thumb
1.0.0
LLM 用のシンプルなプロンプト テスト ライブラリ。
pip install thumb
import os
import thumb
# Set your API key: https://platform.openai.com/account/api-keys
os . environ [ "OPENAI_API_KEY" ] = "YOUR_API_KEY_HERE"
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])デフォルトでは、各プロンプトは非同期で 10 回実行されます。これは、順次実行するよりも約 9 倍高速です。 Jupyter Notebook では、ブラインド評価応答に対してシンプルなユーザー インターフェイスが表示されます (どのプロンプトが応答を生成したかはわかりません)。
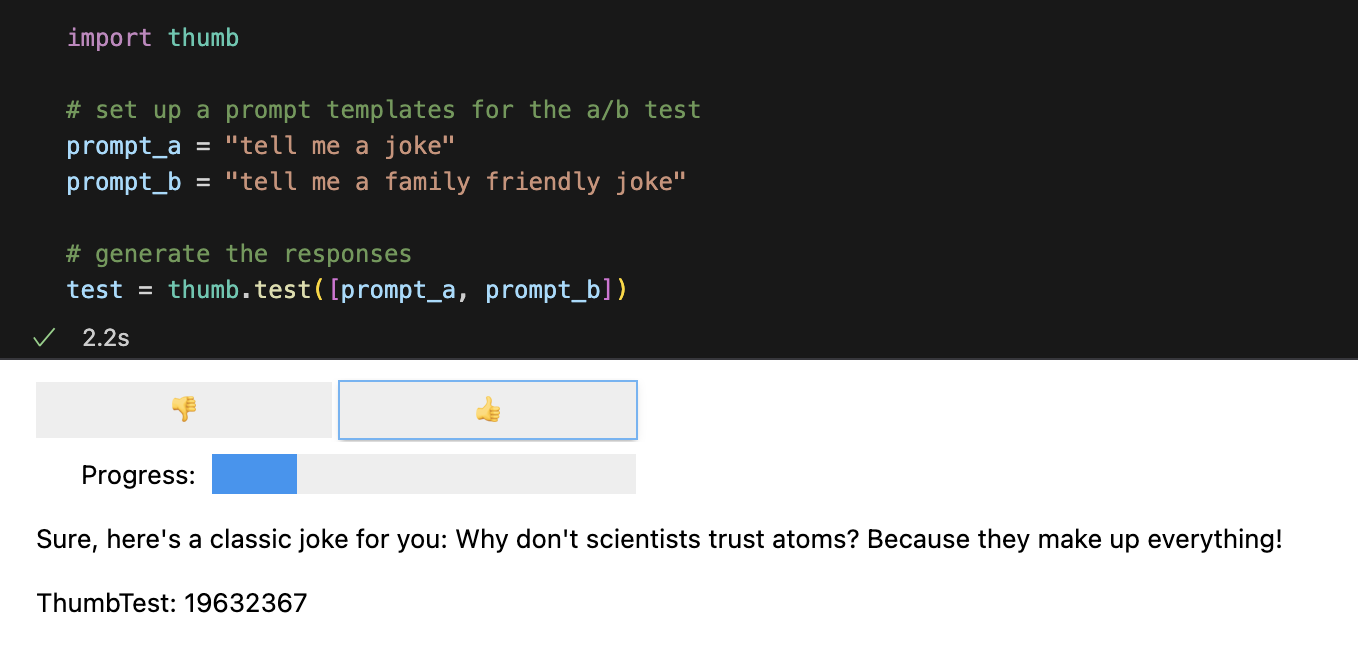
すべての応答が評価されると、次のパフォーマンス統計がプロンプト テンプレートごとに分類されて計算されます。
avg_scoreすべての実行に対する肯定的なフィードバックの割合としての量avg_tokens : プロンプトと応答全体で使用されたトークンの数avg_cost : プロンプトの平均実行コストの推定値単純なレポートがノートブックに表示され、完全なデータが CSV ファイルthumb/ThumbTest-{TestID}.csvに保存されます。

テスト ケースは、さまざまな入力変数を使用してプロンプト テンプレートをテストする場合です。たとえば、コメディアンの名前の変数を含むプロンプト テンプレートをテストする場合は、さまざまなコメディアンに対してテスト ケースを設定できます。
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke in the style of {comedian}"
prompt_b = "tell me a family friendly joke in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "comedian" : "chris rock" },
{ "comedian" : "ricky gervais" },
{ "comedian" : "robin williams" }
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )すべてのテスト ケースはすべてのプロンプト テンプレートに対して実行されるため、この例では 6 つの組み合わせ (3 つのテスト ケース x 2 つのプロンプト テンプレート) が得られ、それぞれ 10 回実行されます (OpenAI への呼び出しは合計 60 回)。すべてのテスト ケースには、プロンプト テンプレートの各変数の値が含まれている必要があります。
プロンプトには、各テスト ケースで複数の変数が含まれる場合があります。たとえば、コメディアンの名前とジョークのトピックの変数を含むプロンプト テンプレートをテストする場合は、さまざまなコメディアンとトピックのテスト ケースをセットアップできます。
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke about {subject} in the style of {comedian}"
prompt_b = "tell me a family friendly joke about {subject} in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "joe biden" , "comedian" : "ricky gervais" },
{ "subject" : "donald trump" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "ricky gervais" },
