stellar metrics
1.0.0
論文のコード: Stellar: 人間中心のパーソナライズされたテキストから画像への手法の系統的評価
著者: パノス・アクリプタス、アレクサンドロス・ベネタトス、ヨルダニス・フォスティロプロス、ディミトリス・スクルティス
コードベースは Iordanis Fostiropoulos によって保守されています。ご質問がございましたら、お問い合わせください。
このリポジトリ内のコードの一部をダウンロードまたは使用する前に、このリポジトリに含まれる「ライセンス条項」と「サードパーティ ライセンス条項」の両方に記載されている条項を確認し、同意してください。このリポジトリ内のコードの一部をダウンロードして使用し続けると、これらの利用規約に同意したことになります。
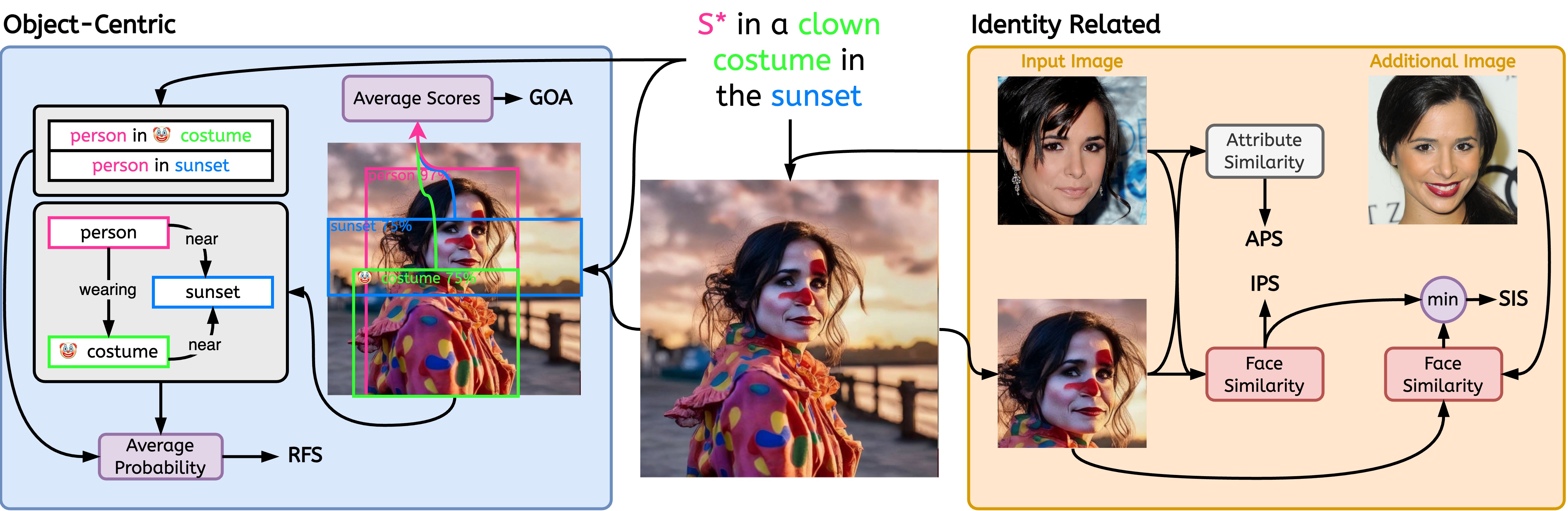 注: 表示されている「入力画像」と「追加画像」は CELEBMaksHQ データセットにあります。
注: 表示されている「入力画像」と「追加画像」は CELEBMaksHQ データセットにあります。
この研究は、当社の技術原稿「Stellar: Systematic Evaluation of Human-Centric Personalized Text-to-Image Methods」に基づいています。人間中心のパーソナライゼーション Text-2-Image モデルを評価するための 5 つの指標を提案しました。リポジトリは、Text-2-Image および Image-2-Image メソッド用の 8 つの追加のベースライン メトリクスの実装を提供します。
文献から提供される指標がいくつかあります。私たちの作品で紹介されたものと表記します。
当社は既存のメトリクスの独自の実装を提供し、ユーザーの作業の技術的な詳細については論文を参照するよう案内します。
| 名前 | 評価タイプ | コードネーム | 参照 |
|---|---|---|---|
| エース。 | 画像2画像 | aesth | リンク |
| 画像2画像 | clip | リンク | |
| ドリームシム | 画像2画像 | dreamsim | リンク |
| テキスト2画像 | clip | リンク | |
| HPSv1 | テキスト2画像 | hps | リンク |
| HPSv2 | テキスト2画像 | hps | リンク |
| 画像報酬 | テキスト2画像 | im_reward | リンク |
| ピックスコア | テキスト2画像 | pick | リンク |
| APS | パーソナライズされたテキスト 2 イメージ | aps | リンク |
| ゴア | オブジェクト中心 | goa | リンク |
| IPS | パーソナライズされたテキスト 2 イメージ | ips | リンク |
| 関係中心 | rfs | リンク | |
| SIS | パーソナライズされたテキスト 2 イメージ | sis | リンク |
pip install git+https://github.com/stellar-gen-ai/stellar-metrics.git個々の画像のメトリクスを計算したいと考えています。したがって、メソッドの失敗ケースを診断するのに役立ちます。
