LLM PuzzleTest
1.0.0
私たちの新しいデータセットである PuzzleVQA は、単純な抽象パターンを理解する際のマルチモーダル LLM の深刻な課題を明らかにします。紙 | Webサイト
マルチモーダル推論のための斬新で挑戦的なデータセットである AlgoPuzzleVQA をリリースします。間もなく、さらに多くのマルチモーダル パズル データセットをリリースする予定です。乞うご期待!紙 | Webサイト
パズルを中心とした 2 つの新しい VQA データセットのリリースを発表できることを嬉しく思います。
どちらのデータセットでも MLLM のパフォーマンスは著しく不十分であり、マルチモーダル推論機能の大幅な強化が差し迫った必要性を浮き彫りにしています。
大規模なマルチモーダル モデルは、マルチモーダルな理解能力を統合することにより、大規模な言語モデルの優れた機能を拡張します。しかし、彼らが人間の一般的な知性と推論能力をどのようにエミュレートできるのかは明らかではありません。パターンの認識と概念の抽象化は一般知性の鍵であるため、抽象パターンに基づくパズルのコレクションである PuzzleVQA を紹介します。このデータセットを使用して、色、数、サイズ、形状などの基本概念に基づいた抽象パターンを持つ大規模なマルチモーダル モデルを評価します。最先端の大規模マルチモーダル モデルでの実験を通じて、これらのモデルは単純な抽象パターンにうまく一般化できないことがわかりました。特に、GPT-4V でもパズルの半分以上を解くことができません。大規模なマルチモーダル モデルにおける推論の課題を診断するために、視覚認識、帰納的推論、および演繹的推論に関するグラウンド トゥルース推論の説明を使用してモデルを段階的にガイドします。