horovod
v0.28.1: Build fixes (ROCm, GCC 12)
Horovod は、TensorFlow、Keras、PyTorch、および Apache MXNet 用の分散ディープラーニング トレーニング フレームワークです。 Horovod の目標は、分散ディープラーニングを高速かつ簡単に使用できるようにすることです。
Horovod は、LF AI & Data Foundation (LF AI & Data) によってホストされています。人工知能、機械、深層学習におけるオープンソース テクノロジーの使用に熱心に取り組んでいる企業で、これらの分野のオープンソース プロジェクトのコミュニティをサポートしたい場合は、LF AI & Data Foundation への参加を検討してください。誰が関与しているのか、Horovod がどのような役割を果たしているのかについて詳しくは、Linux Foundation の発表をご覧ください。
コンテンツ
このプロジェクトの主な動機は、単一 GPU のトレーニング スクリプトを簡単に取得し、それを適切に拡張して多数の GPU で並行してトレーニングできるようにすることです。これには次の 2 つの側面があります。
Uber 内部では、MPI モデルがはるかに単純で、パラメーター サーバーを使用した分散 TensorFlow などの以前のソリューションよりもはるかに少ないコード変更が必要であることがわかりました。 Horovod を使用してトレーニング スクリプトを大規模に作成したら、コードをさらに変更することなく、単一 GPU、複数 GPU、さらには複数のホスト上で実行できます。詳細については、「使用法」セクションを参照してください。
Horovod は使いやすいだけでなく、高速です。以下は、RoCE 対応の 25 Gbit/s ネットワークで接続された 4 Pascal GPU を搭載した 128 台のサーバーで実行されたベンチマークを表すグラフです。
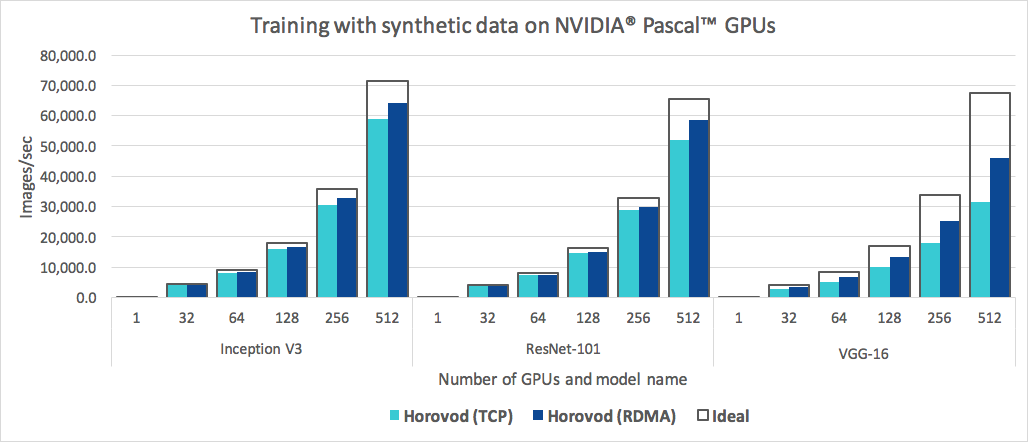
Horovod は、Inception V3 と ResNet-101 の両方で 90% のスケーリング効率を達成し、VGG-16 では 68% のスケーリング効率を達成します。これらの数値を再現する方法については、「ベンチマーク」を参照してください。
MPI と NCCL のインストール自体は余分な手間のように思えるかもしれませんが、インフラストラクチャを扱うチームが一度行うだけで済むため、モデルを構築する社内の他の全員が簡単に大規模にトレーニングできることを実感できます。
Linux または macOS に Horovod をインストールするには:
PyPI から TensorFlow をインストールした場合は、 g++-5以降がインストールされていることを確認してください。 TensorFlow 2.10 以降では、 g++8以降のような C++17 準拠のコンパイラが必要になります。
PyPI から PyTorch をインストールした場合は、 g++-5以降がインストールされていることを確認してください。
Conda からいずれかのパッケージをインストールした場合は、 gxx_linux-64 Conda パッケージがインストールされていることを確認してください。
horovod pip パッケージをインストールします。
CPU で実行するには:
$ pip install horovodNCCL を使用して GPU で実行するには:
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovodGPU サポートを使用した Horovod のインストールの詳細については、「GPU での Horovod」を参照してください。
Horovod インストール オプションの完全なリストについては、インストール ガイドを参照してください。