$ python -m stellar_metrics --metric code_name --stellar-path ./stellar-dataset --syn-path ./model-output --save-dir ./save-dirオプションで、バックボーンに--device 、 --batch-size 、および--clip-version指定できます。
モデル出力と恒星データセットの間には 1 対 1 の対応関係がなければならないことに注意してください。 stellar-dataset元の画像が必要な場合のアイデンティティの保存など、いくつかのメトリクスを計算するために使用されます。 syn-pathとstellar-pathの間の設定が間違っていると、誤った結果が生じる可能性があります。
IPSを計算する
$ python -m stellar_metrics --metric ips --stellar-path ./tests/assets/mock_stellar_dataset --syn-path ./tests/assets/stellar_net --save-dir ./save-dirクリップを計算する
$ python -m stellar_metrics --metric clip --stellar-path ./tests/assets/mock_stellar_dataset --syn-path ./tests/assets/stellar_net --save-dir ./save-dir$ python -m stellar_metrics.analysis --save-dir ./save-dirかなり大まかだが専門的な方法で、入力されたアイデンティティと生成された画像の間の顔の類似性を評価します。私たちのメトリックでは、顔検出器を使用して、入力画像と生成画像の両方で ID の顔を分離します。次に、特殊な顔検出モデルを使用して、検出された領域から顔表現の埋め込みを抽出します。
生成された画像が、年齢、性別、その他の不変の顔の特徴 (例: 高い頬骨) など、問題となっているアイデンティティの特定の詳細な属性をどの程度維持しているかを評価します。 Stellar 画像の注釈を活用して、これらの二値の顔の特徴を評価できます。
同じ個人の異なる画像に対するモデルの感度の程度を決定するための尺度として機能します。さらに、入力画像の無関係な変動(照明条件、被写体のポーズなど) に関係なく、被写体のアイデンティティが一貫して適切に捕捉されるモデルを促進します。
この目標を達成するには、 SIS人間の被写体の複数の画像にアクセスする必要があります (この条件は、Stellar のデータセットで設計により満たされています)。これは、このようなより厳しい要件を持つ唯一の評価指標です。
画像とプロンプトの間の調整に関する 2 つの重要な側面を評価するための、専門的で解釈可能なメトリクスを導入します。オブジェクト表現の忠実さと描写された関係の忠実さ。
生成された画像上で目的のプロンプト オブジェクト インタラクションを表現できるかどうかを評価します。特殊なシーン グラフ生成 (SGG) モデルであっても視覚的な関係を理解することは困難であることを考慮すると、このメトリクスは、プロンプトされた関係を忠実に描写するパーソナライズされたモデルの能力について局所的な貴重な洞察をもたらします。


