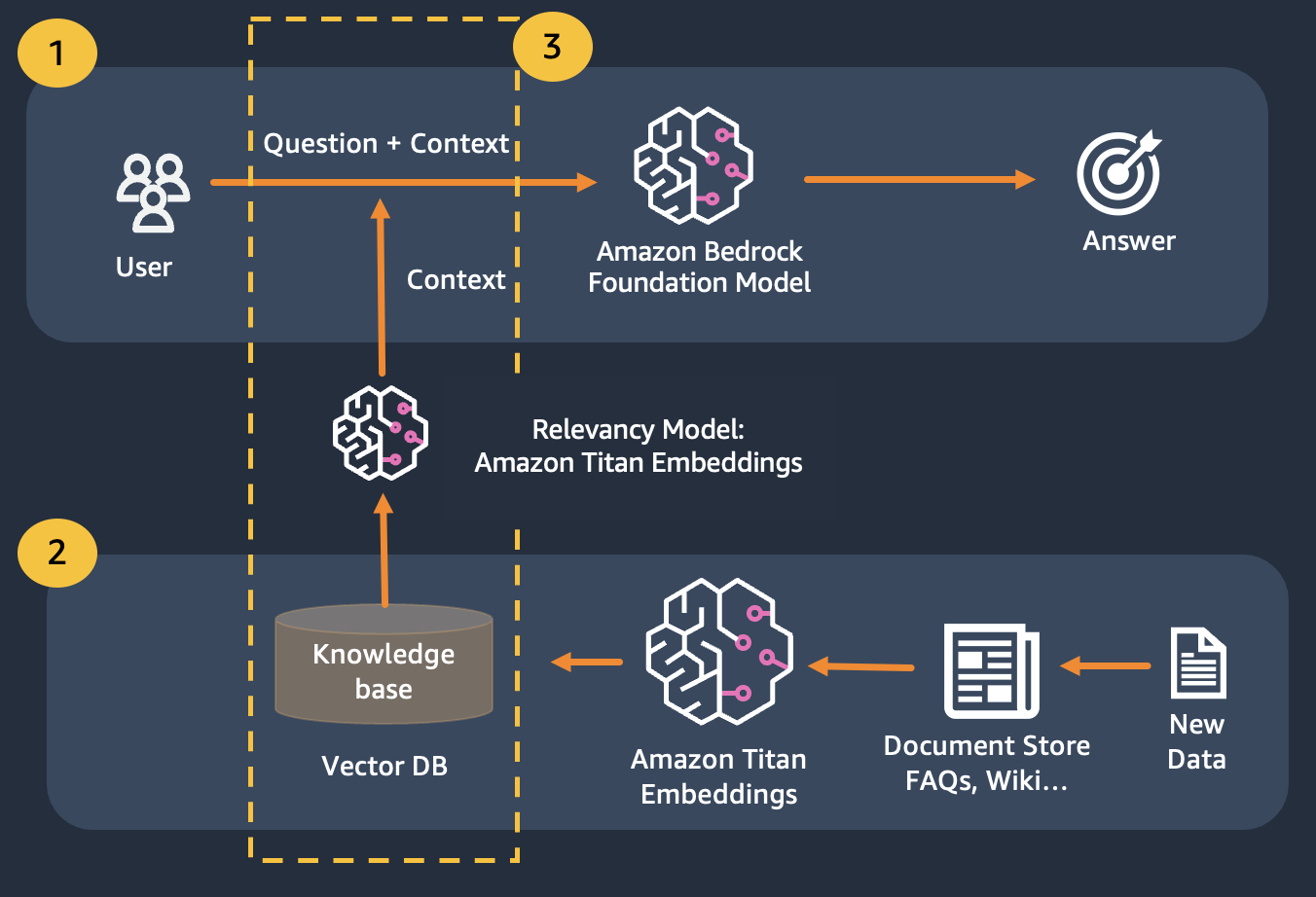
私たちは、検索拡張生成を使用します。これは、質問をできるだけ多くの関連コンテキストと連結する最初の生成を改良したもので、これには探している答えや情報が含まれる可能性が高くなります。ここでの課題は、使用できるコンテキスト情報の量には制限があり、モデルのトークン制限によって決定されることです。 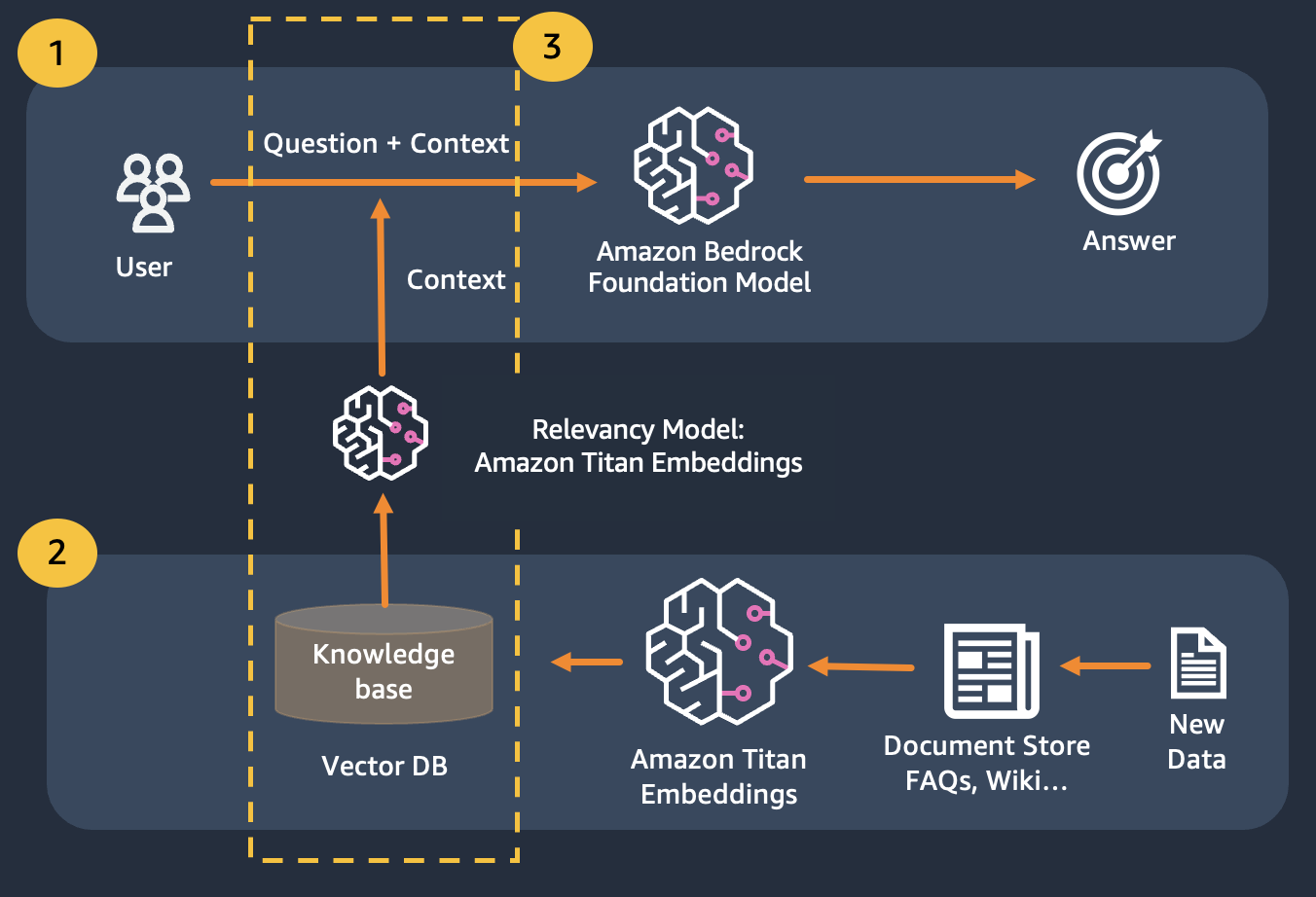
これは、検索拡張生成 (RAG) を使用することで解決できます。
RAG は、ナレッジ ベースを構築するためのドキュメントのコーパスにインデックスを付ける埋め込みの使用と、ナレッジ ベース内のドキュメントのサブセットから情報を抽出するための LLM の使用を組み合わせます。
RAG の準備ステップとして、ナレッジ ベースを構築するドキュメントは、固定サイズ (選択した埋め込みモデルの最大入力サイズに一致する) のチャンクに分割され、埋め込みベクトルを取得するためにモデルに渡されます。埋め込みは、ドキュメントの元のチャンクおよび追加のメタデータとともにベクター データベースに保存されます。ベクトル データベースは、ベクトル間の類似性検索を効率的に実行できるように最適化されています。
データ ストアがプライベートであるか、頻繁に変更される可能性があるデータ ストアをお持ちのお客様。 RAG アプローチは 2 つの問題を解決します。次のような課題を抱えているお客様は、このラボから恩恵を受けることができます。
このモジュールを完了すると、以下について十分に理解できるようになります。
このモジュールでは、Bedrock を使用して QA パターンを実装する方法を説明します。さらに、ベクター データベースにロードできる埋め込みも用意しました。
Titan エンベディングを使用してユーザーの質問のエンベディングを取得し、それらのエンベディングを使用してベクター データベースから最も関連性の高いドキュメントを取得し、上位 3 つのドキュメントを連結したプロンプトを構築し、Bedrock 経由で LLM モデルを呼び出すことができることに注意してください。