Q Bench
1.0.0
マルチモダリティ LLM は低レベルのコンピューター ビジョンでどのように動作しますか?
Haoning Wu 1 * 、Zicheng Zhang 2 * 、Erli Zhang 1 * 、Chaofeng Chen 1 、Liang Liao 1 、
アナン・ワン1 、 チュンイー・リー2 、 ウェンシウ・スン3 、 瓊瓊・イェン3 、 グァンタオ・ザイ2 、 ウェイシ・リン1 #
1南洋理工大学、 2上海交通大学、 3センスタイムリサーチ
*平等な貢献。 #対応著者。
ICLR2024 スポットライト
紙|プロジェクトページ|ギットハブ|データ (LLVisionQA) |データ (LLDescribe) |质衡 (中国語-Q-ベンチ)


提案された Q ベンチには、低レベルの視覚に関する 3 つの領域、つまり知覚 (A1)、説明 (A2)、および評価 (A3) が含まれています。
知覚 (A1) /説明 (A2) については、2 つのベンチマーク データセット LLVisionQA/LLDescribe を収集します。
2 つのタスクについては提出ベースの評価を受け付けています。提出内容は以下の通りです。
評価 (A3) では、公開データセットを使用するため、誰でもテストできるように任意の MLLM の抽象的な評価コードを提供します。
datasets API で使用するQ-Bench-A1 (多肢選択質問付き) については、自動的にダウンロードしてdatasets API で使用できる HF 形式のデータセットに変換しました。次の手順を参照してください。
pip インストール データセット
データセットからインポートload_datasetds =load_dataset("q-future/Q-Bench-HF")print(ds["dev"][0])### {'id': 0,### 'image': <PIL .JpegImagePlugin.JpegImageFile image mode=RGB size=4160x3120>,### 'question': 'この建物の照明はどうですか?',### 'option0': '高',### 'オプション 1': '低',### 'オプション 2': '中',### 'オプション 3': '該当なし',### '質問の種類': 2,## # '質問の懸念': 3,### '正しい選択': 'B'}データセットからインポートload_datasetds =load_dataset("q-future/Q-Bench2-HF")print(ds["dev"][0])### {'id': 0,### 'image1': <PIL .Image.Image 画像モード=RGB サイズ=4032x3024>,### 'image2': <PIL.JpegImagePlugin.JpegImageFile 画像モード=RGB size=864x1152>,### 'question': '最初の画像と比較して、2 番目の画像の鮮明さはどうですか?',### 'option0': 'よりぼやけています',### 'option1': 'より明確',### 'option2': 'ほぼ同じ',### 'option3': 'N/A',### 'question_type': 2,### '質問に関する懸念': 0,### '正しい選択': 'B'}[2024/8/8] Q-bench+(Q-Bench2とも呼ばれます)の低レベルビジョン比較タスク部分がTPAMIに受理されました! Q-bench+_Dataset を使用して MLLM をテストしてください。
[2024/8/1] Q-Benchが VLMEvalKit でリリースされました。`python run.py --data Q-Bench1_VAL Q-Bench1_TEST --model InternVL2-1B --verbose' のような 1 つのコマンドで LMM をテストしてください。
[2024/6/17] Q-Bench 、 Q-Bench2 (Q-bench+) 、 A-Bench がlmms-eval に加わり、LMM のテストが容易になりました!!
[2024/6/3] A-Benchの Github リポジトリがオンラインになりました。あなたの LMM が AI 生成画像の評価に熟達しているかどうかを知りたいですか?ぜひA-Benchでテストしてみてください!!
[3/1] ここで、オープンエンドのビジュアル品質比較に向けてCo-instruct をリリースします。詳細については近日公開予定です。
[2/27] 私たちの作品Q-Insturctが CVPR 2024 に採択されました。MLLM に低レベル視覚を指導する方法の詳細を学んでみてください。
[2/23] Q-bench+(Dataset)にてQ-bench+の低レベルビジョン比較タスク部分を公開しました!
