BeatLearning
1.0.0
お気に入りのリズム ゲームにはない曲をプレイしたいと思ったことはありませんか?その曲の無限のバリエーションを演奏したいと思ったことはありませんか?
このオープンソース研究プロジェクトは、ビートマップの自動作成プロセスを民主化し、ゲーム開発者、プレイヤー、愛好家に同様にアクセス可能なツールと基盤モデルを提供し、リズム ゲームにおける創造性と革新の新時代への道を開くことを目的としています。
例 (さらに近日公開予定):
まず Python 3.12 をインストールし、リポジトリのディレクトリに移動して、次の方法で仮想環境を作成する必要があります。
python3 -m venv venv
次に、 source venv/bin/activateまたは Windows マシンの場合はvenvScriptsactivate呼び出します。仮想環境がアクティブになったら、次の方法で必要なライブラリをインストールできます。
pip3 install -r requirements.txt
Jupyter を使用して、サンプルnotebooks/にアクセスできます。
jupyter notebook
利用可能な GPU インスタンスがある限り、Google Collab バージョンも試すことができます (デフォルトの CPU インスタンスでは、曲の変換に時間がかかります)。
パイプラインは現時点では OSU ビートマップのみをサポートしています。
このリポジトリはまだ作業中です。目標は、曲に関係なく、さまざまなリズム ゲームのビートマップを自動的に生成できる生成モデルを開発することです。この調査はまだ進行中ですが、目的はできるだけ早く MVP を取得することです。
すべての貢献は、特にトレーニング基盤モデルのためのコンピューティング寄付の形で評価されます。ご興味がございましたら、お気軽にご参加ください。
AI によるビートマップ生成の無限の可能性を探求し、リズム ゲームの未来を形作ることに参加してください。
モデルはHuggingFaceで入手できます。
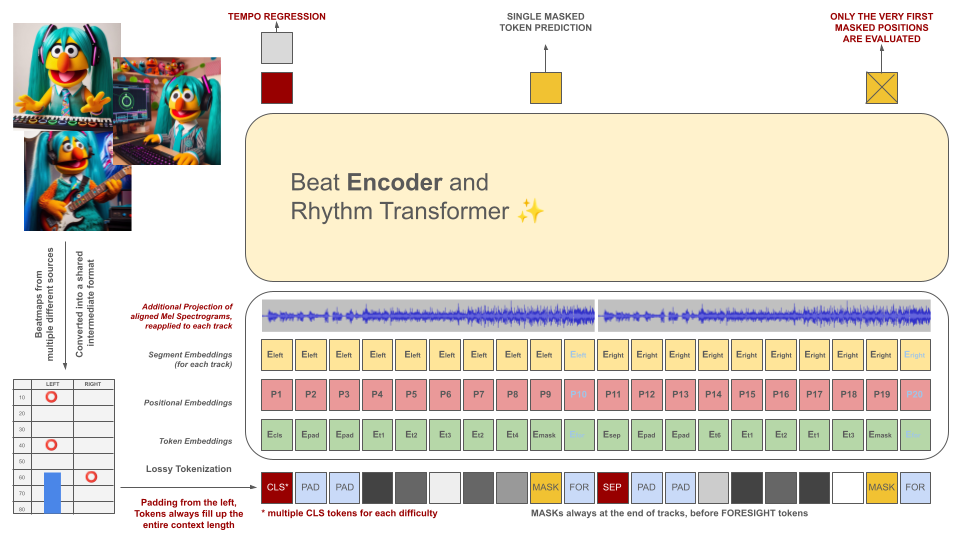
リズム ゲームのビートマップは最初に中間ファイル形式に変換され、その後 100 ミリ秒のチャンクにトークン化されます。各トークンは、10 ミリ秒の精度で量子化されたこの期間内 (ホールドおよび/またはヒット) で最大 2 つの異なるイベントをエンコードできます。トークナイザーの語彙は、この基準を満たすためにデータから学習されるのではなく、事前に計算されます。現場では質の高いトレーニング例が不足しているため、コンテキストの長さと語彙のサイズは意図的に小さく保たれています。
