gptty
0.2.7
TTY の ChatGPT ラッパー
注記
このバージョンは gpt4 と gpt4-turbo をサポートします。
gptty は ChatGPT シェル インターフェイスで、(1) Web アプリケーションと同様の方法で ChatGPT と対話できますが、Web アプリケーションの安定性に依存する必要はありません。 (2) チャット セッション全体でコンテキストを保持し、必要に応じて会話を構築します。 (3) 簡単に参照できるように、会話のローカル コピーを保存します。
おそらく、あなたは雇用主のために Web サーバーを構成しているシステム管理者かもしれません。インターネット接続はあるものの、デスクトップ環境やグラフィカル ユーザー インターフェイスはなく、物理インターフェイスからシステムにアクセスしています。 Web サーバーの構成中に、ファイルにリダイレクトするという不可解なエラーが発生しましたが、エラーを調べるためにブラウザーを使用してファイルを別のシステムにコピーするという面倒な作業は避けたいと考えています。代わりに、gptty をインストールし、 gptty query --tag error --question "$(cat app.error | tr 'n' ' ')" (改行が削除されます) のようなコマンドを使用してエラーをチャット クライアントにリダイレクトします。あなたのため) またはcat app.error | xargs -d 'n' -I {} gptty query --tag error --question "{}" (エラーが 1 行のみに及ぶことを前提としています)。
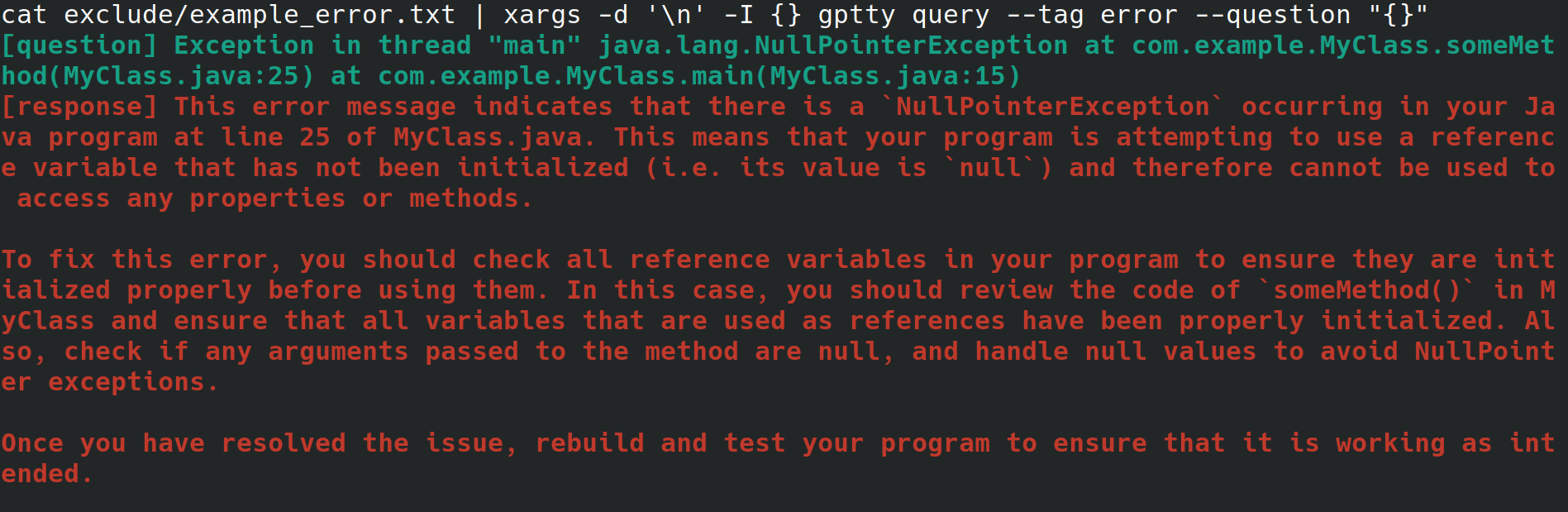
あるいは、ソフトウェア開発者またはデータ サイエンティストは、ChatGPT を介してデータをパイプしたいが、OpenAI API とそのさまざまな言語固有のラッパーに詳しくなく、高度に抽象化された API を使用してこれらのリクエストを実行したいと考えています。別のモデルを使用するようにコード ベースを更新する場合、単一の構成ファイルを変更するだけで、さまざまなモデル間でクエリ応答形式の一貫性が保たれることが望まれます。
あるいは、あなたは、会話のローカル コピーを保存しておきたい、または会話に使用する分類方法をより直接的に制御したいと考えている愛好家かもしれません。
OpenAI は、API を通じて多数のモデルを利用できるようにします。 [1] 現在、gptty はCompletions (davinci、curie) とChatCompletions (gpt-3.5-turbo、gpt-4) をサポートしています。設定でモデル名を指定するだけで (デフォルトは text-davinci-003)、残りはアプリケーションが処理します。
pip にgpttyインストールできます。
pip install gptty
git からインストールすることもできます。
cd ~/Code # replace this with whatever directory you want to use
git clone https://github.com/signebedi/gptty.git
cd gptty/
# now install the requirements
python3 -m venv venv
source venv/bin/activate
pip install -e .
