RWKV LM
v5
RWKVホームページ:https://www.rwkv.com
RWKV-5/6 イーグル/フィンチ論文: https://arxiv.org/abs/2404.05892
Vision の素晴らしい RWKV: https://github.com/Yaziwel/Awesome-RWKV-in-Vision
RWKV-6 3B デモ: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
RWKV-6 7B デモ: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
RWKV-6 GPT モードのデモ コード (コメントと説明付き) : https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/rwkv_v6_demo.py
RWKV-6 RNN モードのデモ: https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
参考として、Python 3.10+、torch 2.5+、cuda 12.5+、最新の deepspeed を使用しますが、 pytorch-lightning==1.9.5 のままにしてください。
RWKV-6 をトレーニングする: /RWKV-v5/ を使用し、demo-training-prepare.sh およびdemo-training-run.sh で --my_testing "x060" を使用します。
RWKV-7 をトレーニングする: /RWKV-v5/ を使用し、demo-training-prepare.sh およびdemo-training-run.sh で --my_testing "x070" を使用します。
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu121
pip install pytorch-lightning==1.9.5 deepspeed wandb ninja --upgrade
cd RWKV-v5/
./demo-training-prepare.sh
./demo-training-run.sh
(you may want to log in to wandb first)
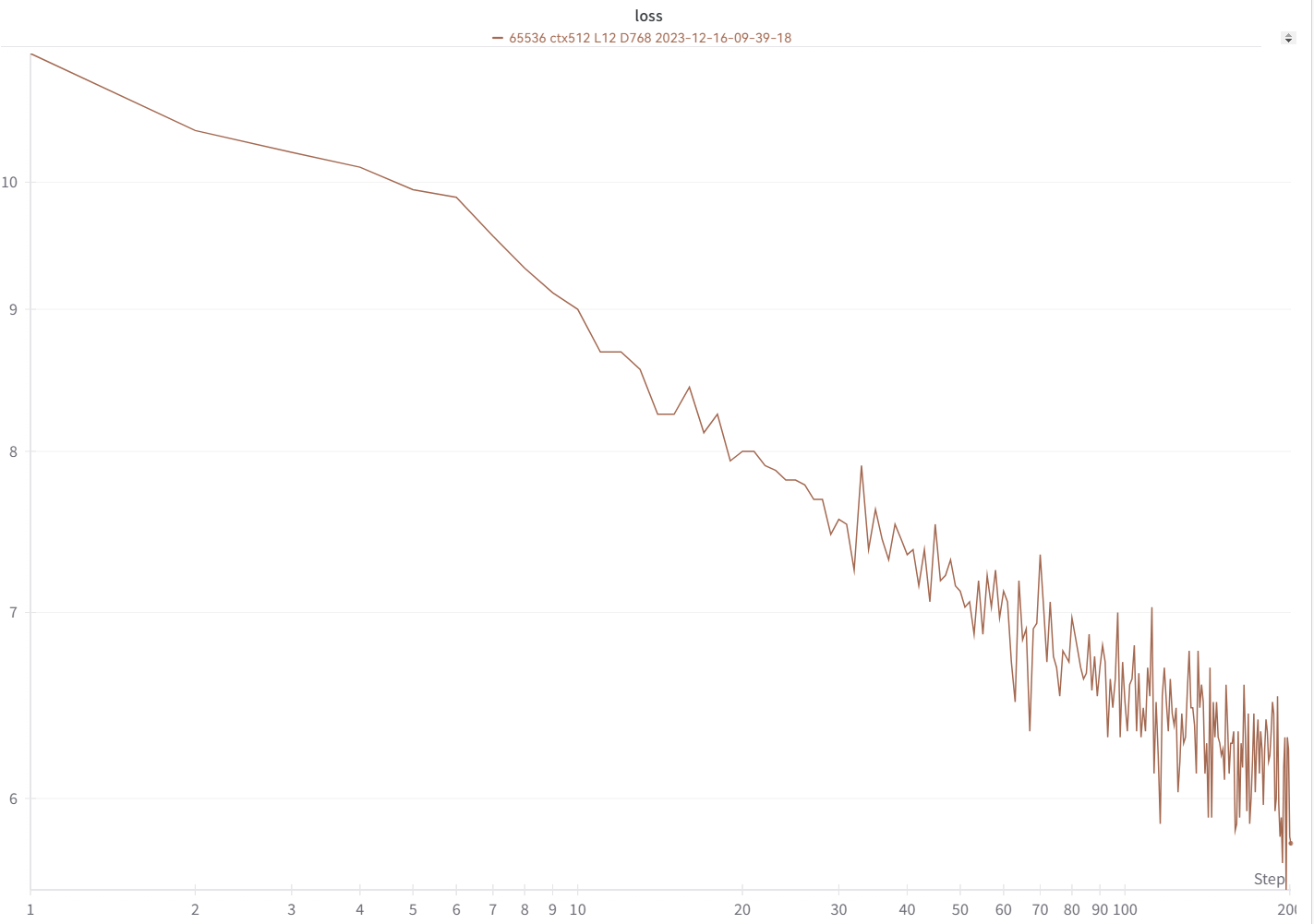
損失曲線は、これとほぼ同じで、同じ浮き沈みがあるはずです (同じ bsz と設定を使用している場合)。
https://pypi.org/project/rwkv/ を使用してモデルを実行できます (「20B_tokenizer.json」の代わりに「rwkv_vocab_v20230424」を使用します)。