私たちの体系的な分析により、GPT-4V の主なボトルネックは視覚認識と帰納的推論能力の弱さであることが判明しました。この研究を通じて、私たちは大規模なマルチモーダル モデルの限界と、将来どのように人間の認知プロセスをより適切にエミュレートできるかを明らかにしたいと考えています。
PuzzleVQA はここと Huggingface でも入手できます。
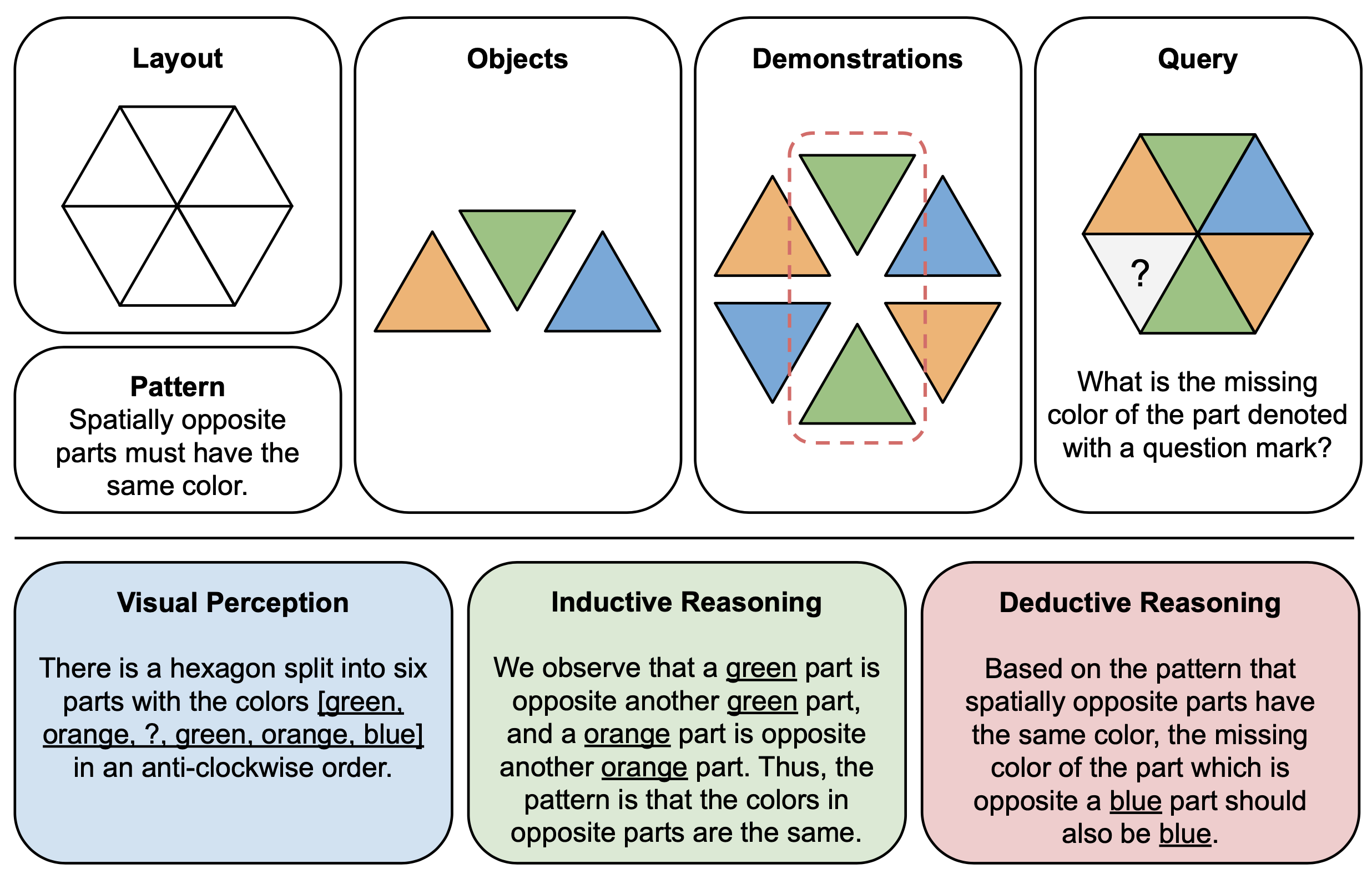
以下の図は、PuzzleVQA の色の概念を含む質問の例と、GPT-4V の不正解を示しています。一般に、解決プロセスでは視覚認識 (青)、帰納的推論 (緑)、演繹的推論 (赤) の 3 つの段階が観察されます。ここでは視覚認識が不完全で、演繹推理の際に誤りが生じた。

下図は、PuzzleVQAにおける抽象パズルの構成要素(上)と推理説明(下)の図解例を示しています。各パズル インスタンスを構築するには、まずマルチモーダル テンプレートのレイアウトとパターンを定義し、基礎となるパターンを示す適切なオブジェクトをテンプレートに追加します。解釈可能性を高めるために、パズルを解釈し、一般的な解決段階を説明するためのグラウンド トゥルース推論の説明も構築します。
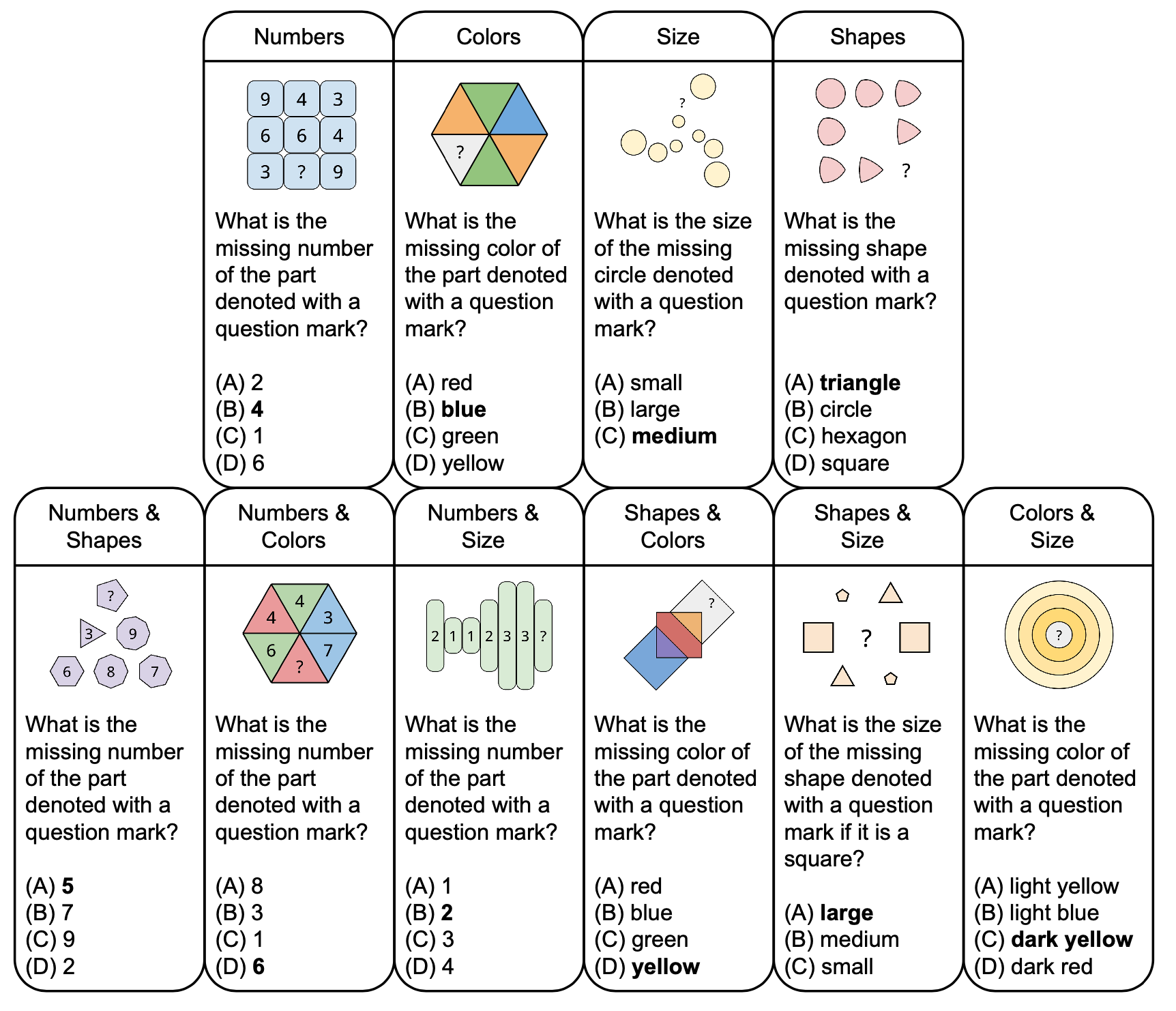
以下の図は、色やサイズなどの基本概念に基づいた、PuzzleVQA の抽象パズルの分類とサンプル質問を示しています。多様性を高めるために、私たちは単一コンセプトのパズルと二重コンセプトのパズルの両方をデザインします。