ここで、 gptty --helpを実行して、動作していることを確認できます。エラーが発生した場合は、アプリを構成してみてください。
gptty 、 gptty.iniという名前のファイルから構成設定を読み取ります。アプリは、カスタムconfig_file渡さない限り、このファイルはgptty実行しているのと同じディレクトリにあると想定します。このファイルは INI ファイル形式を使用しており、各セクションに独自のキーと値のペアが含まれるセクションで構成されます。
| 鍵 | タイプ | デフォルト値 | 説明 |
|---|---|---|---|
| API_キー | 弦 | 「」 | OpenAI の GPT サービスの API キー |
| 組織ID | 弦 | 「」 | OpenAI の GPT サービスの組織 ID |
| あなたの名前 | 弦 | "質問" | 入力プロンプトの名前 |
| gpt_name | 弦 | "応答" | 生成された応答の名前 |
| 出力ファイル | 弦 | 「出力.txt」 | 出力が保存されるファイルの名前 |
| モデル | 弦 | 「テキスト-ダヴィンチ-003」 | 使用する GPT モデルの名前 |
| 温度 | フロート | 0.0 | サンプリングに使用する温度 |
| max_tokens | 整数 | 250 | 応答に対して生成するトークンの最大数 |
| max_context_length | 整数 | 150 | 入力コンテキストの最大長 |
| コンテキストキーワードのみ | ブール | 真実 | キーワードをトークン化して API の使用量を削減する |
| 新規行の保存 | ブール | 間違い | 応答の元の形式を維持する |
| verify_internet_endpoint | 弦 | 「グーグル.com」 | インターネット接続を検証するためのアドレス |
ニーズに合わせて構成ファイルの設定を変更できます。設定ファイルにキーが存在しない場合は、デフォルト値が使用されます。 [main] セクションは、プログラムの設定を指定するために使用されます。
[main]
api_key =my_api_keyこのリポジトリは、開始点として使用できるサンプル構成ファイルassets/gptty.ini.exampleを提供します。
チャット機能は、ChatGPT と通信するための対話型チャット インターフェイスを提供します。リアルタイムで質問し、回答を受け取ることができます。
チャット インターフェイスを開始するには、 gptty chatを実行します。次のコマンドを実行して、カスタム構成ファイルのパスを指定することもできます。
gptty chat --config_path /path/to/your/gptty.ini
チャット インターフェイス内で、質問やコマンドを直接入力できます。使用可能なコマンドのリストを表示するには、 :helpと入力すると、次のオプションが表示されます。
| メタコマンド | 説明 |
|---|---|
| :ヘルプ | 使用可能なコマンドとその説明のリストを表示します。 |
| :やめる | ChatGPT を終了します。 |
| :ログ | 現在の構成設定を表示します。 |
| :コンテキスト[a:b] | オプションで範囲 a と b を指定して、コンテキスト履歴を表示します。開発中 |
コマンドを使用するには、コマンド プロンプトにコマンドを入力して Enter キーを押すだけです。たとえば、次のコマンドを使用して、ターミナルの現在の構成設定を表示します。
> :configs
api_key: SOME_KEY_HERE
org_id: org-SOME_CHARS_HERE
your_name: question
gpt_name: response
output_file: output.txt
model: text-davinci-003
temperature: 0.0
max_tokens: 250
max_context_length: 5000
いつでもプロンプトに質問を入力すると、応答が生成されます。クエリ間でコンテキストを共有したい場合は、以下のコンテキスト セクションを参照してください。
クエリ機能を使用すると、単一または複数の質問を ChatGPT に送信し、コマンド ラインで直接回答を受け取ることができます。
クエリ機能を使用するには、次のようなコマンドを実行します。
gptty query --question "What is the capital of France?" --question "What is the largest mammal?"