[2/10] 単一画像と画像ペアの両方で低レベル視覚に関する MLLM に挑戦する拡張 Q-bench+ をリリースします。 LeaderBoard がオンサイトにあります。お気に入りの MLLM の低レベルの視覚能力をチェックしてください。詳細については近日公開予定です。
[1/16] 私たちの研究「Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision」がICLR2024 の Spotlight Presentation に採択されました。

私たちは 3 つのクローズソース API モデル、GPT-4V-Turbo ( gpt-4-vision-preview 、利用できなくなった古いバージョンのGPT-4V の結果を置き換えます)、Gemini Pro ( gemini-pro-vision )、および Qwen でテストします。 -VL-Plus ( qwen-vl-plus )。古いバージョンと比較してわずかに改善されましたが、GPT-4V は依然としてすべての MLLM の中でトップであり、ほぼジュニアレベルの人間のパフォーマンスです。 Gemini Pro と Qwen-VL-Plus がこれに続きますが、それでも最高のオープンソース MLLM (全体で 0.65) よりも優れています。
[2024/7/18] の更新で、 BlueImage-GPT (クローズソース) の新しい SOTA パフォーマンスをリリースできることを嬉しく思います。
知覚、A1-シングル
| 参加者名 | はい、もしくは、いいえ | 何 | どうやって | ねじれ | その他 | 文脈内の歪み | 文脈内の他者 | 全体 |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0.7574 | 0.7325 | 0.5733 | 0.6488 | 0.7324 | 0.6867 | 0.7056 | 0.6893 |
BlueImage-GPT ( from VIVO New Championより) | 0.8467 | 0.8351 | 0.7469 | 0.7819 | 0.8594 | 0.7995 | 0.8240 | 0.8107 |
Gemini-Pro ( gemini-pro-vision ) | 0.7221 | 0.7300 | 0.6645 | 0.6530 | 0.7291 | 0.7082 | 0.7665 | 0.7058 |
GPT-4V-ターボ ( gpt-4-vision-preview ) | 0.7722 | 0.7839 | 0.6645 | 0.7101 | 0.7107 | 0.7936 | 0.7891 | 0.7410 |
| GPT-4V(旧バージョン) | 0.7792 | 0.7918 | 0.6268 | 0.7058 | 0.7303 | 0.7466 | 0.7795 | 0.7336 |
| 人間-1-ジュニア | 0.8248 | 0.7939 | 0.6029 | 0.7562 | 0.7208 | 0.7637 | 0.7300 | 0.7431 |
| 人間-2-先輩 | 0.8431 | 0.8894 | 0.7202 | 0.7965 | 0.7947 | 0.8390 | 0.8707 | 0.8174 |
知覚、A1 ペア
| 参加者名 | はい、もしくは、いいえ | 何 | どうやって | ねじれ | その他 | 比較する | ジョイント | 全体 |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0.6685 | 0.5579 | 0.5991 | 0.6246 | 0.5877 | 0.6217 | 0.5920 | 0.6148 |
