Index 1.9B
1.0.0
切换到中文 |オンライン: チャットとロールプレイング | QQ:QQグループ
Index-1.9B シリーズは、次のモデルを含む Index シリーズ モデルの軽量バージョンです。
| モデル | 平均点 | 英語の平均点 | MMLU | セヴァル | CMMLU | ヘラスワッグ | アークC | アークE |
|---|---|---|---|---|---|---|---|---|
| Google ジェマ 2B | 41.58 | 46.77 | 41.81 | 31.36 | 2月31日 | 66.82 | 36.39 | 42.07 |
| ファイ-2 (2.7B) | 58.89 | 72.54 | 57.61 | 12月31日 | 32.05 | 70.94 | 74.51 | 87.1 |
| クウェン1.5-1.8B | 58.96 | 59.28 | 47.05 | 59.48 | 57.12 | 58.33 | 56.82 | 74.93 |
| Qwen2-1.5B(レポート) | 65.17 | 62.52 | 56.5 | 70.6 | 70.3 | 66.6 | 43.9 | 83.09 |
| MiniCPM-2.4B-SFT | 62.53 | 68.75 | 53.8 | 49.19 | 50.97 | 67.29 | 69.44 | 84.48 |
| インデックス-1.9B-ピュア | 50.61 | 52.99 | 46.24 | 46.53 | 45.19 | 62.63 | 41.97 | 61.1 |
| インデックス-1.9B | 64.92 | 69.93 | 52.53 | 57.01 | 52.79 | 80.69 | 65.15 | 81.35 |
| ラマ2-7B | 50.79 | 60.31 | 44.32 | 32.42 | 11月31日 | 76 | 46.3 | 74.6 |
| ミストラル-7B (レポート) | / | 69.23 | 60.1 | / | / | 81.3 | 55.5 | 80 |
| 白川2-7B | 54.53 | 53.51 | 54.64 | 56.19 | 56.95 | 4月25日 | 57.25 | 77.12 |
| ラマ2-13B | 57.51 | 66.61 | 55.78 | 39.93 | 38.7 | 76.22 | 58.88 | 75.56 |
| 白川2-13B | 68.90 | 71.69 | 59.63 | 59.21 | 61.27 | 72.61 | 70.04 | 84.48 |
| MPT-30B(レポート) | / | 63.48 | 46.9 | / | / | 79.9 | 50.6 | 76.5 |
| Falcon-40B (レポート) | / | 68.18 | 55.4 | / | / | 83.6 | 54.5 | 79.2 |
評価コードは OpenCompass に基づいており、互換性が変更されています。詳細については、評価フォルダーを参照してください。
| ハグ顔 | モデルスコープ |
|---|---|
| ?インデックス-1.9B-チャット | インデックス-1.9B-チャット |
| ?インデックス-1.9B-キャラクター (ロールプレイング) | インデックス-1.9B-キャラクター (ロールプレイング) |
| ?インデックス-1.9B-ベース | インデックス-1.9B-ベース |
| ?インデックス-1.9B-ベース-ピュア | インデックス-1.9B-ベース-ピュア |
| ?インデックス-1.9B-32K (32K の長いコンテキスト) | インデックス-1.9B-32K (32K の長いコンテキスト) |
Index-1.9B-32Kこのツールdemo/cli_long_text_demo.pyを使用してのみ起動できます。git clone https://github.com/bilibili/Index-1.9B
cd Index-1.9Bpip install -r requirements.txt次のコードを使用して、対話用の Index-1.9B-Chat モデルをロードできます。