https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py を使用して jsonl から binidx データを準備し、「--my_exit_tokens」と「--magic_prime」を計算します。
大規模データのはるかに高速なトークナイザー: https://github.com/cahya-wirawan/json2bin
train.py の「エポック」は「ミニエポック」(実際のエポックではありません。便宜上のものです)、1 ミニエポック = 40320 * ctx_len トークンです。
たとえば、binidx のトークンが 1498226207 で ctxlen=4096 の場合、「--my_exit_tokens 1498226207」を設定すると (epoch_count がオーバーライドされます)、1498226207/(40320 * 4096) = 9.07 ミニエポックになります。トレーナーは、「--my_exit_tokens」トークンの後に自動終了します。 「--magic_prime」を datalen/ctxlen-1 (= 1498226207/4096-1 = 365776) より小さい最大の 3n+2 素数に設定します。この場合は「--magic_prime 365759」です。
シンプル: SFT jsonl を準備 => make_data.py で SFT データを 3 回または 4 回繰り返します。繰り返しが増えると過剰適合につながります。
上級: jsonl 内で SFT データを 3 回または 4 回繰り返します (make_data.py はすべての jsonl 項目をシャッフルすることに注意してください) => 基本データ (slimpajama など) を jsonl に追加 => し、make_data.py 内で 1 回だけ繰り返します。
トレーニング スパイクを修正する: このページの「RWKV-6 スパイクを修正する」の部分を参照してください。
RWKV-5 の単純な推論: https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
RWKV-6 の単純な推論: https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
注: [state = kv + w * state] では、w は 1 に非常に近い値になる可能性があるため、すべてが fp32 になければなりません。したがって、state と w を fp32 に保持し、kv を fp32 に変換できます。