Qwen-VL-Max ( qwen-vl-max ) | 0.6765 | 0.6756 | 0.6535 | 0.6909 | 0.6118 | 0.6865 | 0.6129 | 0.6699 |
BlueImage-GPT ( from VIVO New Championより) | 0.8843 | 0.8033 | 0.7958 | 0.8464 | 0.8062 | 0.8462 | 0.7955 | 0.8348 |
Gemini-Pro ( gemini-pro-vision ) | 0.6578 | 0.5661 | 0.5674 | 0.6042 | 0.6055 | 0.6046 | 0.6044 | 0.6046 |
GPT-4V ( gpt-4-vision ) | 0.7975 | 0.6949 | 0.8442 | 0.7732 | 0.7993 | 0.8100 | 0.6800 | 0.7807 |
| ジュニアレベルの人間 | 0.7811 | 0.7704 | 0.8233 | 0.7817 | 0.7722 | 0.8026 | 0.7639 | 0.8012 |
| 上級レベルの人間 | 0.8300 | 0.8481 | 0.8985 | 0.8313 | 0.9078 | 0.8655 | 0.8225 | 0.8548 |
また、最近いくつかの新しいオープンソース モデルを評価しており、その結果は近々リリースされる予定です。
データセットをダウンロードする 2 つの方法 (LLVisionQA&LLDescribe) が提供されるようになりました。
GitHub 経由リリース: 詳細については、リリースをご覧ください。
Huggingface データセット経由: 画像をダウンロードするには、データ リリース ノートを参照してください。
これらのデータをスムーズにテストするには、モデルを Huggingface 形式に変換することを強くお勧めします。例として、Huggingface の IDEFICS-9B-Instruct のサンプル スクリプトを参照し、カスタム モデル用にスクリプトを変更してモデルでテストします。
json 形式で結果を送信するには、 [email protected]に電子メールを送信してください。
カスタム評価スクリプトと一緒にモデル (Huggingface AutoModel または ModelScope AutoModel など) を送信することもできます。カスタム スクリプトは、LLaVA-v1.5 (A1/A2 用) およびここ (画質評価用) で機能するテンプレート スクリプトから変更できます。
中国本土以外にお住まいの場合は、 [email protected]に電子メールを送信してモデルを送信してください。中国本土にお住まいの場合は、 [email protected]に電子メールを送信してモデルを送信してください。
MLLM の低レベル知覚能力の LLVisionQA ベンチマーク データセットのスナップショットは次のとおりです。ここでリーダーボードをご覧ください。
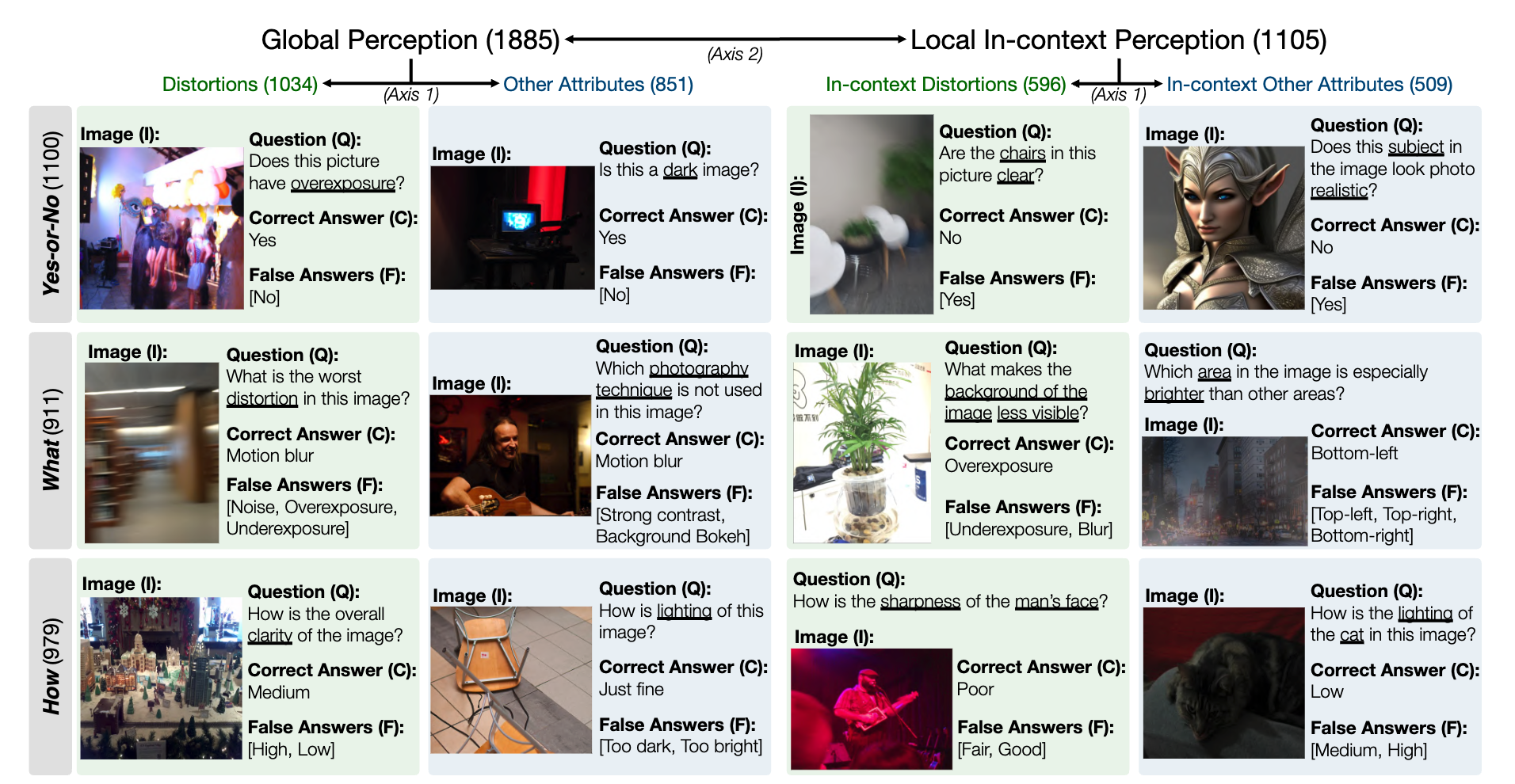
ここでは、MLLM (質問とすべての選択肢を提供) の回答精度を指標として測定します。
MLLM の低レベル記述機能の LLDescribe ベンチマーク データセットのスナップショットは次のとおりです。ここでリーダーボードをご覧ください。