MPI を使用する場合は、「MPI を使用した Horovod」を参照してください。
Conda を使用する場合は、「Horovod の GPU サポートを備えた Conda 環境の構築」を参照してください。
Docker を使用したい場合は、「Docker の Horovod」をお読みください。
Horovod をソースからコンパイルするには、コントリビューター ガイドの手順に従ってください。
Horovod の中心原則は、サイズ、ランク、ローカル ランク、 allreduce 、 allgather 、 broadcast 、 alltoallなどの MPI 概念に基づいています。詳細については、このページを参照してください。
Horovod の例とベスト プラクティスについては、次のページを参照してください。
Horovod を使用するには、プログラムに次の追加を行います。
hvd.init()を実行して Horovod を初期化します。リソースの競合を避けるために、各 GPU を単一のプロセスに固定します。
プロセスごとに 1 つの GPU を設定する一般的な設定では、これをローカル ランクに設定します。サーバー上の最初のプロセスには最初の GPU が割り当てられ、2 番目のプロセスには 2 番目の GPU が割り当てられ、以下同様になります。
ワーカー数に応じて学習率を調整します。
同期分散トレーニングにおける有効なバッチ サイズは、ワーカーの数によって決まります。学習率の増加により、バッチサイズの増加が補われます。
オプティマイザーをhvd.DistributedOptimizerでラップします。
分散オプティマイザーは勾配の計算を元のオプティマイザーに委任し、 allreduceまたはallgather を使用して勾配を平均化し、それらの平均化された勾配を適用します。
初期変数状態をランク 0 から他のすべてのプロセスにブロードキャストします。
これは、トレーニングがランダムな重みで開始されるとき、またはチェックポイントから復元されるときに、すべてのワーカーの一貫した初期化を保証するために必要です。
TensorFlow v1 を使用した例 (完全なトレーニング例については、サンプル ディレクトリを参照してください):
import tensorflow as tf
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf . ConfigProto ()
config . gpu_options . visible_device_list = str ( hvd . local_rank ())
# Build model...
loss = ...
opt = tf . train . AdagradOptimizer ( 0.01 * hvd . size ())
# Add Horovod Distributed Optimizer
opt = hvd . DistributedOptimizer ( opt )
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [ hvd . BroadcastGlobalVariablesHook ( 0 )]
# Make training operation
train_op = opt . minimize ( loss )
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd . rank () == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf . train . MonitoredTrainingSession ( checkpoint_dir = checkpoint_dir ,
config = config ,
hooks = hooks ) as mon_sess :
while not mon_sess . should_stop ():