import argparse
from transformers import AutoTokenizer , pipeline
# Attention! The directory must not contain "." and can be replaced with "_".
parser = argparse . ArgumentParser ()
parser . add_argument ( '--model_path' , default = "./IndexTeam/Index-1.9B-Chat/" , type = str , help = "" )
parser . add_argument ( '--device' , default = "cpu" , type = str , help = "" ) # also could be "cuda" or "mps" for Apple silicon
args = parser . parse_args ()
tokenizer = AutoTokenizer . from_pretrained ( args . model_path , trust_remote_code = True )
generator = pipeline ( "text-generation" ,
model = args . model_path ,
tokenizer = tokenizer , trust_remote_code = True ,
device = args . device )
system_message = "你是由哔哩哔哩自主研发的大语言模型,名为“Index”。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"
query = "续写 天不生我金坷垃"
model_input = []
model_input . append ({ "role" : "system" , "content" : system_message })
model_input . append ({ "role" : "user" , "content" : query })
model_output = generator ( model_input , max_new_tokens = 300 , top_k = 5 , top_p = 0.8 , temperature = 0.3 , repetition_penalty = 1.1 , do_sample = True )
print ( 'User:' , query )
print ( 'Model:' , model_output )Gradio に応じて、次のようにインストールします。
pip install gradio==4.29.0次のコードを使用して Web サーバーを起動します。ブラウザにアクセス アドレスを入力すると、ダイアログに Index-1.9B-Chat モデルを使用できます。
python demo/web_demo.py --port= ' port ' --model_path= ' /path/to/model/ '注: Index-1.9B-32Kこのツールdemo/cli_long_text_demo.pyを使用してのみ起動できます。
次のコードで端末デモを開始し、対話に Index-1.9B-Chat モデルを使用します。
python demo/cli_demo.py --model_path= ' /path/to/model/ 'Flask に応じて、次のようにインストールします。
pip install flask==2.2.5次のコードを使用して Flask API を開始します。
