alibi
v0.9.6

Alibi は、機械学習モデルの検査と解釈を目的とした Python ライブラリです。このライブラリの焦点は、分類および回帰モデルのブラック ボックス、ホワイト ボックス、ローカルおよびグローバルの説明方法の高品質な実装を提供することです。
外れ値の検出、概念ドリフト、または敵対的インスタンスの検出に興味がある場合は、姉妹プロジェクトの alibi-detect をチェックしてください。
画像のアンカー説明  | テキストの統合されたグラデーション  |
反事実の例 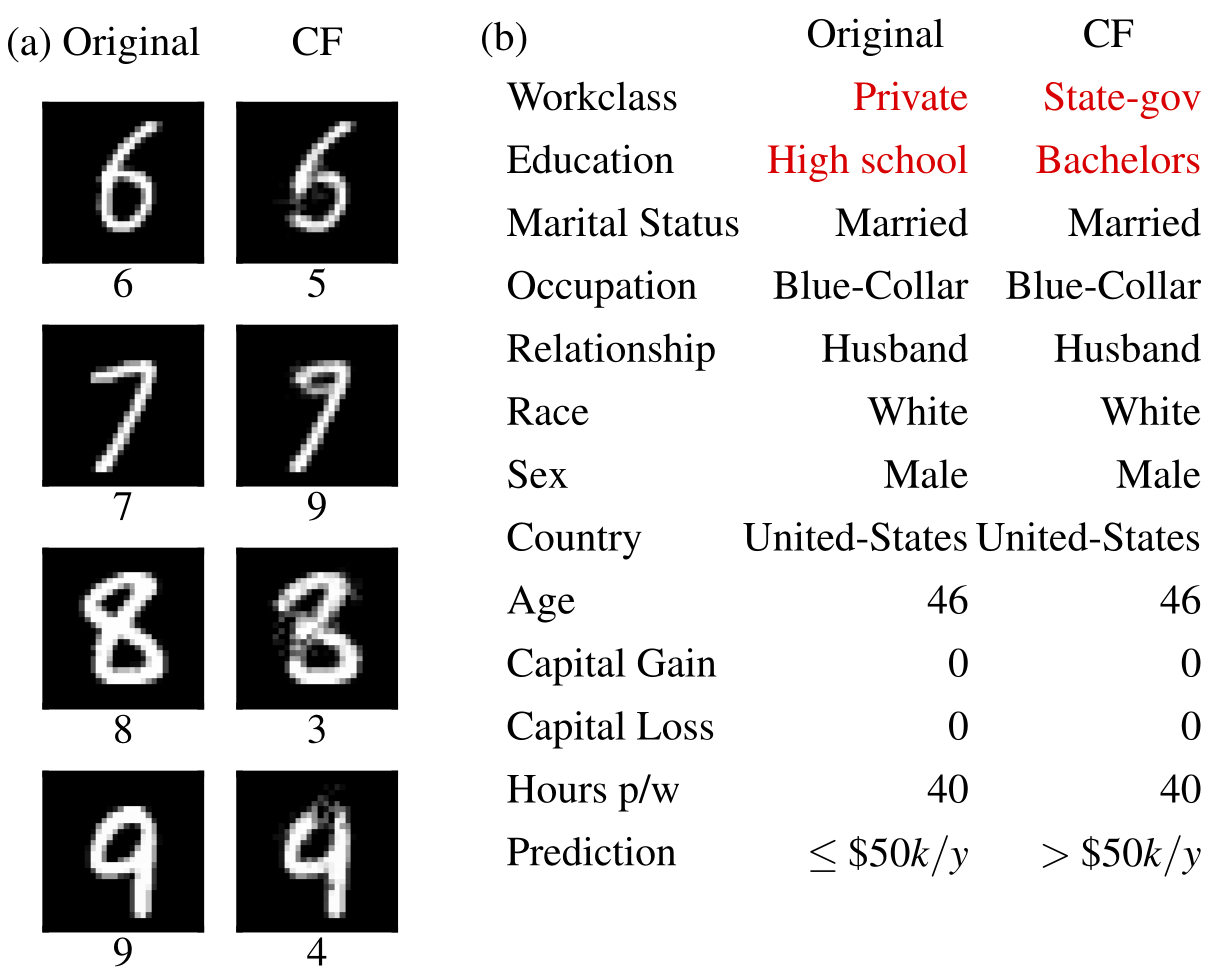 | 蓄積された局所効果 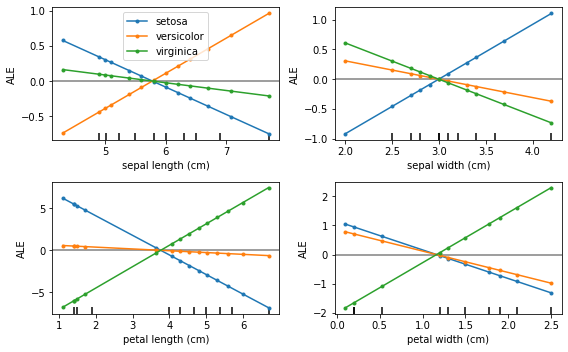 |
Alibi は以下からインストールできます。
pipを使用)conda / mamba付き)Alibi は PyPI からインストールできます。
pip install alibiあるいは、開発バージョンをインストールすることもできます。
pip install git+https://github.com/SeldonIO/alibi.git 説明の分散計算を利用するには、 rayを使用してalibiインストールします。
pip install alibi[ray] SHAP をサポートするには、次のようにalibiをインストールします。
pip install alibi[shap]conda-forge からインストールするには、mamba を使用することをお勧めします。これは、以下を使用して基本conda 環境にインストールできます。
conda install mamba -n base -c conda-forge標準の Alibi インストールの場合:
mamba install -c conda-forge alibi分散コンピューティングのサポートの場合:
mamba install -c conda-forge alibi raySHAP サポートの場合:
mamba install -c conda-forge alibi shapアリバイ説明 API はscikit-learnからインスピレーションを得ており、個別の初期化、適合、および説明のステップで構成されます。 AnchorTabular の説明を使用して API を説明します。
from alibi . explainers import AnchorTabular
# initialize and fit explainer by passing a prediction function and any other required arguments
explainer = AnchorTabular ( predict_fn , feature_names = feature_names , category_map = category_map )
explainer . fit ( X_train )
# explain an instance
explanation = explainer . explain ( x )返される説明は、属性metaおよびdataを持つExplanationオブジェクトです。 metaは、Explainer メタデータとハイパーパラメータを含むディクショナリであり、 data計算された説明に関連するすべてを含むディクショナリです。たとえば、アンカー アルゴリズムの場合、説明にはexplanation.data['anchor'] (またはexplanation.anchor ) を介してアクセスできます。利用可能なフィールドの正確な詳細はメソッドごとに異なるため、サポートされているメソッドの種類についてよく理解しておくことをお勧めします。
次の表は、各メソッドの考えられる使用例をまとめたものです。
| 方法 | モデル | 説明 | 分類 | 回帰 | 表形式 | 文章 | 画像 | カテゴリ特徴 | 列車セットが必要です | 分散型 |
|---|---|---|---|---|---|---|---|---|---|---|
| エール | BB | グローバル | ✔ | ✔ | ✔ | |||||
| 部分的な依存 | BBWB | グローバル | ✔ | ✔ | ✔ | ✔ | ||||
| PD分散 | BBWB | グローバル | ✔ | ✔ | ✔ | ✔ | ||||
