BinaryVectorDB
1.0.0
このリポジトリには、教育目的を目的とした大規模なデータセットを効率的に検索するためのバイナリ ベクトル データベースが含まれています。
ほとんどの埋め込みモデルはベクトルを float32 として表します。これらは大量のメモリを消費し、検索は非常に遅くなります。 Cohere では、ネイティブ int8 とバイナリ サポートを備えた最初の埋め込みモデルを導入しました。これにより、わずかなコストで優れた検索品質が得られます。
| モデル | 検索品質 MIRACL | 100 万件のドキュメントを検索する時間 | 必要なメモリ 250M ウィキペディアの埋め込み | AWS での価格 (x2GB インスタンス) |
|---|---|---|---|---|
| OpenAI テキスト埋め込み-3-small | 44.9 | 680ミリ秒 | 1431GB | 65,231ドル/年 |
| OpenAI テキスト埋め込み-3-large | 54.9 | 1240ミリ秒 | 2861GB | 130,463 ドル / 年 |
| Cohere Embed v3 (多言語) | ||||
| 埋め込み v3 - float32 | 66.3 | 460ミリ秒 | 954GB | $43,488/年 |
| 埋め込み v3 - バイナリ | 62.8 | 24ミリ秒 | 30GB | 1,359ドル/年 |
| 埋め込み v3 - バイナリ + int8 スコア | 66.3 | 28ミリ秒 | 30 GB メモリ + 240 GB ディスク | 1,589ドル/年 |
月額わずか 15 ドルで VM の 1 億の Wikipedia 埋め込みを検索できるデモを作成しました: デモ - 月額わずか 15 ドルで 1 億の Wikipedia 埋め込みを検索
BinaryVectorDB を独自のデータに対して簡単に使用できます。
セットアップは簡単です:
pip install BinaryVectorDB
以下の例の一部を使用するには、cohere.com からCohere API キー(無料または有料) が必要です。この API キーを環境変数として設定する必要があります: export COHERE_API_KEY=your_api_key
独自のデータに基づいてベクトル DB を構築する方法については後ほど説明します。まず、事前に構築されたバイナリ ベクトル データベースを使用してみましょう。 https://huggingface.co/datasets/Cohere/BinaryVectorDB でさまざまな事前構築データベースをホストしています。これらをダウンロードしてローカルで使用できます。
まずは、Wikipedia の簡単な英語版を見てみましょう。
wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/wikipedia-2023-11-simple.zip
そして、このファイルを解凍します。
unzip wikipedia-2023-11-simple.zip
前の手順で解凍したフォルダーを指定することで、データベースを簡単にロードできます。
from BinaryVectorDB import BinaryVectorDB
# Point it to the unzipped folder from the previous step
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db = BinaryVectorDB ( "wikipedia-2023-11-simple/" )
query = "Who is the founder of Facebook"
print ( "Query:" , query )
hits = db . search ( query )
for hit in hits [ 0 : 3 ]:
print ( hit )データベースには 646,424 個の埋め込みがあり、合計サイズは 962 MB です。ただし、バイナリ埋め込み用の 80 MB だけがメモリにロードされます。ドキュメントとその int8 埋め込みはディスク上に保存され、必要なときにロードされるだけです。