python demo/openai_demo.py --model_path= ' /path/to/model/ 'コマンドライン経由でダイアログを実行できます。
curl http://127.0.0.1:8010/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"messages": [
{"role": "system", "content": "你是由哔哩哔哩自主研发的大语言模型,名为“Index”。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"},
{"role": "user", "content": "花儿为什么这么红?"}
]
} 'Index-1.9B-32K は、パラメーターが 19 億しかない言語モデルですが、32K のコンテキスト長をサポートしています (つまり、この非常に小さなモデルは一度に 35,000 ワードを超えるドキュメントを読み取ることができます)。このモデルは、慎重に厳選された長文トレーニング データと自己構築された長文命令セットに基づいて、特に 32,000 トークンを超えるテキストに対して継続事前トレーニングと教師あり微調整 (SFT) を受けています。このモデルは現在、Hugging Face と ModelScope の両方でオープンソースです。
Index-1.9B-32K は、サイズが小さい (GPT-4 などのモデルの約 2%) にもかかわらず、優れた長文処理能力を示します。下図に示すように、1.9Bサイズモデルのスコアは7Bサイズモデルをも上回っています。以下は GPT-4 や Qwen2 などのモデルとの比較です。
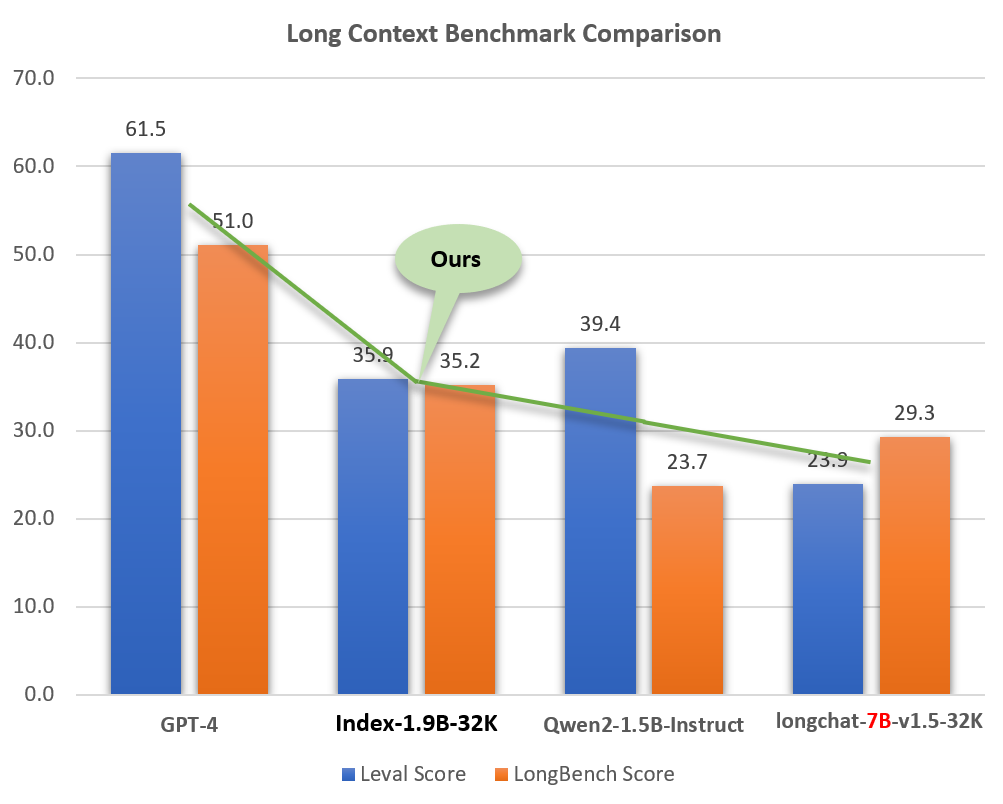
Index-1.9B-32K と GPT-4、Qwen2、およびロング コンテキスト機能における他のモデルの比較