lm_eval: https://github.com/BlinkDL/ChatRWKV/blob/main/run_lm_eval.py
開発者向けチャットデモ: https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
小規模モデル/小規模データのヒント: RWKV 音楽モデルをトレーニングするときは、深くて狭い次元 (L29-D512 など) を使用し、wd とドロップアウト (wd=2 ドロップアウト=0.02 など) を適用します。 RWKV-LM ドロップアウトは非常に効果的であることに注意してください。通常の値の 1/4 を使用してください。
データには .jsonl 形式を使用します (形式については https://huggingface.co/BlinkDL/rwkv-5-world を参照してください)。
https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py を使用して、ワールド トークナイザーを使用して binidx にトークナイズし、ワールド モデルの微調整に適しています。
モデル フォルダー内のベース チェックポイントの名前を rwkv-init.pth に変更し、7B に対して --n_layer 32 --n_embd 4096 --vocab_size 65536 --lr_init 1e-5 --lr_final 1e-5 を使用するようにトレーニング コマンドを変更します。
0.1B = --n_layer 12 --n_embd 768 // 0.4B = --n_layer 24 --n_embd 1024 // 1.5B = --n_layer 24 --n_embd 2048 // 3B = --n_layer 32 --n_embd 2560 / / 7B = --n_layer 32 --n_embd 4096
現在実装は最適化されておらず、完全な SFT と同じ vram を必要とします
--train_type "states" --load_partial 1 --lr_init 1 --lr_final 0.01 --warmup_steps 10 (yes, use very high LR)
rwkv 0.8.26+ を使用して、トレーニングされた「time_state」を自動ロードします
RWKV を最初からトレーニングする場合は、最高のパフォーマンスを得るために私の初期化を試してください。 src/model.py のgenerate_init_weight()を確認します。
emb.weight => nn.init.uniform_(a=-1e-4, b=1e-4)