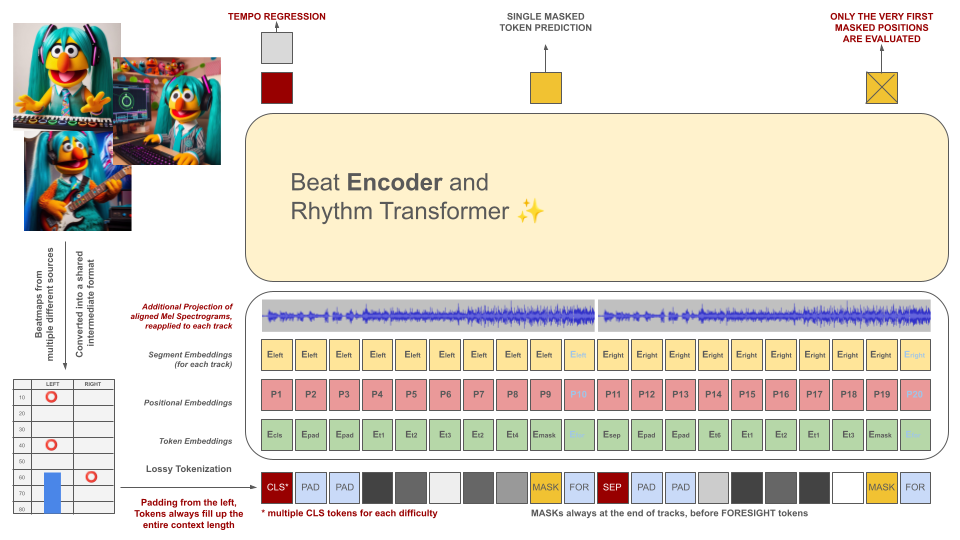 これらのトークンは、オーディオ データのスライス (トークンと位置合わせされた投影されたメル スペクトグラム) とともに、マスクされたエンコーダー モデルの入力として機能します。 BeRT と同様に、エンコーダー モデルにはトレーニング中に 2 つの目的があります。回帰タスクによるテンポの推定と、難聴関数によるマスクされた (次の) トークンの予測です。 1、2、および 4 トラックのビートマップがサポートされています。各トークンは、デコーダー アーキテクチャの生成プロセスを反映して、左から右に予測されます。ただし、マスクされたトークンは、右側の予見トークンとして示される、将来からの追加の音声情報にもアクセスできます。
これらのトークンは、オーディオ データのスライス (トークンと位置合わせされた投影されたメル スペクトグラム) とともに、マスクされたエンコーダー モデルの入力として機能します。 BeRT と同様に、エンコーダー モデルにはトレーニング中に 2 つの目的があります。回帰タスクによるテンポの推定と、難聴関数によるマスクされた (次の) トークンの予測です。 1、2、および 4 トラックのビートマップがサポートされています。各トークンは、デコーダー アーキテクチャの生成プロセスを反映して、左から右に予測されます。ただし、マスクされたトークンは、右側の予見トークンとして示される、将来からの追加の音声情報にもアクセスできます。
AI モデルの目的は、個別に作成されたビートマップの価値を下げることではなく、次のことです。
生成されたすべてのコンテンツはEU の規制に準拠し、AI モデルの関与を示すメタデータを含む適切なラベルを付ける必要があります。
著作権で保護された素材のビートマップの生成は固く禁止されています。自分が権利を持っている曲のみを使用してください。
OSU ファイルの例で紹介されているオーディオは、OSU Web サイトの「特集アーティスト」セクションにリストされているアーティストからのものであり、特に osu! 関連のコンテンツでの使用が許可されています。
今後、ビートマップがトレーニング データとして利用されないようにするには、ビートマップ ファイルに次のメタデータを含めます。
robots: disallow
このプロジェクトは、AIOSU として知られる以前の試みからインスピレーションを得ています。
OSU の wiki に依存することに加えて、osu-parser はビートマップ宣言 (特にスライダー) を明確にするのに役立ちました。トランスフォーマー モデルは、NanoGPT と BeRT の pytorch 実装の影響を受けました。