SWE bench
1.0.0

| 日本語 |英語 | 中文简体 | 繁体字中国語 |
ICLR 2024 論文 SWE ベンチのコードとデータ: 言語モデルは現実世界の GitHub の問題を解決できますか?
SWE ベンチ ベンチマークの最新の更新情報については、公開リーダーボードと変更ログについては Web サイトを参照してください。
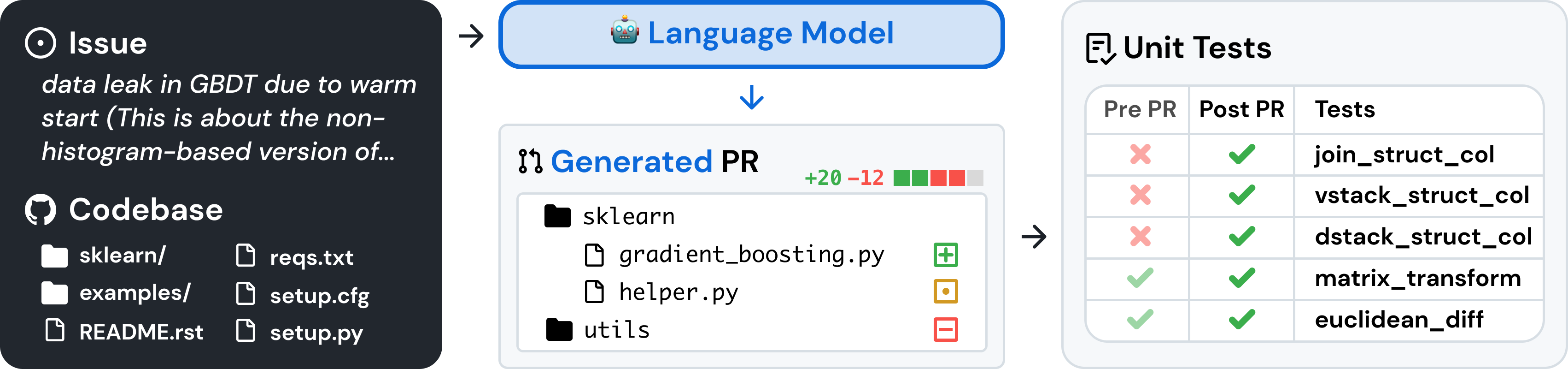
SWE ベンチは、GitHub から収集された現実世界のソフトウェアの問題に関する大規模な言語モデルを評価するためのベンチマークです。コードベースと問題が与えられると、言語モデルは、記述された問題を解決するパッチを生成するタスクを負います。
SWE ベンチにアクセスするには、次のコードをコピーして実行します。
from datasets import load_dataset
swebench = load_dataset ( 'princeton-nlp/SWE-bench' , split = 'test' )SWE-bench は、再現可能な評価のために Docker を使用します。 Docker セットアップ ガイドの指示に従って、Docker をマシンにインストールします。 Linux でセットアップしている場合は、インストール後の手順も参照することをお勧めします。
最後に、ソースから SWE ベンチを構築するには、次の手順に従います。
git clone [email protected]:princeton-nlp/SWE-bench.git
cd SWE-bench
pip install -e .以下を実行してインストールをテストします。
python -m swebench.harness.run_evaluation
--predictions_path gold
--max_workers 1
--instance_ids sympy__sympy-20590
--run_id validate-gold警告
SWE ベンチでの高速評価の実行はリソースを大量に消費する可能性があります。少なくとも 120 GB の空きストレージ、16 GB の RAM、および 8 CPU コアを備えたx86_64マシンで評価ハーネスを実行することをお勧めします。マシンに最適なワーカー数を見つけるには--max_workers引数を試してみる必要があるかもしれませんが、 min(0.75 * os.cpu_count(), 24)よりも少ない数を使用することをお勧めします。
Docker デスクトップで実行している場合は、仮想ディスク容量を最大 120 GB の空き容量を確保できるように増やし、max_workers を Docker で使用できる CPU について上記と一致するように設定してください。
arm64マシンのサポートは実験的です。
次のコマンドで評価ハーネスを使用し、SWE-bench Lite でモデル予測を評価します。
python -m swebench.harness.run_evaluation
--dataset_name princeton-nlp/SWE-bench_Lite
--predictions_path < path_to_predictions >
--max_workers < num_workers >
--run_id < run_id >
# use --predictions_path 'gold' to verify the gold patches
# use --run_id to name the evaluation runこのコマンドは、現在のディレクトリに docker ビルド ログ ( logs/build_images ) と評価ログ ( logs/run_evaluation ) を生成します。
最終的な評価結果は、 evaluation_resultsディレクトリに保存されます。
評価ハーネスの引数の完全なリストを表示するには、次のコマンドを実行します。
python -m swebench.harness.run_evaluation --helpさらに、SWE-Bench リポジトリは次のことに役立ちます。
| データセット | モデル |
|---|---|
| ? SWEベンチ | ? SWE-ラマ 13b |
| ? 「オラクル」の検索 | ? SWE-ラマ 13b (PEFT) |
| ? BM25 回収 13K | ? SWE-ラマ 7b |
| ? BM25 回収 27K | ? SWE-ラマ 7b (PEFT) |
| ? BM25 リトリーバル 40K | |
| ? BM25 取得 50K (ラマ トークン) |
SWE-bench のさまざまな部分の使用方法については、次のブログ投稿も作成しました。特定のトピックに関する投稿をご覧になりたい場合は、問題を通じてお知らせください。
NLP、機械学習、ソフトウェア エンジニアリングの幅広い研究コミュニティからの意見をお待ちしています。また、あらゆる貢献、プル リクエスト、問題点を歓迎します。これを行うには、新しいプル リクエストを提出するか、対応するテンプレートに必要事項を入力して発行してください。すぐにフォローアップさせていただきます。
連絡担当者: Carlos E. Jimenez および John Yang (電子メール: [email protected]、[email protected])。
私たちの取り組みが役立つと思われる場合は、次の引用を使用してください。
@inproceedings{
jimenez2024swebench,
title={{SWE}-bench: Can Language Models Resolve Real-world Github Issues?},
author={Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=VTF8yNQM66}
}
マサチューセッツ工科大学。 LICENSE.md確認してください。