(Note ln0 of block0 is the layernorm for emb.weight)
head.weight => nn.init.orthogonal_(gain=0.5*sqrt(n_vocab / n_embd))
att.receptance.weight => nn.init.orthogonal_(gain=1)
att.key.weight => nn.init.orthogonal_(gain=0.1)
att.value.weight => nn.init.orthogonal_(gain=1)
att.gate.weight => nn.init.orthogonal_(gain=0.1)
att.output.weight => zero
att.ln_x.weight (groupnorm) => ((1 + layer_id) / total_layers) ** 0.7
ffn.key.weight => nn.init.orthogonal_(gain=1)
ffn.value.weight => zero
ffn.receptance.weight => zero
!!!位置埋め込みを使用している場合は、block.0.ln0 を削除し、uniform_(a=-1e-4, b=1e-4) の代わりに emb.weight のデフォルトの初期化を使用する方がよいでしょう。
最初からトレーニングする場合は、「RUN_CUDA_RWKV6(r, k, v, w, u)」の前に「k = k * torch.clamp(w, max=0).exp()」を追加し、推論コードも変更することを忘れないでください。 。収束が速くなることがわかります。
「--adam_eps 1e-18」を使用してください
スパイクが表示される場合は「--beta2 0.95」
Trainer.py では、「lr = lr * (0.01 + 0.99 * Trainer.global_step / w_step)」(元は 0.2 + 0.8)、および「--warmup_steps 20」を実行します。
大量のデータをトレーニングしている場合、「--weight_decay 0.1」は最終的な損失を改善します。これを行うときは、lr_final を lr_init の 1/100 に設定します。
RWKV は、Transformer レベルの LLM パフォーマンスを備えた RNN であり、GPT Transformer のように直接トレーニングすることもできます (並列化可能)。そして、それは100%注意を必要としません。位置 t+1 の状態を計算するには、位置 t の隠れ状態のみが必要です。 「GPT」モードを使用すると、「RNN」モードの隠れ状態を迅速に計算できます。