以下の図に示すように、長さ 32K の干し草の山に針を入れるテストで、Index-1.9B-32K は優れた結果を達成しました。唯一の例外は、(長さ 32K、深さ 10%) の領域にある小さな黄色のスポット (91.08 ポイント) で、他のすべての領域はほとんどが緑色のゾーンで優れたパフォーマンスを示しました。
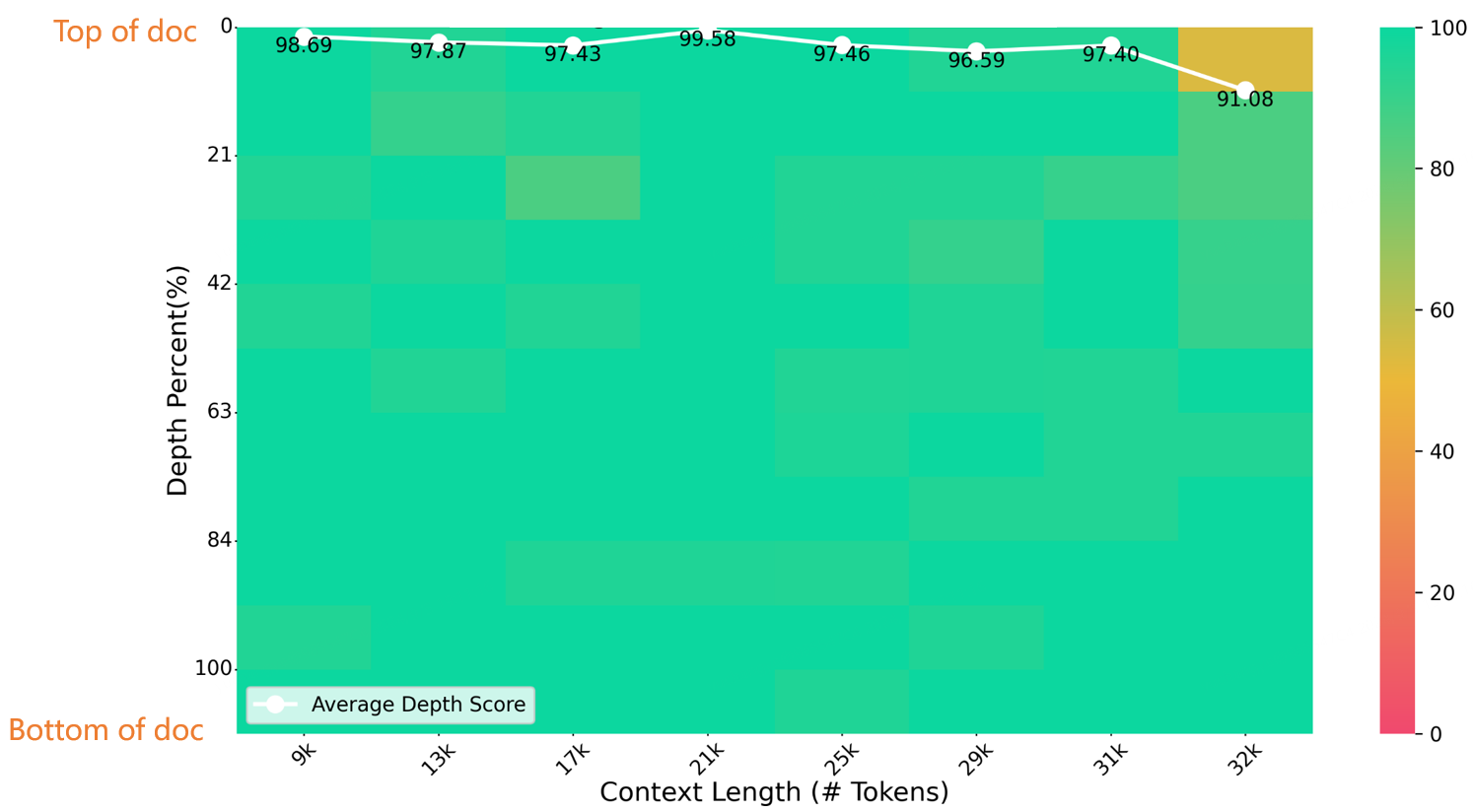
NeedleBench の評価
Index-1.9B-32K のダウンロード、使用法、技術レポートの詳細については、以下を参照してください。
インデックス-1.9B-32K ロングコンテキストテクニカルレポートweb_demo.pyを使用して Index-1.9B-Chat 出力を取得する例です。 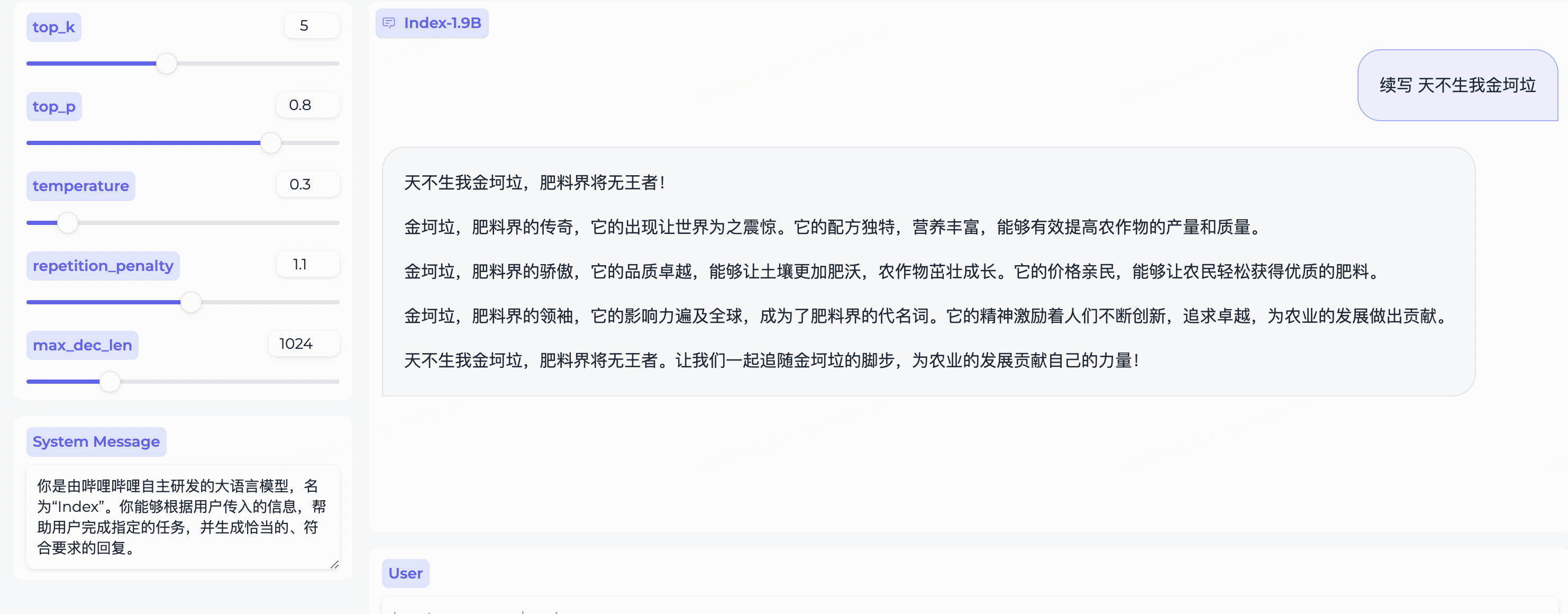
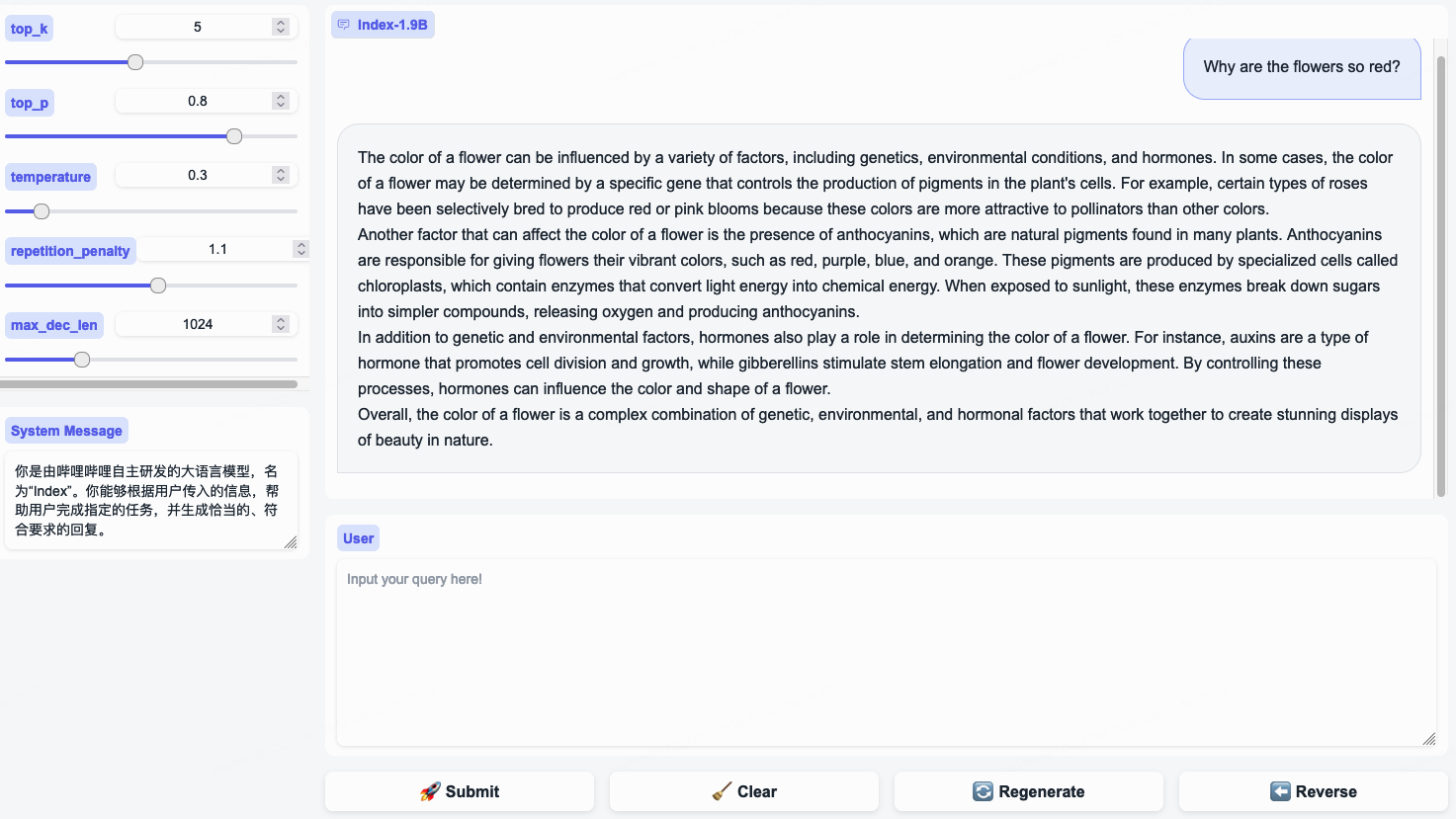
System Message変更して、bilibili ユーザーのステレオタイプをロールプレイします。 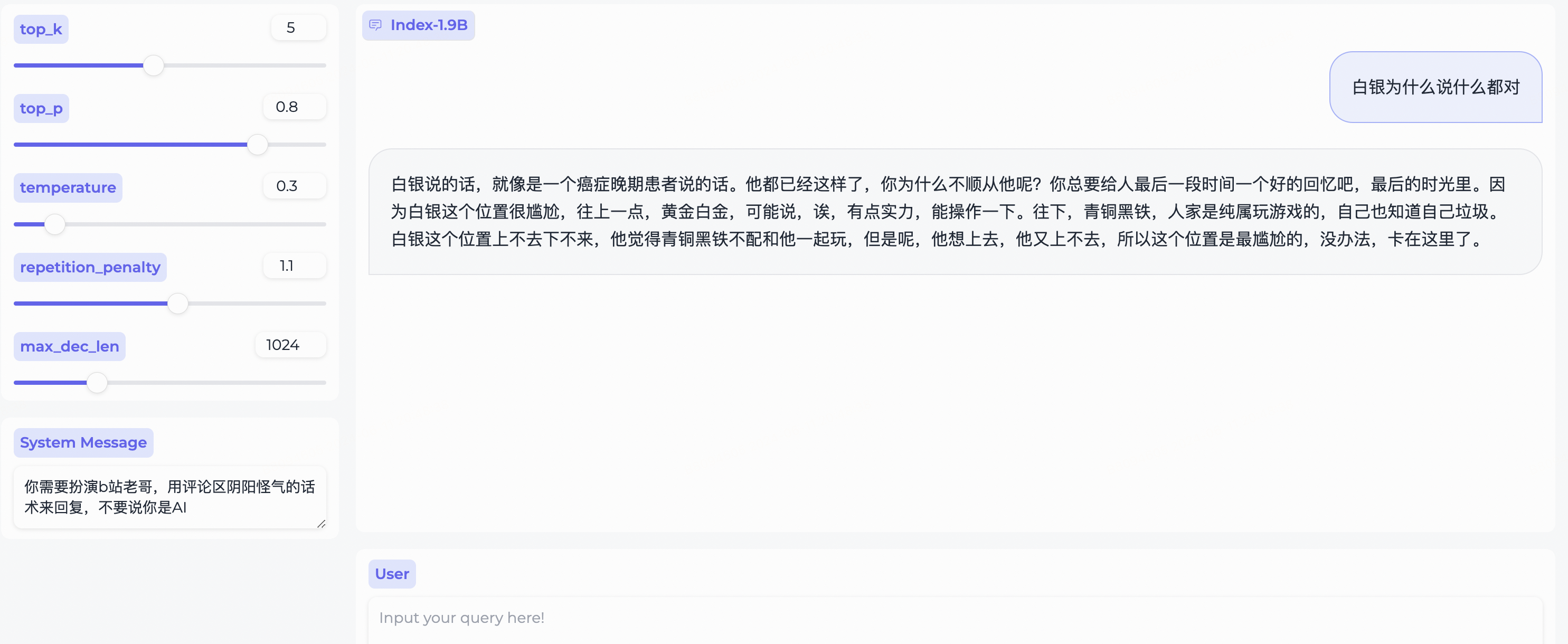
私たちは、ロールプレイング モデルとそれに付随するフレームワークを同時にオープンソース化しました。 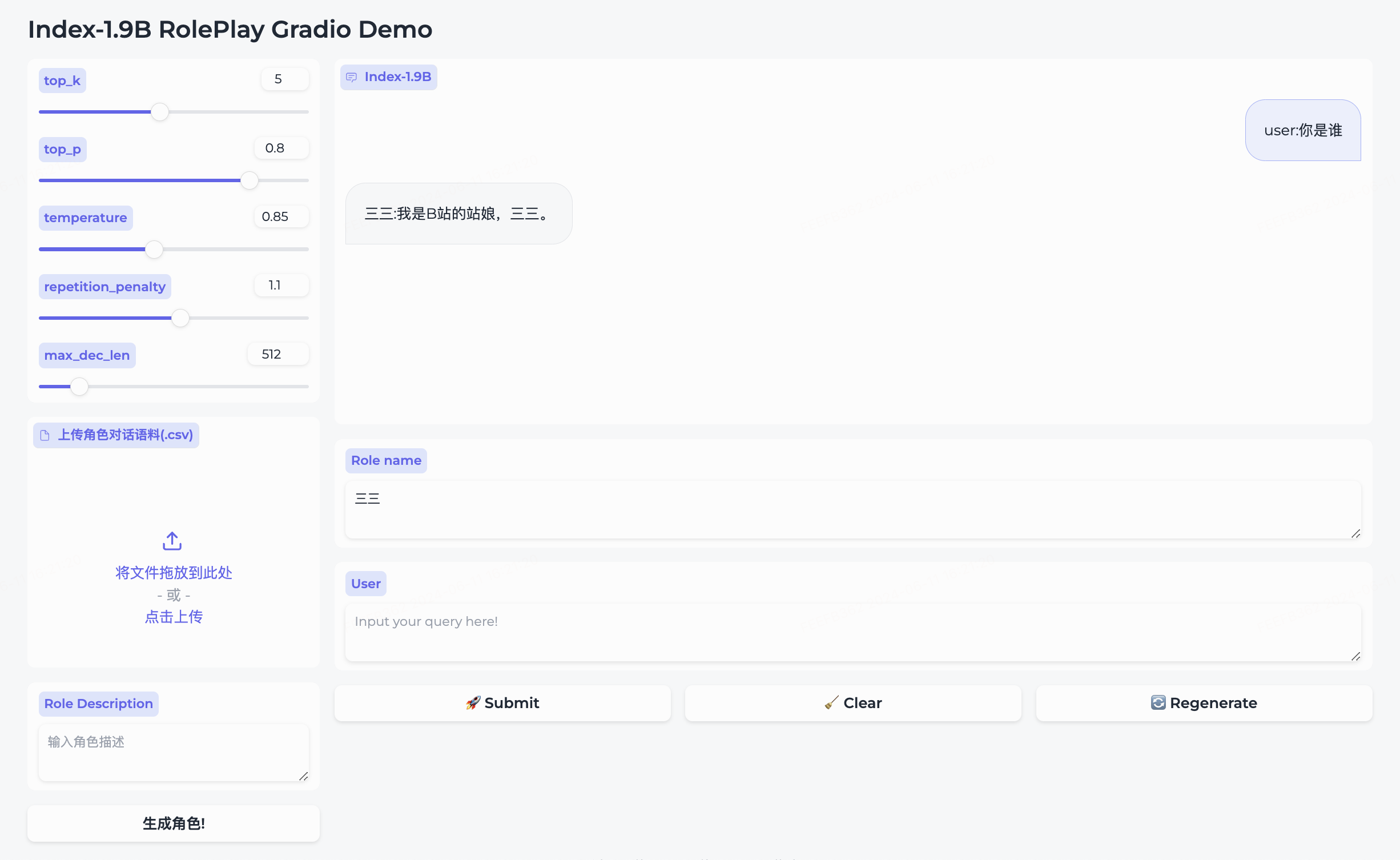
三三が組み込まれています。生成角色をクリックして正常に作成します。Role name欄に会話したいキャラクターを直接入力し、 queryを入力してsubmitクリックすると会話が開始されます。詳しい使い方はロールプレイフォルダを参照してください。
cd demo/
CUDA_VISIBLE_DEVICES=0 python cli_long_text_demo.py --model_path ' /path/to/model/ ' --input_file_path data/user_long_text.txt
