llm data annotation
1.0.0
このフレームワークは、人間の専門知識と OpenAI の GPT-3.5 などの大規模言語モデル (LLM) の効率性を組み合わせて、データセットのアノテーションとモデルの改善を簡素化します。反復的なアプローチにより、データ品質の継続的な改善が保証され、その結果、このデータを使用して微調整されたモデルのパフォーマンスが保証されます。これにより、時間が節約されるだけでなく、ヒューマン アノテーターと LLM ベースの精度の両方を活用するカスタマイズされた LLM の作成が可能になります。
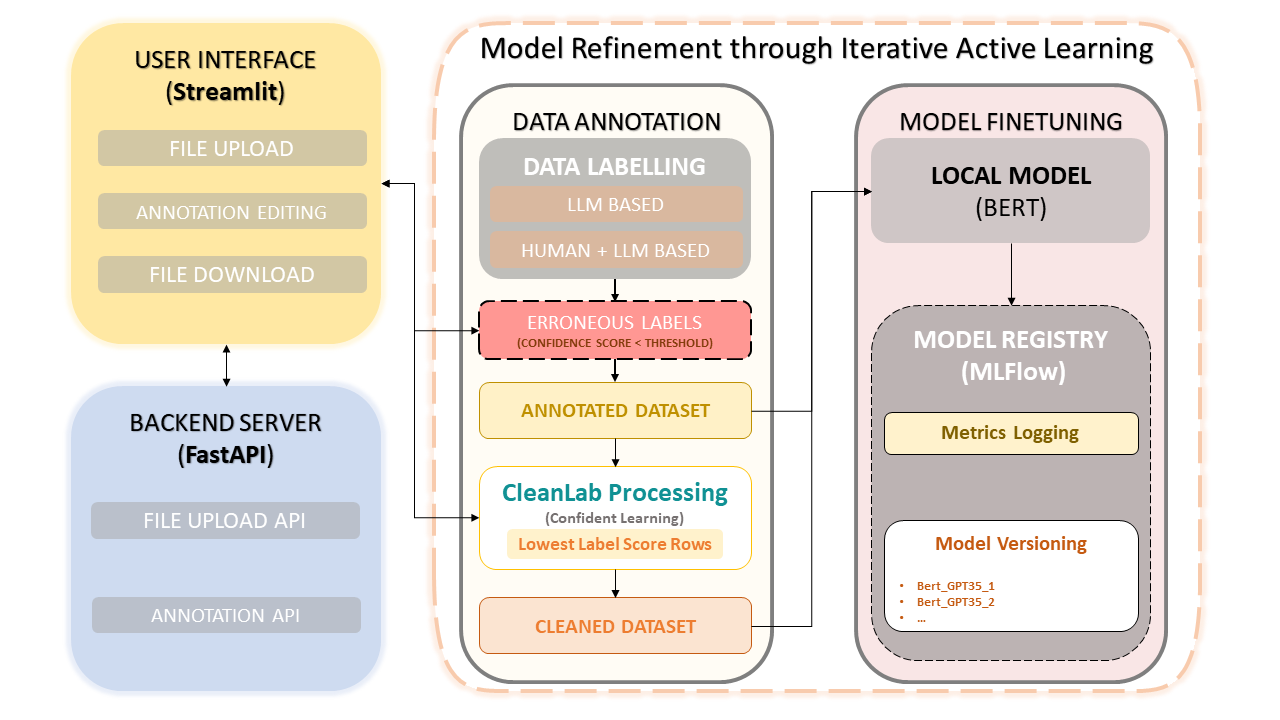
データセットのアップロードとアノテーション
注釈の手動修正
CleanLab: 自信を持った学習アプローチ
データのバージョン管理と保存
モデルのトレーニング
pip install -r requirements.txtFastAPI バックエンドを開始します。
uvicorn app:app --reloadStreamlit アプリを実行します。
streamlit run frontend.pyMLflow UI を起動する: モデル、メトリクス、登録済みモデルを表示するには、次のコマンドを使用して MLflow UI にアクセスします。
mlflow uiWeb ブラウザで提供されたリンクにアクセスします。
http://127.0.0.1:5000に移動できます。画面上のプロンプトに従って、データセットのアップロード、注釈付け、修正、トレーニングを行います。
自信を持った学習は、教師あり学習と弱い教師による画期的な手法として登場しました。ラベル ノイズの特徴付け、ラベル エラーの発見、ノイズのあるラベルでの効率的な学習を目的としています。この方法では、ノイズの多いデータを除去し、サンプルをランク付けして自信を持ってトレーニングできるようにすることで、クリーンで信頼性の高いデータセットを確保し、モデル全体のパフォーマンスを向上させます。
このプロジェクトは MIT ライセンスに基づいてオープンソース化されています。


