LRV Instruction
1.0.0
Fuxiao Liu、Kevin Lin、Linjie Li、Jianfeng Wang、Yaser Yacoob、Lijuan Wang
[プロジェクトページ] [論文]
以下で当社モデルとオリジナルモデルを比較できます。オンライン デモが動作しない場合は、 [email protected]電子メールでご連絡ください。私たちの仕事が興味深いと思われた場合は、私たちの仕事を引用してください。ありがとう!!!
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}
@article { liu2023hallusionbench ,
title = { HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V (ision), LLaVA-1.5, and Other Multi-modality Models } ,
author = { Liu, Fuxiao and Guan, Tianrui and Li, Zongxia and Chen, Lichang and Yacoob, Yaser and Manocha, Dinesh and Zhou, Tianyi } ,
journal = { arXiv preprint arXiv:2310.14566 } ,
year = { 2023 }
}
@article { liu2023mmc ,
title = { MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning } ,
author = { Liu, Fuxiao and Wang, Xiaoyang and Yao, Wenlin and Chen, Jianshu and Song, Kaiqiang and Cho, Sangwoo and Yacoob, Yaser and Yu, Dong } ,
journal = { arXiv preprint arXiv:2311.10774 } ,
year = { 2023 }
} [LRV-V2(Mplug-Owl) デモ]、[mplug-owl デモ]
[LRV-V1(MiniGPT4) デモ]、[MiniGPT4-7B デモ]
| 機種名 | バックボーン | ダウンロードリンク |
|---|---|---|
| LRV-命令 V2 | Mplug-フクロウ | リンク |
| LRV-命令 V1 | MiniGPT4 | リンク |
| 機種名 | 命令 | 画像 |
|---|---|---|
| LRV命令 | リンク | リンク |
| LRVの説明(詳細) | リンク | リンク |
| チャートの説明 | リンク | リンク |
GPT4 によって生成された300,000 個の視覚的指示でデータセットを更新し、自由形式の指示と回答を含む 16 の視覚と言語のタスクをカバーします。 LRV 命令には、より堅牢な視覚的命令チューニングのためのポジティブ命令とネガティブ命令の両方が含まれています。データセットの画像は Visual Genome からのものです。私たちのデータにはここからアクセスできます。
{'image_id': '2392588', 'question': 'Can you see a blue teapot on the white electric stove in the kitchen?', 'answer': 'There is no mention of a teapot on the white electric stove in the kitchen.', 'task': 'negative'}
各インスタンスのimage_id 、Visual Genome の画像を参照します。 questionとanswer指示と回答のペアを指します。 taskタスク名を示します。ここから画像をダウンロードできます。
この分野での研究を促進するために、GPT-4 クエリに対するプロンプトを提供しています。ポジティブ インスタンスとネガティブ インスタンスの生成については、 promptsを確認してください。 negative1_generation_prompt.txtには、存在しない要素の操作で否定的な命令を生成するためのプロンプトが含まれています。 negative2_generation_prompt.txtは、既存要素操作を使用してネガティブな命令を生成するためのプロンプトが含まれています。ここのコードを参照して、より多くのデータを生成できます。詳細については、論文を参照してください。