ここでは、MLLM 記述の完全性、精度、関連性を指標として測定します。
MLLM が IQA の定量的スコアを予測できるという素晴らしい能力です。
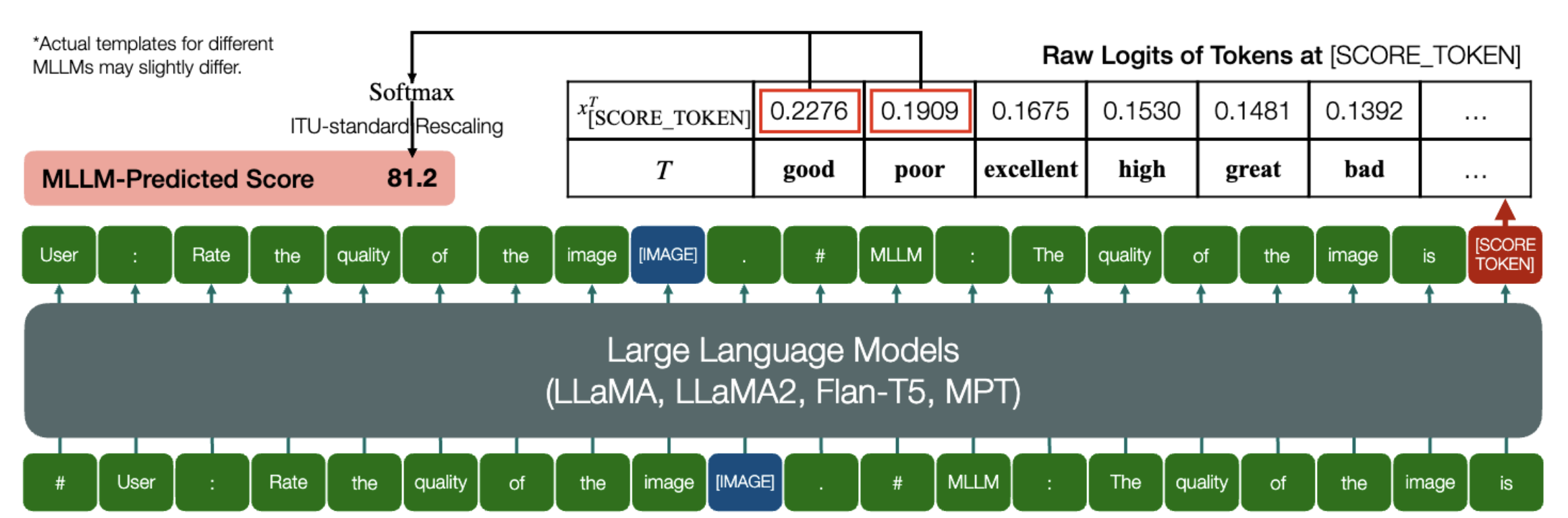
上記と同様に、モデル (因果関係言語モデルに基づく) に次の 2 つのメソッドがある限り、 embed_image_and_text (マルチモダリティ入力を許可するため)、およびforward (ロジットの計算用) があり、モデルを使用した画質評価 (IQA) が行われます。は次のように達成できます。
from PIL import Imagefrom my_mllm_model import Model、Tokenizer、embed_image_and_textmodel、tokenizer = Model()、Tokenizer()prompt = "##ユーザー: 画像の品質を評価します。n"
"##アシスタント: 画像の品質は次のとおりです。" ### この行は、MLLM のデフォルトの動作に基づいて変更できます。good_idx, Poor_idx = tokenizer(["good","poor"]).tolist()image = Image。 open("image_for_iqa.jpg")input_embeds = embed_image_and_text(画像, プロンプト)output_logits = model(input_embeds=input_embeds).logits[0,-1]q_pred = (output_logits[[good_idx, Poor_idx]] / 100).softmax(0)[0]*モデルのデフォルト形式に基づいて 2 行目を変更できることに注意してください。たとえば、Shikra の場合、「##アシスタント: 画像の品質は」は「##アシスタント: 答えは」に変更されます。 MLLM が最初に「わかりました。お手伝いしたいと思います! 画質は次のとおりです」と答えても問題ありません。これをプロンプトの 2 行目に置き換えるだけです。
さらに、IQA 上での IDEFICS の完全な実装も提供します。この MLLM で IQA を実行する方法の例を参照してください。他の MLLM も、IQA で使用できるように同じ方法で変更できます。
ベンチマークで評価した 7 つの IQA データベースの JSON 形式の Human Opinion Score (MOS) を用意しました。
詳細については、「IQA_データベース」を参照してください。
リーダーボードに移動しました。クリックして詳細をご覧ください。
ご質問がある場合は、この論文の最初の著者のいずれかにお問い合わせください。
Haoning Wu、 [email protected] 、@teowu
張紫成、 [email protected] 、@zzc-1998
アーリー・チャン、 [email protected] 、@ZhangErliCarl
私たちの研究に興味を持っていただけましたら、お気軽に論文を引用してください。
@inproceedings{wu2024qbench,author = {ウー、ハオニンとチャン、自成と張、アーリーとチェン、朝峰と廖、梁と王、アナンとリー、春儀と孫、文秀と燕、瓊と在、広島と林、 Weisi},title = {Q-Bench: 汎用基盤モデルのベンチマーク低レベルのビジョン}、本のタイトル = {ICLR}、年 = {2024}} 