オプションのタグを指定してクエリを分類することもできます。
gptty query --question "What is the capital of France?" --tag "geography"
必要に応じて、カスタム構成ファイルのパスを指定できます。
gptty query --config_path /path/to/your/gptty.ini --question "What is the capital of France?"
gptty は構成ファイル (デフォルトでは gptty.ini) を使用して、API キー、モデル構成、出力ファイル パスなどの設定を保存することに注意してください。 gptty コマンドを実行する前に、有効な構成ファイルがあることを確認してください。
チャット コマンドとクエリ コマンドの最後に--verboseタグを追加すると、アプリケーションは各リクエストのトークン数などの追加のデバッグ データを提供します。これは、API 使用率を追跡する必要がある場合に役立ちます。

--additional_context [some_string_here]オプションをクエリ コマンドに追加すると、アプリケーションは、渡された文字列を質問の外部コンテキストとして追加します。
クエリ コマンドの最後に--jsonタグを追加すると、アプリケーションは人間が判読できるテキストを stdout に書き込むのをスキップし、代わりに質問と回答を[{"question":QUESTION_1, "response":RESPONSE_1},{"question":QUESTION_1, "response":RESPONSE_1},...]のような json オブジェクトとして書き込みます) [{"question":QUESTION_1, "response":RESPONSE_1},{"question":QUESTION_1, "response":RESPONSE_1},...] 。

クエリ コマンドの最後に--quietタグを追加すると、アプリケーションは stdout への書き込みをスキップしますが、アプリケーション構成ファイルで指定されたoutput_fileに応答を書き込みます。
このアプリでchatおよびqueryサブコマンドを使用するときにコンテキストのテキストにタグを付けると、生成される応答の精度を向上させることができます。アプリがchatサブコマンドを使用してコンテキストを処理する方法は次のとおりです。
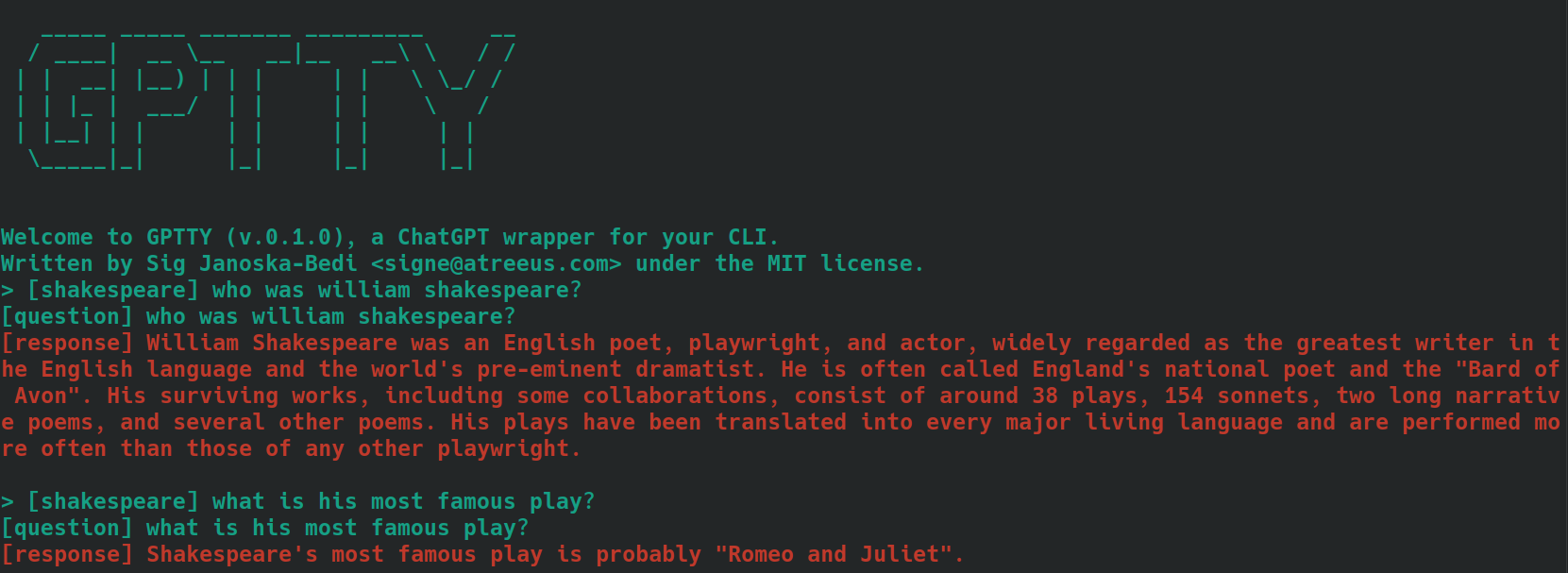
bananasやshakespeareなどのコンテキストを説明する単語または短いフレーズを使用できます。[tag]というプレフィックスを付けて、入力メッセージにタグを含めます。たとえば、質問のコンテキストが「料理」の場合、 [cooking]とタグ付けできます。関連するすべてのクエリに対して一貫して同じタグを使用してください。 [shakespeare]というタグが付いた質問を使用した例を次に示します。 2 番目の質問では、「ウィリアム シェイクスピア」という名前がまったく言及されていないことに注目してください。
queryサブコマンドを使用する場合は、上記と同じ手順に従いますが、質問のテキストの前に目的のタグを追加する代わりに、 --tagオプションを使用してクエリを送信するときにタグを含めます。たとえば、質問のコンテキストが「料理」の場合、次のように使用できます。