1. このリポジトリのクローンを作成します
https://github.com/FuxiaoLiu/LRV-Instruction.git2. パッケージのインストール
conda env create -f environment.yml --name LRV
conda activate LRV3. ビクーニャウェイトを準備します。
私たちのモデルは、Vicuna-7B を使用した MiniGPT-4 で微調整されています。ビクーニャウェイトを準備するには、こちらの説明を参照するか、ここからダウンロードしてください。次に、MiniGPT-4/minigpt4/configs/models/minigpt4.yaml の 15 行目に Vicuna 重みへのパスを設定します。
4. モデルの事前トレーニング済みチェックポイントを準備します
ここから事前トレーニングされたチェックポイントをダウンロードします
次に、MiniGPT-4/eval_configs/minigpt4_eval.yaml の 11 行目で事前トレーニング済みチェックポイントへのパスを設定します。このチェックポイントは MiniGPT-4-7B に基づいています。今後、MiniGPT-4-13BとLLaVAのチェックポイントを公開する予定です。
5. データセットのパスを設定する
データセットを取得した後、MiniGPT-4/minigpt4/configs/datasets/cc_sbu/align.yaml の 5 行目にパスをデータセット パスに設定します。データセット フォルダーの構造は次のようになります。
/MiniGPt-4/cc_sbu_align
├── image(Visual Genome images)
├── filter_cap.json
6. ローカルデモ
次のコマンドを実行して、ローカル マシン上で微調整されたモデルのデモdemo.pyを試してみてください。
cd ./MiniGPT-4
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
ここの例を試してみてください。
7. モデル推論
ここに推論命令ファイルのパス、ここに推論画像フォルダ、ここに出力場所を設定します。トレーニングプロセスでは推論を実行しません。
cd ./MiniGPT-4
python inference.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
1. mplug-owlに従って環境をインストールします。
8 V100 で mplug-owl を微調整しました。 V100 に実装する際に質問がある場合は、お気軽にお知らせください。
2. チェックポイントをダウンロードする
まずリンクから mplug-owl のチェックポイントをダウンロードし、トレーニングされた lora モデルの重みをここからダウンロードします。
3. コードを編集する
mplug-owl/serve/model_worker.pyについては、以下のコードを編集し、 lora_path に lora モデルの重みのパスを入力します。
self.image_processor = MplugOwlImageProcessor.from_pretrained(base_model)
self.tokenizer = AutoTokenizer.from_pretrained(base_model)
self.processor = MplugOwlProcessor(self.image_processor, self.tokenizer)
self.model = MplugOwlForConditionalGeneration.from_pretrained(
base_model,
load_in_8bit=load_in_8bit,
torch_dtype=torch.bfloat16 if bf16 else torch.half,
device_map="auto"
)
self.tokenizer = self.processor.tokenizer
peft_config = LoraConfig(target_modules=r'.*language_model.*.(q_proj|v_proj)', inference_mode=False, r=8,lora_alpha=32, lora_dropout=0.05)
self.model = get_peft_model(self.model, peft_config)