つまり、RNN とトランスフォーマーの長所を組み合わせたものです。優れたパフォーマンス、高速推論、VRAM の節約、高速トレーニング、「無限」の ctx_len、および自由な文の埋め込み(最終的な非表示状態を使用) です。
ワンクリックインストールと API を備えたRWKV Runner GUI https://github.com/josStorer/RWKV-Runner
すべての最新の RWKV ウェイト: https://huggingface.co/BlinkDL
HF 互換の RWKV ウェイト: https://huggingface.co/RWKV
RWKV pip パッケージ: https://pypi.org/project/rwkv/
os . environ [ "RWKV_JIT_ON" ] = '1'
os . environ [ "RWKV_CUDA_ON" ] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv . model import RWKV # pip install rwkv
model = RWKV ( model = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040' , strategy = 'cuda fp16' )
out , state = model . forward ([ 187 , 510 , 1563 , 310 , 247 ], None ) # use 20B_tokenizer.json
print ( out . detach (). cpu (). numpy ()) # get logits
out , state = model . forward ([ 187 , 510 ], None )
out , state = model . forward ([ 1563 ], state ) # RNN has state (use deepcopy if you want to clone it)
out , state = model . forward ([ 310 , 247 ], state )
print ( out . detach (). cpu (). numpy ()) # same result as abovenanoRWKV : https://github.com/BlinkDL/nanoRWKV (トレーニングにカスタム CUDA カーネルを必要とせず、あらゆる GPU/CPU で動作します)
Twitter : https://twitter.com/BlinkDL_AI
ホームページ: https://www.rwkv.com