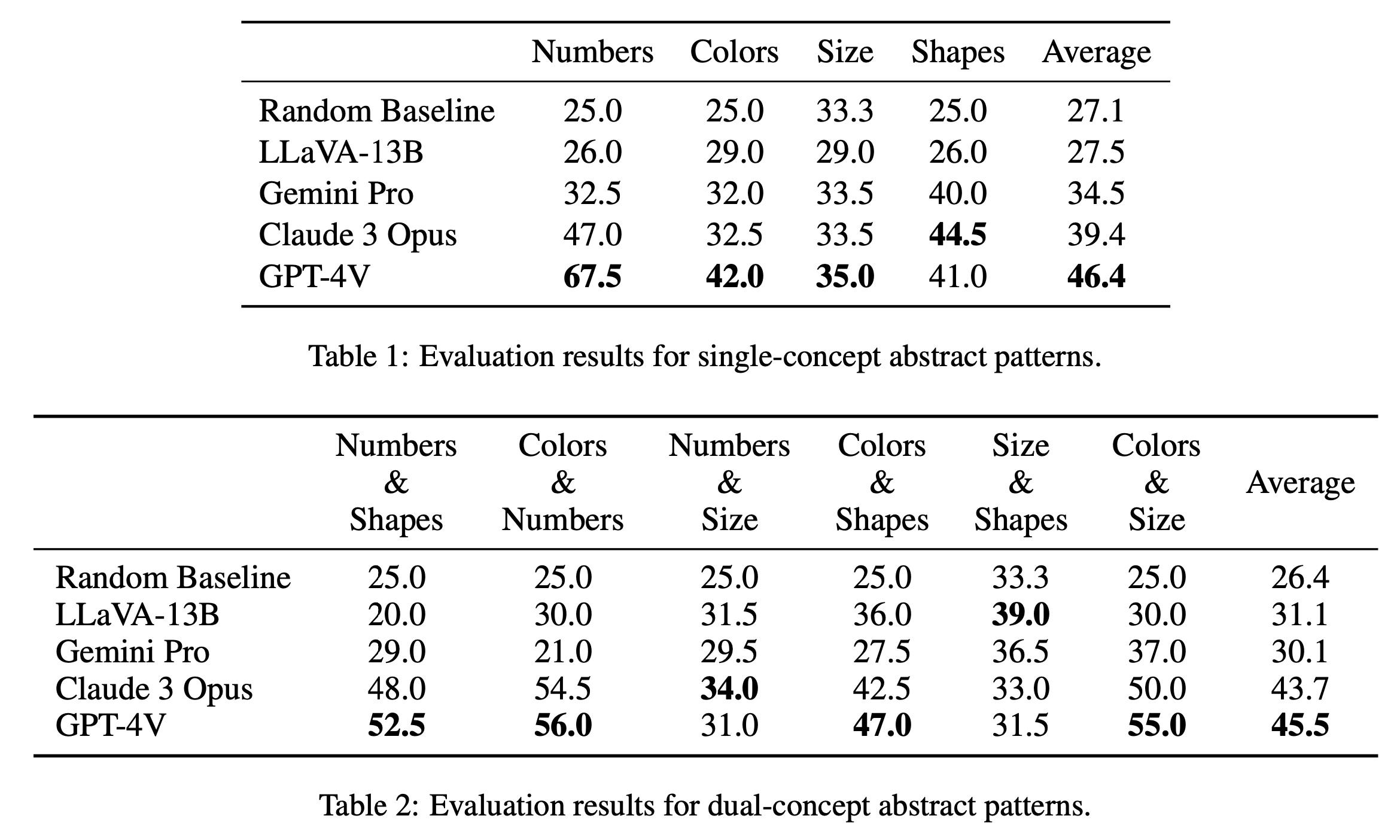
単一概念パズルと二重概念パズルの主な評価結果をそれぞれ表 1 と表 2 に報告します。表 1 に示す単一コンセプト パズルの評価結果は、オープンソース モデルとクローズドソース モデルの間でパフォーマンスに顕著な違いがあることを明らかにしています。 GPT-4V は 46.4 という最高の平均スコアで際立っており、数字、色、サイズなどの単一概念のパズルで優れた抽象パターン推論を実証しています。特に「数値」カテゴリで 67.5 というスコアで優れており、他のモデルをはるかに上回っています。これは、数学的推論タスクにおける利点によるものと考えられます (Yang et al., 2023)。クロード 3 オーパスが全体平均 39.4 で続き、最高スコア 44.5 で「シェイプ」カテゴリーでの強さを示しています。 Gemini Pro や LLaVA-13B などの他のモデルは、それぞれ平均 34.5 と 27.5 で後れを取っており、いくつかのカテゴリでランダムなベースラインと同様のパフォーマンスを示しています。
二重概念パズルの評価では、表 2 に示すように、GPT-4V が 45.5 という最高の平均スコアで再び際立っています。 「色と数字」や「色とサイズ」などのカテゴリで特に優れたパフォーマンスを示し、それぞれ 56.0 と 55.0 のスコアを獲得しました。クロード 3 オーパスが平均 43.7 で僅差で続き、「ナンバーズ & サイズ」で最高スコア 34.0 を記録し好調なパフォーマンスを示しています。興味深いことに、LLaVA-13B は、全体の平均が 31.1 と低いにもかかわらず、「サイズと形状」カテゴリのスコアが 39.0 で最高となっています。