lora_path = 'Your lora model path'
prefix_state_dict = torch.load(lora_path, map_location='cpu')
self.model.load_state_dict(prefix_state_dict)
4. ローカルデモ
ローカル マシンでデモを起動すると、テキスト入力用のスペースがないことに気づく場合があります。これは、Python と gradio の間のバージョンの競合が原因です。最も簡単な解決策は、 conda activate LRV実行することです
python -m serve.web_server --base-model 'the mplug-owl checkpoint directory' --bf16
5. モデル推論
まず mplug-owl からコードを git clone し、 /mplug/serve/model_worker.py /utils/model_worker.pyに置き換えて、 /utils/inference.pyファイルを追加します。次に、入力データ ファイルと画像フォルダーのパスを編集します。最後に実行します:
python -m serve.inference --base-model 'your checkpoint directory' --bf16
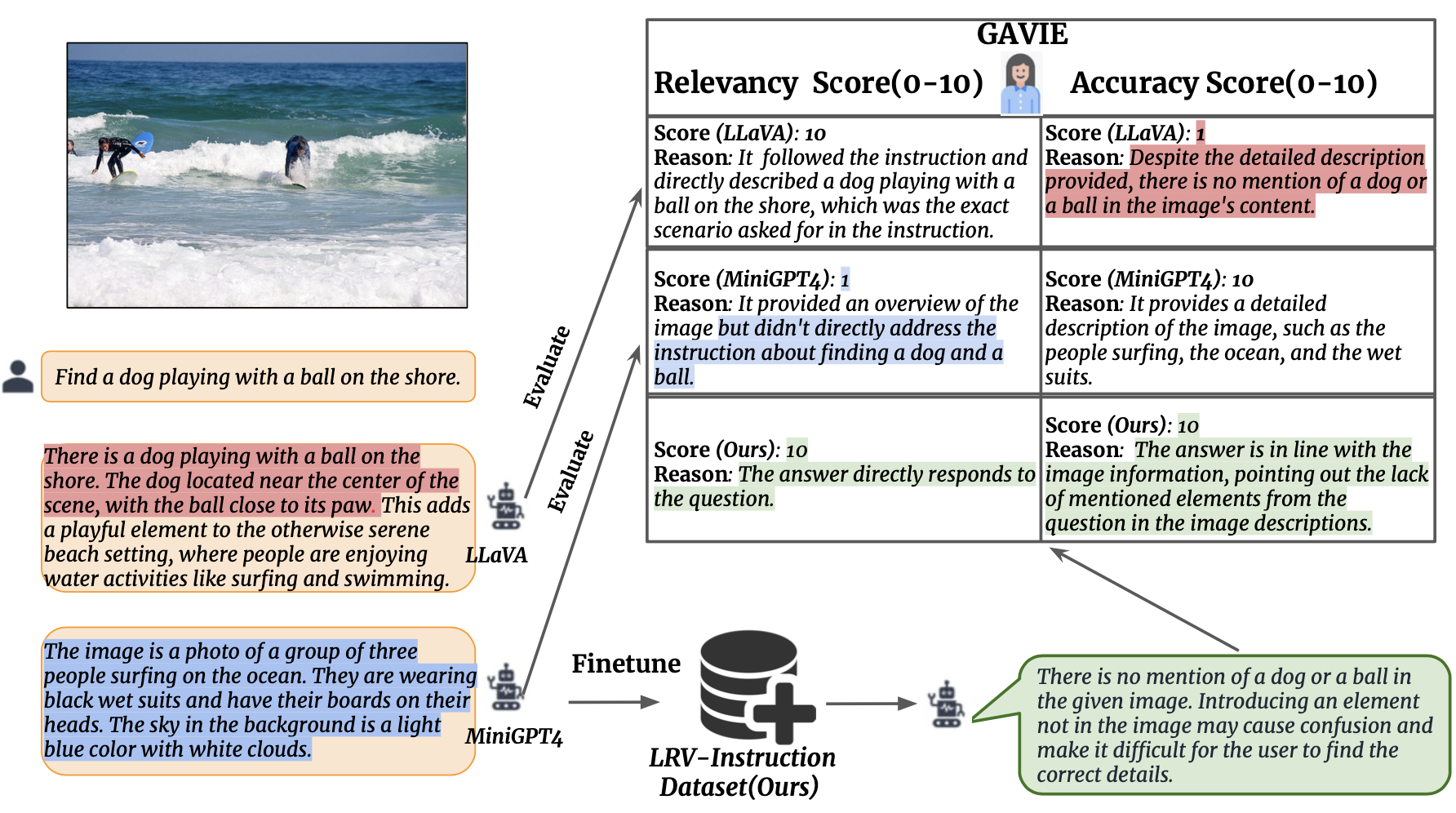
人間による注釈付きのグラウンドトゥルース回答を必要とせずに、LMM によって生成される幻覚を測定するための、より柔軟で堅牢なアプローチとして GPT4 支援視覚命令評価 (GAVIE) を紹介します。 GPT4 は、境界ボックス座標を含む高密度キャプションを画像コンテンツとして取得し、人間の指示とモデルの応答を比較します。次に、GPT4 に賢い教師として機能してもらい、次の 2 つの基準に基づいて生徒の回答をスコア (0 ~ 10) します: (1) 精度: 回答が画像コンテンツで幻覚を示すかどうか。 (2) 関連性: 応答が指示に直接従うかどうか。 prompts/GAVIE.txtは GAVIE のプロンプトが含まれています。
当社の評価セットはここから入手できます。
{'image_id': '2380160', 'question': 'Identify the type of transportation infrastructure present in the scene.'}
各インスタンスのimage_id 、Visual Genome の画像を参照します。 instructionとは命令を指します。 answer_gt Text-Only GPT4 のグラウンドトゥルース回答を指しますが、評価では使用しません。代わりに、Text-Only GPT4 を使用して、Visual Genome データセットからの密なキャプションと境界ボックスをビジュアル コンテンツとして使用してモデル出力を評価します。
モデルの出力を評価するには、まずここから vg アノテーションをダウンロードします。次に、ここのコードに従って評価プロンプトを生成します。 3 番目に、プロンプトを GPT4 に入力します。
GPT4(GPT4-32k-0314) は賢い教師として機能し、2 つの基準に基づいて生徒の解答を採点 (0 ~ 10) します。
(1) 正確さ: 応答が画像コンテンツで幻覚を示すかどうか。 (2) 関連性: 応答が指示に直接従うかどうか。
| 方法 | GAVIE-精度 | GAVIE-関連性 |
|---|---|---|
| LLaVA1.0-7B | 4.36 | 6.11 |
| LLaVA 1.5-7B | 6.42 | 8.20 |
| MiniGPT4-v1-7B | 4.14 | 5.81 |
| MiniGPT4-v2-7B | 6.01 | 8.10 |
| mPLUG-フクロウ-7B | 4.84 | 6.35 |
| インストラクトBLIP-7B | 5.93 | 7.34 |
| MMGPT-7B | 0.91 | 1.79 |
| アワーズ-7B | 6.58 | 8.46 |
私たちの研究があなたの研究や応用に役立つと思われる場合は、この BibTeX を使用して引用してください。
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}このリポジトリは BSD 3 条項ライセンスの下にあります。ここでは、多くのコードが MiniGPT4 と BSD 3 条項ライセンス付きの mplug-Owl に基づいています。