# Perform synchronous training.
mon_sess . run ( train_op )以下のコマンド例は、分散トレーニングを実行する方法を示しています。 RoCE/InfiniBand の調整やハングに対処するためのヒントなど、詳細については「Horovod の実行」を参照してください。
4 つの GPU を備えたマシンで実行するには:
$ horovodrun -np 4 -H localhost:4 python train.pyそれぞれ 4 つの GPU を備えた 4 台のマシンで実行するには:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py horovodrunラッパーを使用せずに Open MPI を使用して実行するには、「Open MPI を使用した Horovod の実行」を参照してください。
Docker で実行するには、「Docker の Horovod」を参照してください。
Kubernetes で実行するには、Helm Chart、Kubeflow MPI Operator、FfDL、および Polyaxon を参照してください。
Spark で実行するには、「Spark 上の Horovod」を参照してください。
Ray 上で実行するには、「Ray 上の Horovod」を参照してください。
Singularity で実行するには、「Singularity」を参照してください。
LSF HPC クラスター (Summit など) で実行するには、「LSF」を参照してください。
Hadoop Yarn で実行するには、TonY を参照してください。
Gloo は、Facebook によって開発されたオープンソースの集合コミュニケーション ライブラリです。
Gloo は Horovod に含まれており、ユーザーは MPI をインストールしなくても Horovod を実行できます。
MPI と Gloo の両方をサポートしている環境の場合、 --gloo引数をhorovodrunに渡すことで、実行時に Gloo を使用することを選択できます。
$ horovodrun --gloo -np 2 python train.pyHorovod は、MPI がマルチスレッド サポートで構築されている場合に限り、Horovod コレクティブと mpi4py などの他の MPI ライブラリとの混合と一致をサポートします。
hvd.mpi_threads_supported()関数をクエリすることで、MPI マルチスレッド サポートを確認できます。
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Verify that MPI multi-threading is supported.
assert hvd . mpi_threads_supported ()
from mpi4py import MPI
assert hvd . size () == MPI . COMM_WORLD . Get_size ()mpi4py サブコミュニケーターを使用して Horovod を初期化することもできます。その場合、各サブコミュニケーターは独立した Horovod トレーニングを実行します。
from mpi4py import MPI
import horovod . tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI . COMM_WORLD . Split ( color = MPI . COMM_WORLD . rank % 2 ,
key = MPI . COMM_WORLD . rank )