一方、Gemini Pro は、カテゴリー全体でよりバランスの取れたパフォーマンスを示していますが、全体の平均は 30.1 とわずかに低くなります。全体として、モデルは単一概念パターンと二重概念パターンで平均して同様のパフォーマンスを示すことがわかり、これは色や数字などの複数の概念を関連付けることができることを示唆しています。
@misc{chia2024puzzlevqa,
title={PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns},
author={Yew Ken Chia and Vernon Toh Yan Han and Deepanway Ghosal and Lidong Bing and Soujanya Poria},
year={2024},
eprint={2403.13315},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
視覚的な質問応答のコンテキスト内で組み立てられた、マルチモーダルなパズル解決という新しいタスクを紹介します。視覚的理解、言語理解、および複雑なアルゴリズム推論の両方を必要とするアルゴリズム パズルを解く際に、マルチモーダル言語モデルの機能に挑戦し、評価するように設計された新しいデータセット AlgoPuzzleVQA を紹介します。私たちは、ブール論理、組み合わせ論、グラフ理論、最適化、検索などの数学的およびアルゴリズム的なさまざまなトピックを網羅するパズルを作成し、視覚的なデータ解釈とアルゴリズムによる問題解決スキルの間のギャップを評価することを目的としています。データセットは人間が作成したコードから自動的に生成されます。すべてのパズルには、人間による面倒な計算を必要とせずに、アルゴリズムから正確な解決策を見つけることができます。これにより、推論の複雑さとデータセットのサイズに関して、データセットを任意にスケールアップできることが保証されます。私たちの調査により、GPT4V や Gemini などの大規模言語モデル (LLM) は、パズルを解くタスクにおいて限られたパフォーマンスしか示さないことが明らかになりました。かなりの数のパズルに対する多肢選択式の質問応答設定では、それらのパフォーマンスはほぼランダムであることがわかりました。この調査結果は、複雑な推論問題を解決するために視覚、言語、アルゴリズムの知識を統合するという課題を強調しています。
PuzzleVQA はここと Huggingface でも入手できます。
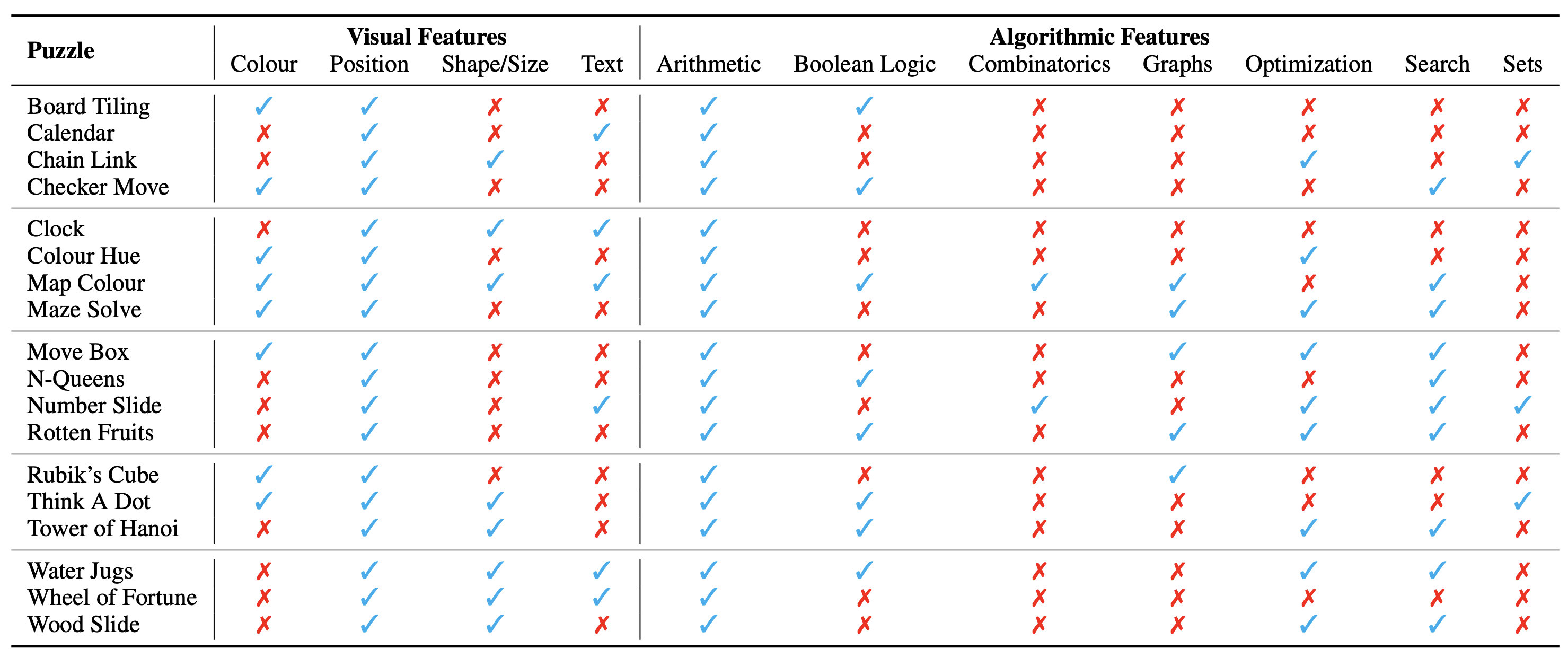
パズル/問題の構成は画像として表示され、視覚的なコンテキストを構成します。私たちは、パズルの性質に影響を与える視覚的コンテキストの次の基本的な側面を特定します。

また、パズルを解くために、つまりパズル インスタンスの質問に答えるために必要なアルゴリズムの概念も特定します。それらは次のとおりです。

ほとんどのパズルの答えを導き出すには 2 つ以上のカテゴリを使用する必要があるため、アルゴリズム カテゴリは相互に排他的ではありません。
データセットは、次の形式でここから入手できます。私たちは、さまざまなアルゴリズムおよび数学的トピックにまたがる合計 18 の異なるパズルを作成しました。これらのパズルの多くは、さまざまなレクリエーションまたは学術環境で人気があります。