クールなコミュニティ RWKV プロジェクト:
すべて (300 以上) RWKV プロジェクト: https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
https://github.com/OpenGVLab/Vision-RWKV ビジョン RWKV
https://github.com/feizc/Diffusion-RWKV 拡散 RWKV
https://github.com/cgisky1980/ai00_rwkv_server 最速の WebGPU 推論 (nVidia/AMD/Intel)
https://github.com/cryscan/web-rwkv ai00_rwkv_server のバックエンド
https://github.com/saharNooby/rwkv.cpp 高速 CPU/cuBLAS/CLBlast 推論: int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/state Tuning
https://github.com/RWKV/RWKV-infctx-trainer Infctx トレーナー
https://github.com/daquexian/faster-rwkv
mlc-ai/mlc-llm#1275
https://github.com/TheRamU/Fay/blob/main/README_EN.md RWKV を使用したデジタル アシスタント
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda cuda/amd/vulkan を使用した高速 GPU 推論
250 行の RWKV v6 (トークナイザーも含む): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
250 行の RWKV v5 (トークナイザーも含む): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
150 行の RWKV v4 (モデル、推論、テキスト生成): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
RWKV v4 プレプリントhttps://arxiv.org/abs/2305.13048
RWKV v4 の概要、および numpy の 100 行: https://johanwind.github.io/2023/03/23/rwkv_overview.html https://johanwind.github.io/2023/03/23/rwkv_details.html