| 順列の重要性 | BB | グローバル | ✔ | ✔ | ✔ | ✔ | ||||
| アンカー | BB | 地元 | ✔ | ✔ | ✔ | ✔ | ✔ | 表形式の場合 | ||
| CEM | BB* TF/ケラス | 地元 | ✔ | ✔ | ✔ | オプション | ||||
| 反事実 | BB* TF/ケラス | 地元 | ✔ | ✔ | ✔ | いいえ | ||||
| プロトタイプの反事実 | BB* TF/ケラス | 地元 | ✔ | ✔ | ✔ | ✔ | オプション | |||
| RL による反事実 | BB | 地元 | ✔ | ✔ | ✔ | ✔ | ✔ | |||
| 統合されたグラデーション | TF/ケラス | 地元 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | オプション | |
| カーネルSHAP | BB | 地元 グローバル | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||
| ツリーSHAP | WB | 地元 グローバル | ✔ | ✔ | ✔ | ✔ | オプション | |||
| 類似性の説明 | WB | 地元 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
これらのアルゴリズムは、特定の予測を行うためのモデルの信頼度を測定するインスタンス固有のスコアを提供します。
| 方法 | モデル | 分類 | 回帰 | 表形式 | 文章 | 画像 | カテゴリ特徴 | 列車セットが必要です |
|---|---|---|---|---|---|---|---|---|
| トラストスコア | BB | ✔ | ✔ | ✔(1) | ✔(2) | はい | ||
| 直線性の測定 | BB | ✔ | ✔ | ✔ | ✔ | オプション |
鍵:
これらのアルゴリズムは、データセットの抽出されたビューを提供し、1-KNN解釈可能な分類器の構築に役立ちます。
| 方法 | 分類 | 回帰 | 表形式 | 文章 | 画像 | カテゴリ特徴 | 列車セットのラベル |
|---|---|---|---|---|---|---|---|
| プロトセレクト | ✔ | ✔ | ✔ | ✔ | ✔ | オプション |
蓄積された局所効果 (ALE、Apley および Zhu、2016)
部分依存 (JH フリードマン、2001)
部分依存分散(Greenwell et al., 2018)
順列の重要性(Breiman、2001; Fisher et al.、2018)
アンカーの説明 (Ribeiro et al., 2018)
対比説明法 (CEM、Dhurandhar et al.、2018)
反事実の説明 (Wachter et al., 2017 の拡張)
プロトタイプに導かれた反事実的説明 (Van Looveren and Klaise、2019)
RL によるモデルに依存しない反事実の説明 (Samoilescu et al., 2021)
統合された勾配 (Sundararajan et al.、2017)
カーネル Shapley 添加剤の説明 (Lundberg et al.、2017)
Tree Shapley 添加剤の説明 (Lundberg et al.、2020)
トラストスコア (Jiang et al., 2018)
直線性の測定
プロトセレクト
類似性の説明
研究でアリバイを使用する場合は、それを引用することを検討してください。
BibTeX エントリ:
@article{JMLR:v22:21-0017,
author = {Janis Klaise and Arnaud Van Looveren and Giovanni Vacanti and Alexandru Coca},
title = {Alibi Explain: Algorithms for Explaining Machine Learning Models},
journal = {Journal of Machine Learning Research},
year = {2021},
volume = {22},
number = {181},
pages = {1-7},
url = {http://jmlr.org/papers/v22/21-0017.html}
}