gptty --question "some question" --tag cooking
アプリケーションは、タグ付けされた質問と回答を、構成ファイルで指定された出力ファイルに保存します。
bash スクリプトを使用して、複数の質問をgptty queryコマンドに送信するプロセスを自動化できます。これは、質問のリストがファイルに保存されており、それらをすべて一度に処理したい場合に特に便利です。たとえば、以下のように、各質問が新しい行に記載されているファイルquestions.txtがあるとします。
What are the key differences between machine learning, deep learning, and artificial intelligence?
How do I choose the best programming language for a specific project or task?
Can you recommend some best practices for code optimization and performance improvement?
What are the essential principles of good software design and architecture?
How do I get started with natural language processing and text analysis in Python?
What are some popular Python libraries or frameworks for building web applications?
Can you suggest some resources to learn about data visualization and its implementation in Python?
What are some important concepts in cybersecurity, and how can I apply them to my projects?
How do I ensure that my machine learning models are fair, ethical, and unbiased?
Can you recommend strategies for staying up-to-date with the latest trends and advancements in technology and programming?
次の bash ワンライナーを使用して、 questions.txtファイルからgptty queryコマンドに各質問を送信できます。
xargs -d ' n ' -I {} gptty query --question " {} " < questions.txt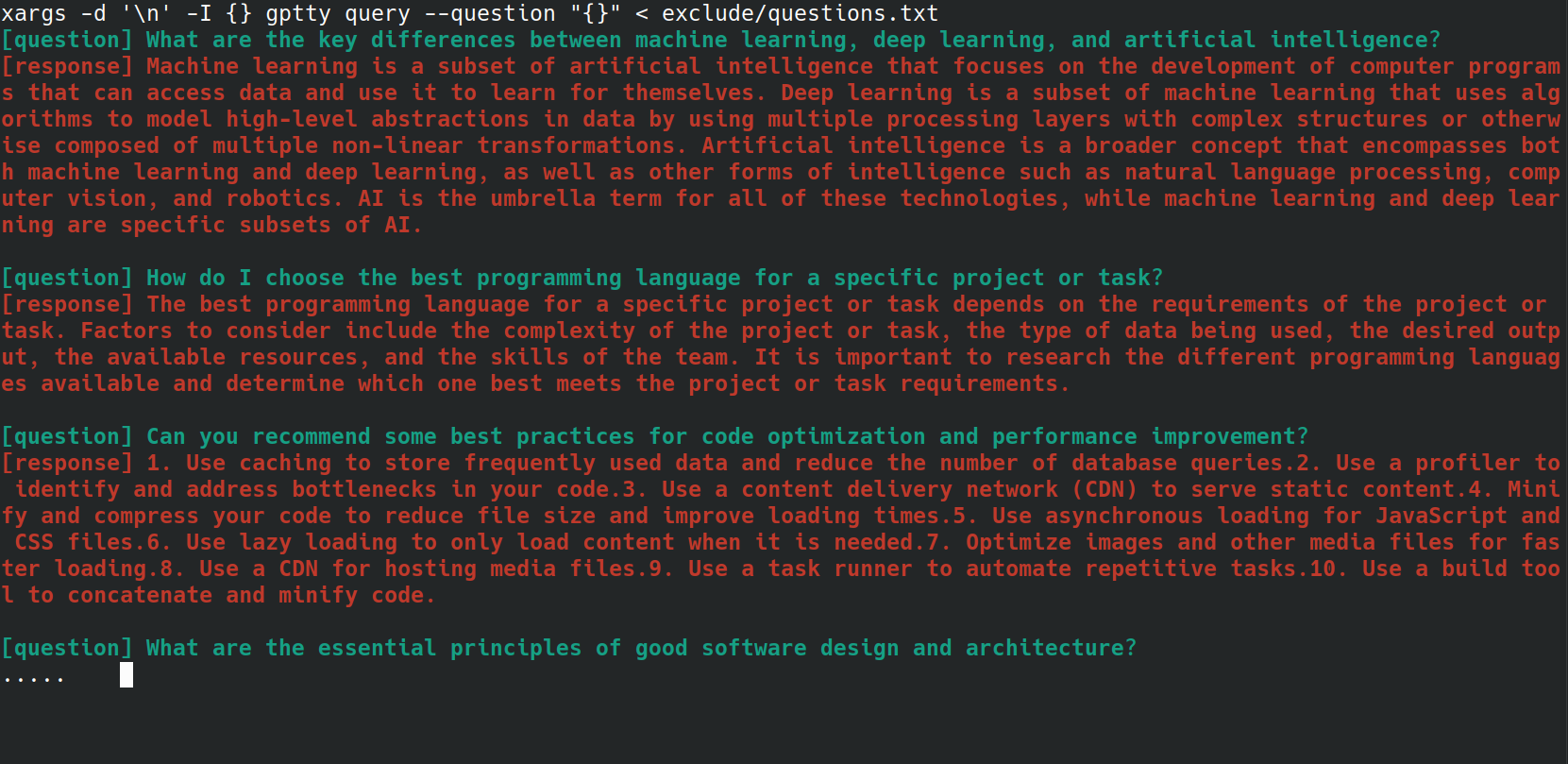