18 種類のパズルから合計 1800 個のインスタンスがあります。これらのインスタンスは、パズルのさまざまなテスト ケースに似ています。つまり、入力の組み合わせ、初期状態と目標状態などが異なります。すべてのインスタンスを確実に解決するには、使用する正確なアルゴリズムを見つけて、それを正確に適用する必要があります。これは、特定のタスクを解決することを目的としたコンピューター プログラムの精度を、幅広いテスト ケースを通じて検証する方法に似ています。
現在、完全なデータセットを評価専用のベンチマークとして考慮しています。すべてのパズルの詳細な例をここに示します。
データセットを生成する手順については、こちらをご覧ください。インスタンスの数とパズルの難易度は、希望するサイズやレベルに合わせて任意に調整できます。
パズルの存在論的分類は次のとおりです。
実験的なセットアップとスクリプトは AlgoPuzzleVQA ディレクトリにあります。
私たちの取り組みが役に立ったと思われる場合は、次の記事を引用することを検討してください。
@article { ghosal2024algopuzzlevqa ,
title = { Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning } ,
author = { Ghosal, Deepanway and Han, Vernon Toh Yan and Chia, Yew Ken and and Poria, Soujanya } ,
journal = { arXiv preprint arXiv:2403.03864 } ,
year = { 2024 }
}