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )同じ入力データを与えた場合の各プロンプトのパフォーマンスを公平に比較するために、すべてのケースがすべてのプロンプトに対してテストされます。 4 つのテスト ケースと 2 つのプロンプトを使用すると、8 つの組み合わせ (4 つのテスト ケース x 2 つのプロンプト テンプレート) が得られ、それぞれ 10 回実行されます (OpenAI への呼び出しは合計 80 回)。
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], models = [ "gpt-4" , "gpt-3.5-turbo" ])これにより、同じ入力データが与えられた場合の各プロンプトのパフォーマンスを公平に比較するために、各モデルに対して各プロンプトが実行されます。 2 つのプロンプトと 2 つのモデルを使用すると、4 つの組み合わせ (2 プロンプト x 2 モデル) が得られ、それぞれ 10 回実行されます (OpenAI への呼び出しは合計 40 回)。
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , "tell me a funny joke about {subject}" ]
prompt_b = [ system_message , "tell me a hillarious joke {subject}" ]
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )プロンプトには文字列または文字列の配列を指定できます。プロンプトが配列の場合、最初の文字列はシステム メッセージとして使用され、残りのプロンプトはヒューマン メッセージとアシスタント メッセージの間で交互に表示されます ( [system, human, ai, human, ai, ...] )。これは、システム メッセージを含むプロンプト、またはプレウォーミング (AI を望ましい動作に導くために事前のメッセージをチャットに挿入する) を使用しているプロンプトをテストする場合に役立ちます。
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , # system
"tell me a funny joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
prompt_b = [ system_message , # system
"tell me a hillarious joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )テストが完了すると、PID、CID、モデルごとに分類された完全な評価レポートと、すべての組み合わせで分類された全体的なレポートが取得されます。 1 つのモデルまたは 1 つのケースのみをテストする場合、これらの内訳は除外されます。レポートの下部には、どの ID がどのプロンプトまたはケースに対応するかを示すキーが表示されます。
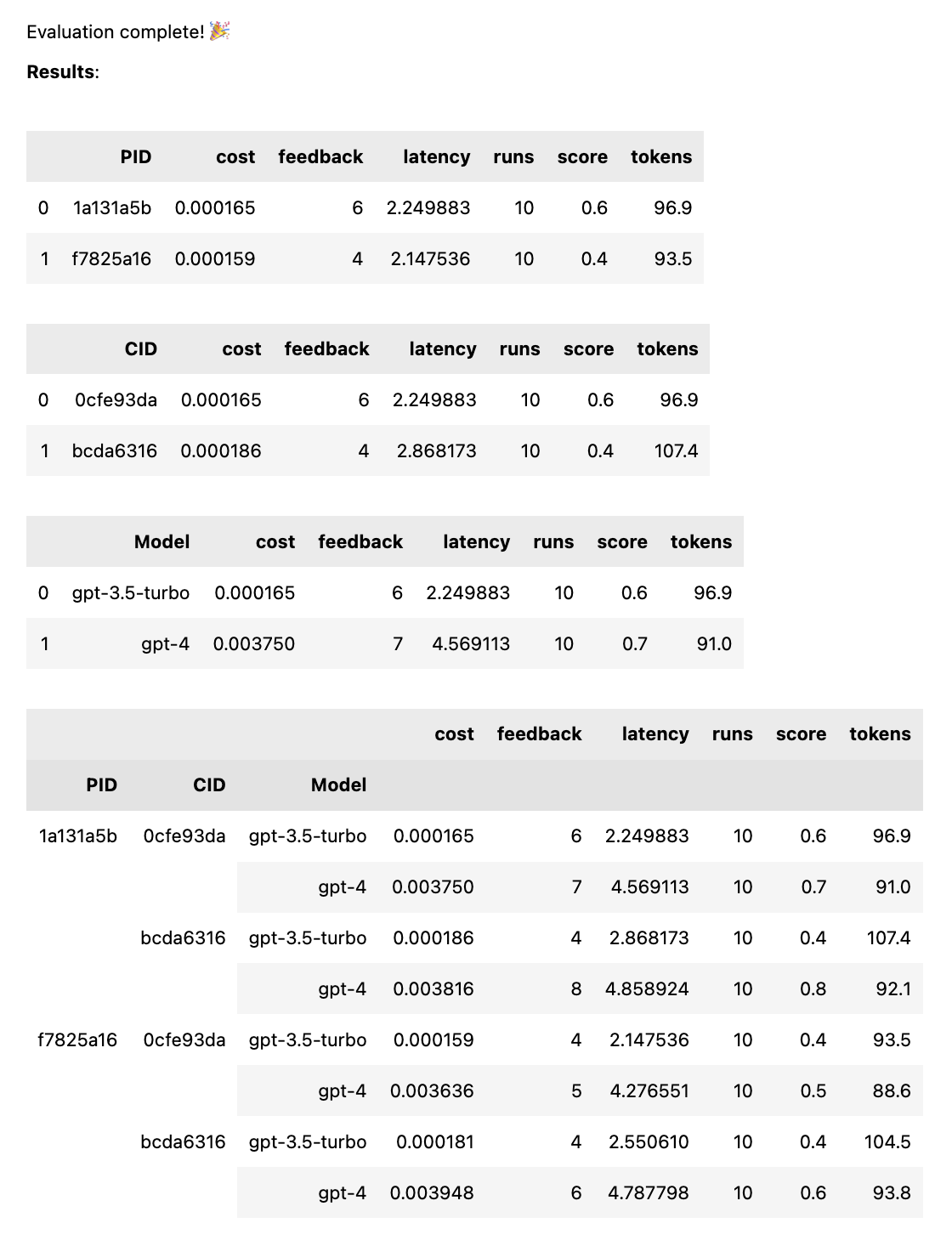
thumb.test関数は次のパラメーターを受け取ります。
None )10 )gpt-3.5-turbo ])True ) 2 つのプロンプト テンプレートと 3 つのテスト ケースを含む 10 回のテスト実行がある場合、OpenAI への呼び出しは10 x 2 x 3 = 60になります。注意: 特に GPT-4 では、コストがすぐに膨れ上がる可能性があります。
LANGCHAIN_API_KEYが環境変数 (オプション) として設定されている場合、LangSmith への Langchain トレースは自動的に有効になります。