メモリ内のバイナリ エンベディングとディスク上の int8 エンベディングとドキュメントを分割することで、大量のメモリを必要とせずに非常に大規模なデータセットに拡張できるようになります。
独自のバイナリ ベクトル データベースを構築するのは非常に簡単です。
from BinaryVectorDB import BinaryVectorDB
import os
import gzip
import json
simplewiki_file = "simple-wikipedia-example.jsonl.gz"
#If file not exist, download
if not os . path . exists ( simplewiki_file ):
cmd = f"wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/simple-wikipedia-example.jsonl.gz"
os . system ( cmd )
# Create the vector DB with an empty folder
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db_folder = "path_to_an_empty_folder/"
db = BinaryVectorDB ( db_folder )
if len ( db ) > 0 :
exit ( f"The database { db_folder } is not empty. Please provide an empty folder to create a new database." )
# Read all docs from the jsonl.gz file
docs = []
with gzip . open ( simplewiki_file ) as fIn :
for line in fIn :
docs . append ( json . loads ( line ))
#Limit it to 10k docs to make the next step a bit faster
docs = docs [ 0 : 10_000 ]
# Add all documents to the DB
# docs2text defines a function that maps our documents to a string
# This string is then embedded with the state-of-the-art Cohere embedding model
db . add_documents ( doc_ids = list ( range ( len ( docs ))), docs = docs , docs2text = lambda doc : doc [ 'title' ] + " " + doc [ 'text' ])ドキュメントには、任意の Python シリアル化可能なオブジェクトを指定できます。ドキュメントを文字列にマップする関数をdocs2textに提供する必要があります。上の例では、タイトルとテキストフィールドを連結しています。この文字列は埋め込みモデルに送信され、必要なテキスト埋め込みが生成されます。
ドキュメントの追加/削除/更新は簡単です。データベース内のドキュメントを追加/更新/削除するサンプル スクリプトについては、examples/add_update_delete.py を参照してください。
私たちは、必要なメモリを 4 倍および 32 倍削減できる Cohere int8 およびバイナリ エンベディングの埋め込みを発表しました。さらに、ベクトル検索が最大 40 倍高速化されます。
両方の手法が BinaryVectorDB で組み合わされます。例として、4,200 万個の埋め込みがある英語版 Wikipedia を想定してみましょう。通常の float32 埋め込みでは、埋め込みをホストするだけで42*10^6*1024*4 = 160 GBのメモリが必要になります。 float32 での検索はかなり遅いため (42M 埋め込みで約 45 秒)、HNSW のようなインデックスを追加する必要があります。これによりさらに 20 GB のメモリが追加されるため、合計 180 GB が必要になります。