UniversalCompletion クラスは、OpenAI の言語モデルと対話するための統合インターフェイスを提供し、アプリケーションが Completion モードと ChatCompletion モードのどちらを使用しているかという詳細を (ほとんど) 抽象化します。主なアイデアは、言語モデルの作成、構成、管理を容易にすることです。以下に使用例を示します。
# First, import the UniversalCompletion class from the gptty library.
from gptty import UniversalCompletion
# Now, we instantiate a new UniversalCompletion object.
# The 'api_key' parameter is your OpenAI API key, which you get when you sign up for the API.
# The 'org_id' parameter is your OpenAI organization ID, which is also provided when you sign up.
g = UniversalCompletion ( api_key = "sk-SOME_CHARS_HERE" , org_id = "org-SOME_CHARS_HERE" )
# This connects to the OpenAI API using the provided API key and organization ID.
g . connect ()
# Now we specify which language model we want to use.
# Here, 'gpt-3.5-turbo' is specified, which is a version of the GPT-3 model.
g . set_model ( 'gpt-3.5-turbo' )
# This method is used to verify the model type.
# It returns a string that represents the endpoint for the current model in use.
g . validate_model_type ( g . model ) # Returns: 'v1/chat/completions'
# We send a request to the language model here.
# The prompt is a question, given in a format that the model understands.
# The model responds with a completion - an extension of the prompt based on what it has learned during training.
# The returned object is a representation of the response from the model.
g . fetch_response ( prompt = [{ "role" : "user" , "content" : "What is an abstraction?" }])
# Returns a JSON response with the assistant's message.