.test()関数はThumbTestオブジェクトを返します。テストにさらにプロンプトまたはケースを追加したり、追加の回数実行したりできます。いつでもテスト データを生成、評価、エクスポートすることもできます。
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])
# add more prompts
test . add_prompts ([ "tell me a knock knock joke" , "tell me a knock knock joke about {subject}" ])
# add more cases
test . add_cases ([{ "subject" : "joe biden" }, { "subject" : "donald trump" }])
# run each prompt and case 5 more times
test . add_runs ( 5 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv ()すべてのプロンプト テンプレートはすべてのテスト ケースから同じ入力データを取得しますが、プロンプトはテスト ケース内のすべての変数を使用する必要はありません。上の例と同様に、 tell me a knock knock jokeプロンプトではsubject変数は使用されませんが、テスト ケースごとに 1 回 (変数なしで) 生成されます。
プロンプトとケースの組み合わせに対して実行の各セットが生成された後、テスト データはローカル JSON ファイルthumb/.cache/{TestID}.jsonにキャッシュされます。テストが中断された場合、またはテストを追加したい場合は、 thumb.load関数を使用して、キャッシュからテスト データをロードできます。
# load a previous test
test_id = "abcd1234" # replace with your test id
test = thumb . load ( f"thumb/.cache/ { test_id } .json" )
# run each prompt and case 2 more times
test . add_runs ( 2 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv ()プロンプトとケースの各組み合わせの実行はすべてオブジェクト (およびキャッシュ) に保存されるため、プロンプト、ケース、または実行がさらに追加されない場合、 test.generate()再度呼び出しても新しい応答は生成されません。同様に、 test.evaluate()再度呼び出しても、すでに評価した応答は再評価されず、テストが終了した場合は結果が再表示されるだけです。
ChatGPT をただいじっているだけの人々と、本番環境で AI を使用している人々の違いは評価です。 LLM は非決定的に応答するため、幅広いシナリオにわたってスケールアップしたときに結果がどのようになるかをテストすることが重要です。評価フレームワークがなければ、プロンプトで何が機能しているか (または機能していないのか) を盲目的に推測することになります。
真剣なプロンプト エンジニアは、どの入力が有用な出力または望ましい出力につながるかを、確実かつ大規模にテストして学習しています。このプロセスはプロンプト最適化と呼ばれ、次のようになります。
親指テストは、大規模な専門的な評価メカニズムと試行錯誤による盲目的な評価メカニズムの間のギャップを埋めます。プロンプトを運用環境に移行する場合、 thumb使用してプロンプトをテストすると、エッジ ケースをキャッチし、結果に関するユーザーまたはチームのフィードバックを早期に得ることができます。
これらの人々は、暇なときに楽しみのためにthumbを構築しています。 ?
ハンマーMT |