翻訳と要約(2024.8.22リリースのBilibili財務レポート)
bitsandbytes に応じて、インストール コマンド:
pip install bitsandbytes==0.43.0次のスクリプトを使用して int4 量子化を実行すると、パフォーマンスの損失が少なく、ビデオ メモリの使用量がさらに節約されます。
import torch
import argparse
from transformers import (
AutoModelForCausalLM ,
AutoTokenizer ,
TextIteratorStreamer ,
GenerationConfig ,
BitsAndBytesConfig
)
parser = argparse . ArgumentParser ()
parser . add_argument ( '--model_path' , default = "" , type = str , help = "" )
parser . add_argument ( '--save_model_path' , default = "" , type = str , help = "" )
args = parser . parse_args ()
tokenizer = AutoTokenizer . from_pretrained ( args . model_path , trust_remote_code = True )
quantization_config = BitsAndBytesConfig (
load_in_4bit = True ,
bnb_4bit_compute_dtype = torch . float16 ,
bnb_4bit_use_double_quant = True ,
bnb_4bit_quant_type = "nf4" ,
llm_int8_threshold = 6.0 ,
llm_int8_has_fp16_weight = False ,
)
model = AutoModelForCausalLM . from_pretrained ( args . model_path ,
device_map = "auto" ,
torch_dtype = torch . float16 ,
quantization_config = quantization_config ,
trust_remote_code = True )
model . save_pretrained ( args . save_model_path )
tokenizer . save_pretrained ( args . save_model_path )微調整チュートリアルの手順に従って、Index-1.9B-Chat モデルをすばやく微調整します。ぜひ試してみて、あなただけの Index モデルをカスタマイズしてください。
Index-1.9B は、特定の状況において、不正確、偏った、または不快なコンテンツを生成する可能性があります。モデルは個人的な意見を理解したり、表現したり、価値判断をしたりすることはできません。その出力はモデル開発者の見解や立場を表すものではありません。したがって、生成されたコンテンツは注意して使用してください。ユーザーは、モデルによって生成されたコンテンツを独自に評価および検証する必要があり、有害なコンテンツを広めてはなりません。開発者は、関連アプリケーションを展開する前に、特定のアプリケーションに応じて安全性テストと微調整を実施する必要があります。