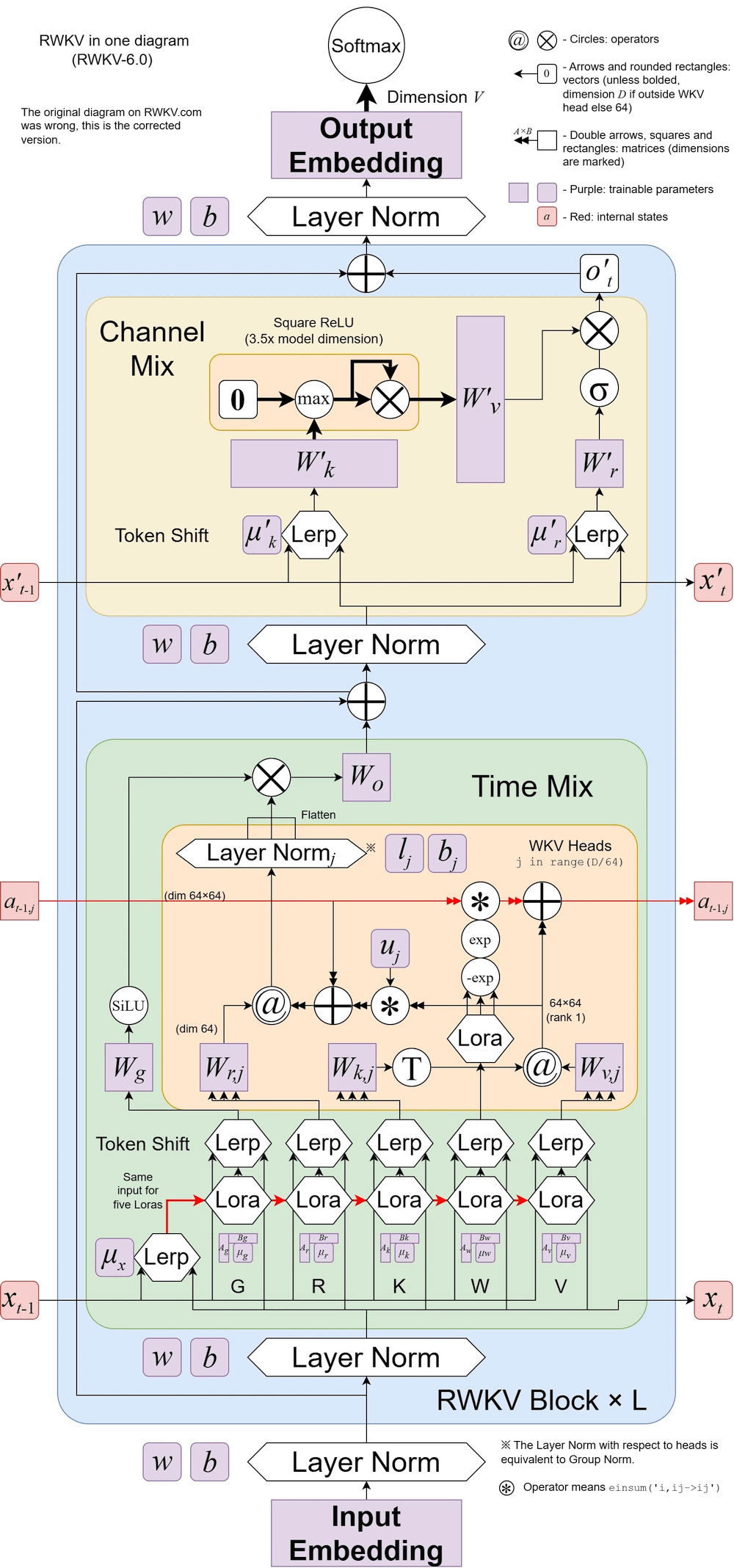
RWKV v6 の図:
RWKV を使用したクールな論文 (Spiking Neural Network): https://github.com/ridgerchu/SpikeGPT
RWKV discord https://discord.gg/bDSBUMeFpc に参加して、これを構築することを歓迎します。 (Stability と EleutherAI のおかげで) 現在、潜在的なコンピューティング (A100 40G) が豊富にあるので、興味深いアイデアがあれば実行できます。

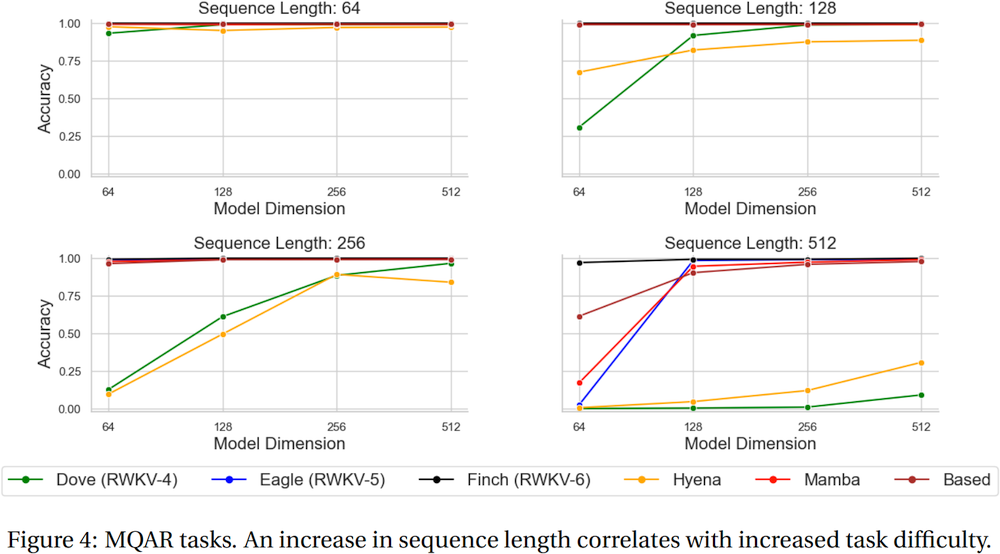
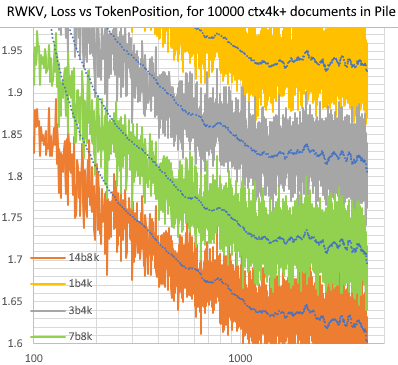
Pile 内の 10000 ctx4k+ ドキュメントの RWKV [損失 vs トークン ポジション]。 RWKV 1B5-4kはctx1500以降ほぼ平坦ですが、3B-4kと7B-4k、14B-4kは若干の傾斜があり、良くなってきています。これは、RNN は長い ctxlens をモデル化できないという古い見解の誤りを暴きます。 RWKV 100B は素晴らしいものになると予測できます。おそらく必要なのは RWKV 1T だけです :)
RWKV 14B ctx8192 とのチャット RWKV:

私は、RNN が基本モデルのより良い候補であると信じています。その理由は次のとおりです。 (1) ASIC にとってより使いやすい (kv キャッシュがない)。 (2) RL にとってよりフレンドリーです。 (3) 私たちが文章を書くとき、私たちの脳は RNN に似ています。 (4) 宇宙も RNN に似ています (局所性のため)。トランスフォーマーは非ローカル モデルです。
A40 (tf32) 上の RWKV-3 1.5B = 常に 0.015 秒/トークン、単純な pytorch コード (CUDA なし) を使用してテスト、GPU 使用率 45%、VRAM 7823M
A40 (tf32) 上の GPT2-XL 1.3B = 0.032 秒/トークン (ctxlen 1000 の場合)、HF を使用してテスト、GPU 使用率も 45% (興味深い)、VRAM 9655M
トレーニング速度: (新しいトレーニング コード) RWKV-4 14B BF16 ctxlen4096 = 8x8 A100 80G (ZERO2+CP) で 114K トークン/秒。 (古いトレーニング コード) RWKV-4 1.5B BF16 ctxlen1024 = 8xA100 40G で 106K トークン/秒。