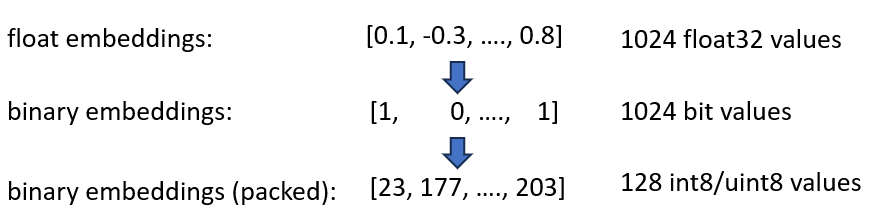
バイナリ埋め込みは、すべての次元を 1 ビットとして表します。これにより、必要なメモリが160 GB / 32 = 5GBに削減されます。また、バイナリ空間での検索は 40 倍高速になるため、多くの場合、HNSW インデックスは必要なくなります。必要なメモリが 180 GB から 5 GB に減り、36 分の 1 の大幅な節約になります。
このインデックスをクエリするときは、クエリもバイナリでエンコードし、ハミング距離を使用します。ハミング距離は、2 つのベクトル間の 1 ビットの差を測定します。これは非常に高速な操作です。2 つのバイナリ ベクトルを比較するには、 popcount(xor(vector1, vector2))のように 2 CPU サイクルだけが必要です。 XOR は CPU 上で最も基本的な演算であるため、非常に高速に実行されます。 popcountレジスタ内の 1 の数をカウントします。これにも 1 CPU サイクルしか必要としません。
全体として、これにより、検索品質の約 90% を維持するソリューションが得られます。
<float, binary>の再スコアリングにより、前のステップの検索品質を 90% から 95% に高めることができます。
たとえば、ステップ 1 の上位 100 位の結果を取得し、 dot_product(query_float_embedding, 2*binary_doc_embedding-1)を計算します。
クエリの埋め込みが[0.1, -0.3, 0.4]で、バイナリ ドキュメントの埋め込みが[1, 0, 1]であると仮定します。次に、このステップでは以下が計算されます。
(0.1)*(1) + (-0.3)*(-1) + 0.4*(1) = 0.1 + 0.3 + 0.4 = 0.8

これらのスコアを使用して結果を再採点します。これにより、検索品質が 90% から 95% に向上します。この操作は非常に迅速に実行できます。埋め込みモデルからクエリ浮動小数点数埋め込みを取得し、バイナリ埋め込みはメモリ内にあるため、100 回の合計演算を実行するだけで済みます。
検索品質を 95% から 99.99% にさらに向上させるために、ディスクからの int8 再スコアリングを使用します。
すべての int8 ドキュメントの埋め込みをディスクに保存します。上記のステップから上位 30 を取得し、ディスクから int8-embedding をロードし、 cossim(query_float_embedding, int8_doc_embedding_from_disk)を計算します。
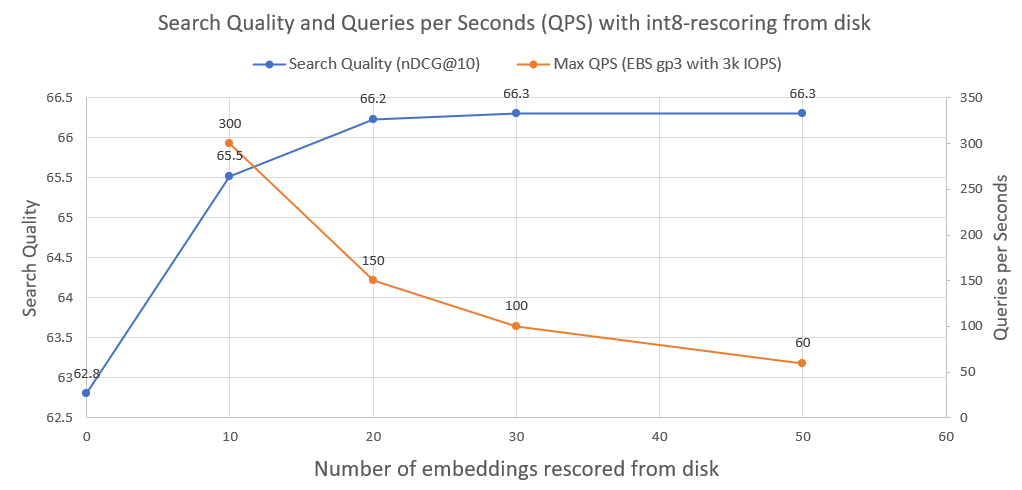
次の画像では、int8 スコアリングと検索パフォーマンスの向上の程度を確認できます。
また、このようなシステムが 3000 IOPS の通常の AWS EBS ネットワーク ドライブで実行された場合に達成できる 1 秒あたりのクエリ数もプロットしました。ご覧のとおり、ディスクからロードする必要がある int8 エンベディングが増えるほど、QPS は少なくなります。
二分検索を実行するには、faiss の IndexBinaryFlat インデックスを使用します。バイナリの埋め込みを保存するだけで、超高速のインデックス作成と超高速の検索が可能になります。
ドキュメントと int8 埋め込みを保存するには、RocksDB に基づく Python 用のディスク上のキーと値のストレージである RocksDict を使用します。
クラスの完全な実装については、「BinaryVectorDB」を参照してください。
あまり。このリポジトリは主に、大規模なデータセットに拡張する方法を示すための教育目的を目的としています。使いやすさに重点が置かれており、マルチプロセスの安全性、ロールバックなど、いくつかの重要な側面が実装に欠けています。
実際に運用を開始したい場合は、同様の結果を達成できる Vespa.ai などの適切なベクター データベースを使用してください。
Cohere では、お客様が数分の 1 のコストで数百億の埋め込みに対してセマンティック検索を実行できるよう支援しました。拡張性のあるソリューションが必要な場合は、お気軽に Nils Reimers までお問い合わせください。