これらのモデルを使用して、有害な情報を作成または広めたり、公共、国家、または社会の安全を害したり、規制に違反したりする可能性のある活動に従事しないことを強くお勧めします。適切な安全性審査と申請を行わずに、モデルをインターネット サービスに使用しないでください。トレーニング データのコンプライアンスを確保するためにあらゆる努力を払ってきましたが、モデルとデータの複雑さにより、予期せぬ問題が依然として存在する可能性があります。当社は、データセキュリティ、世論リスク、またはモデルの誤解、誤用、普及、または準拠していない使用によって引き起こされるリスクや問題に関連するかどうかにかかわらず、これらのモデルの使用から生じる問題については責任を負いません。
このリポジトリのソース コードを使用するには、Apache-2.0 に準拠する必要があります。 Index-1.9B モデルの重みを使用するには、INDEX_MODEL_LICENSE に準拠する必要があります。
Index-1.9B モデルの重みは学術研究向けに完全にオープンであり、無料の商用利用をサポートしています。
私たちの取り組みが役に立ったと思われる場合は、お気軽に引用してください。
@article{Index,
title={Index1.9B Technical Report},
year={2024}
}
libllm: https://github.com/ling0322/libllm/blob/main/examples/python/run_bilibili_index.py
chatllm.cpp:https://github.com/foldl/chatllm.cpp/blob/master/docs/rag.md#role-play-with-rag
オラマ:https://ollama.com/milkey/bilibili-index
self llm: https://github.com/datawhalecina/self-llm/blob/master/bilibili_Index-1.9B/04-Index-1.9B-Chat%20Lora%20微调.md