# Initialize Horovod
hvd . init ( comm = subcomm )
print ( 'COMM_WORLD rank: %d, Horovod rank: %d' % ( MPI . COMM_WORLD . rank , hvd . rank ()))推論用にモデルを最適化し、グラフから Horovod 操作を削除する方法については、こちらをご覧ください。
Horovod のユニークな点の 1 つは、通信と計算をインターリーブする機能と、小規模なallreduce操作をバッチ処理する機能とを組み合わせることで、パフォーマンスが向上することです。このバッチ機能を Tensor Fusion と呼びます。
詳細と調整手順については、ここを参照してください。
Horovod には、Horovod タイムラインと呼ばれるアクティビティのタイムラインを記録する機能があります。
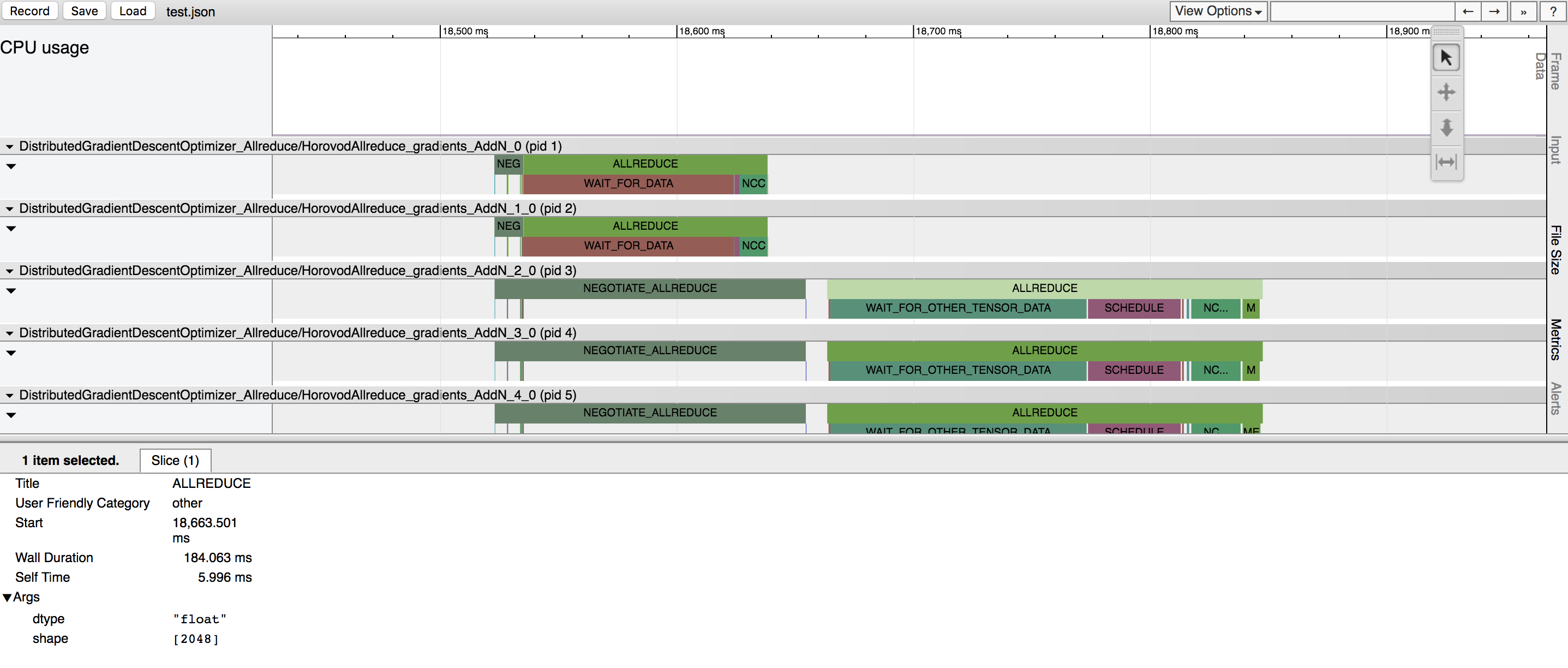
Horovod タイムラインを使用して Horovod のパフォーマンスを分析します。詳細と使用手順については、こちらをご覧ください。
Tensor Fusion やその他の高度な Horovod 機能を効率的に利用するために適切な値を選択するには、かなりの量の試行錯誤が必要になる場合があります。私たちは、 autotuningと呼ばれるこのパフォーマンス最適化プロセスを自動化するシステムを提供しています。これは、 horovodrunへの単一のコマンド ライン引数で有効にできます。
詳細と使用手順については、こちらをご覧ください。
Horovod を使用すると、1 つの分散トレーニングに参加するプロセスの異なるグループで個別の集合操作を同時に実行できます。この機能を利用するには、 hvd.process_setオブジェクトを設定します。
詳細な手順については、「プロセス セット」を参照してください。
このサイトで公開したいユーザー ガイドへのリンクを送信してください
解決策が見つからない場合は、「トラブルシューティング」を参照してチケットを送信してください。
あなたの研究に役立つ場合は、出版物の中で Horovod を引用してください。
@article{sergeev2018horovod、
著者 = {アレクサンダー・セルゲイエフとマイク・デル・バルソ}、
ジャーナル = {arXiv プレプリント arXiv:1802.05799}、
Title = {Horovod: {TensorFlow} での高速かつ簡単な分散ディープラーニング},
年 = {2018}
}
1. Sergeev, A.、Del Bsolve, M. (2017) Horovod の紹介: TensorFlow 用の Uber のオープンソース分散深層学習フレームワーク。 https://eng.uber.com/horovod/ から取得
2. Sergeev, A. (2017) Horovod - 分散 TensorFlow を簡単に。 https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy から取得
3. Sergeev, A.、Del Bsolve, M. (2018) Horovod: TensorFlow での高速かつ簡単な分散ディープラーニング。 arXiv から取得:1802.05799
Horovod のソース コードは、Andrew Gibiansky と Joel Hestness によって書かれた Baidu tensorflow-allreduce リポジトリに基づいています。彼らのオリジナルの成果は、深層学習に HPC 技術を導入するという記事で説明されています。