私も画像の実験を行っています(例: https://huggingface.co/BlinkDL/clip-guided-binary-autoencoder)。RWKV は txt2img 拡散を実行できるようになります:) 私のアイデア: 256x256 rgb 画像 -> 32x32x13bit 潜在 - > RWKV を適用して 32x32 グリッドごとに遷移確率を計算します ->グリッドは独立しており、これらの確率を使用して「拡散」します。
スムーズなトレーニング - スパイクの損失なし! (lrとbszは15Gトークン前後で変化します)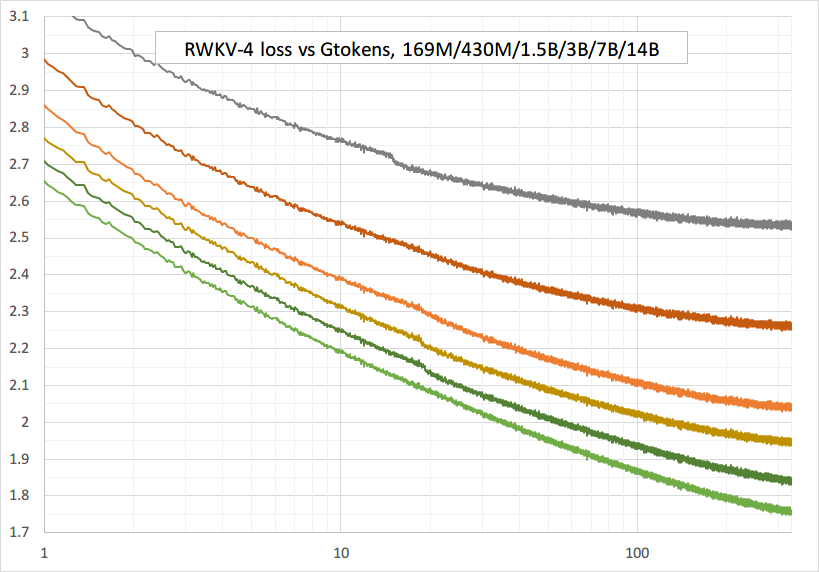
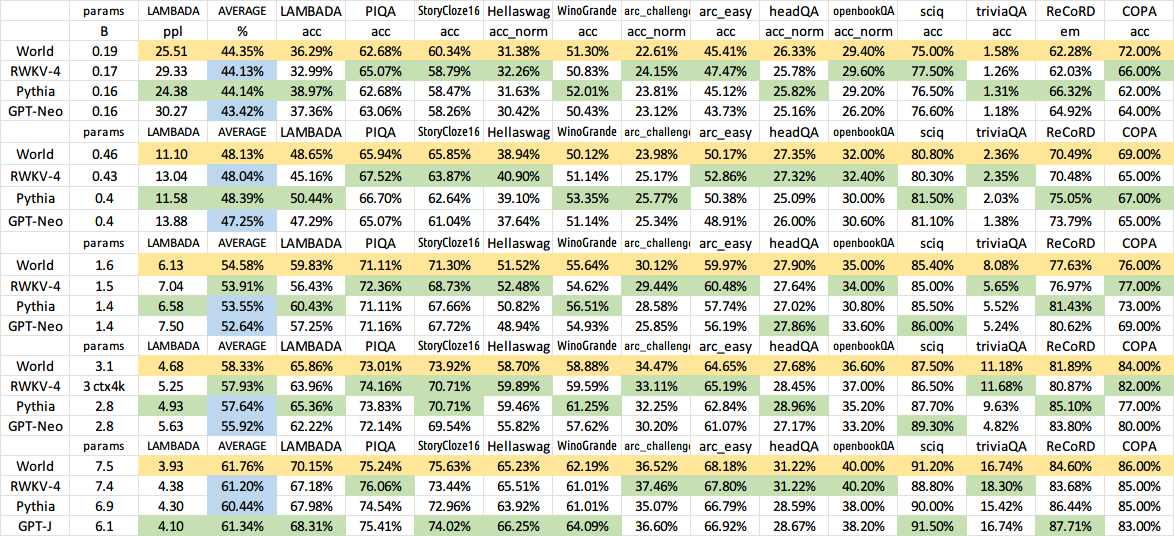
トレーニングされたモデルはすべてオープンソースになります。推論は CPU 上でも非常に高速 (行列とベクトルの乗算のみ、行列と行列の乗算はなし) なので、携帯電話で LLM を実行することもできます。
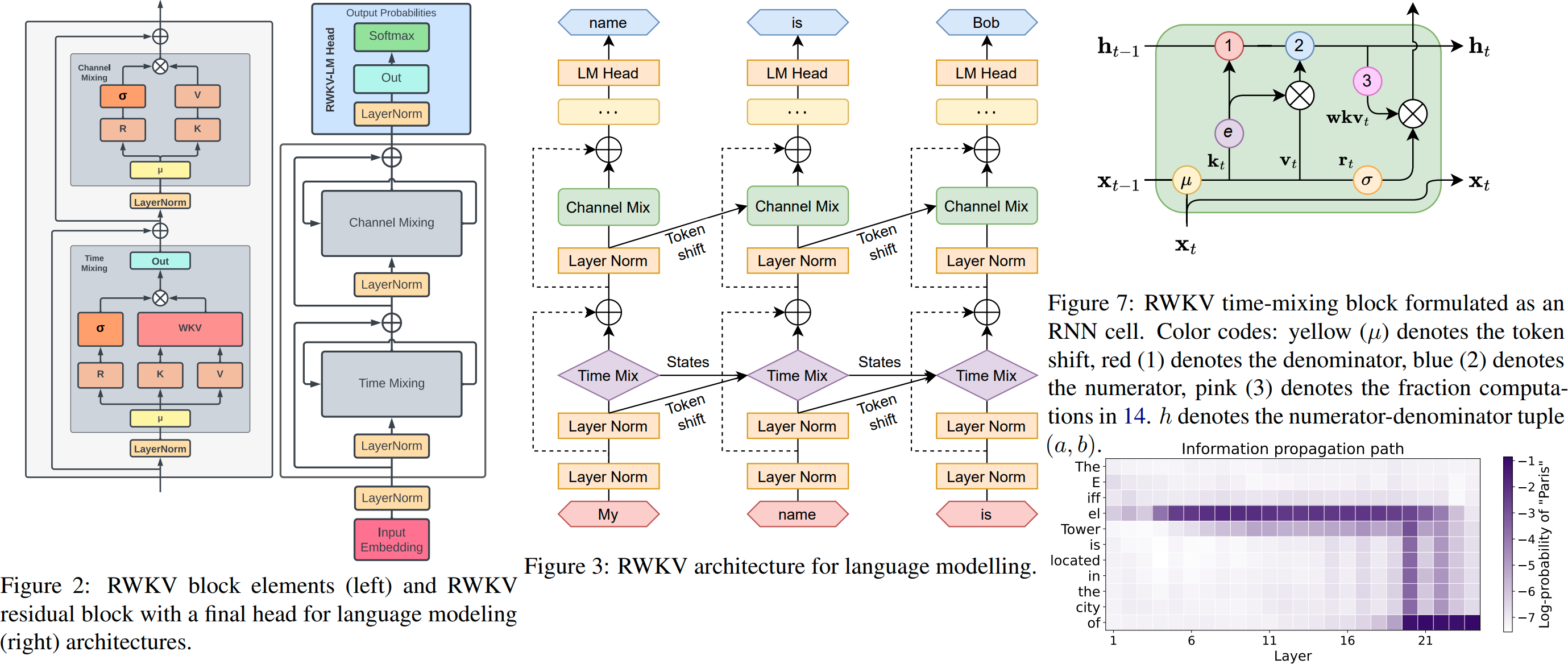
仕組み: RWKV は多数のチャネルに情報を収集します。これらのチャネルも、次のトークンに移動するにつれてさまざまな速度で減衰します。一度理解すればとても簡単です。
RWKV は、各チャネルの時間減衰がデータに依存しない (そしてトレーニング可能である) ため、並列化可能です。たとえば、通常の RNN では、チャネルの時間減衰をたとえば 0.8 から 0.5 まで調整できますが (これらは「ゲート」と呼ばれます)、RWKV では情報を W-0.8 チャネルから W-0.5 チャネルに移動するだけです。 -channel を使用して同じ効果を実現します。さらに、追加のパフォーマンスが必要な場合は、RWKV を並列化できない RNN に微調整できます (その後、前のトークンの後続の層の出力を使用できます)。

以下に私の TODO をいくつか紹介します。一緒に働きましょう:)
HuggingFace の統合 (huggingface/transformers#17230 を確認してください)、および最適化された CPU、iOS、Android、WASM、WebGL 推論。 RWKV は RNN であり、エッジ デバイスに非常に適しています。携帯電話で LLM を実行できるようにしましょう。
双方向および MLM タスク、画像、オーディオ、ビデオ トークンでテストします。 RWKV はこれによってエンコーダ-デコーダをサポートできると思います。各デコーダ トークンに対して、[デコーダの以前の隠し状態] と [エンコーダの最終的な隠し状態] の学習された混合を使用します。したがって、すべてのデコーダー トークンはエンコーダー出力にアクセスできるようになります。
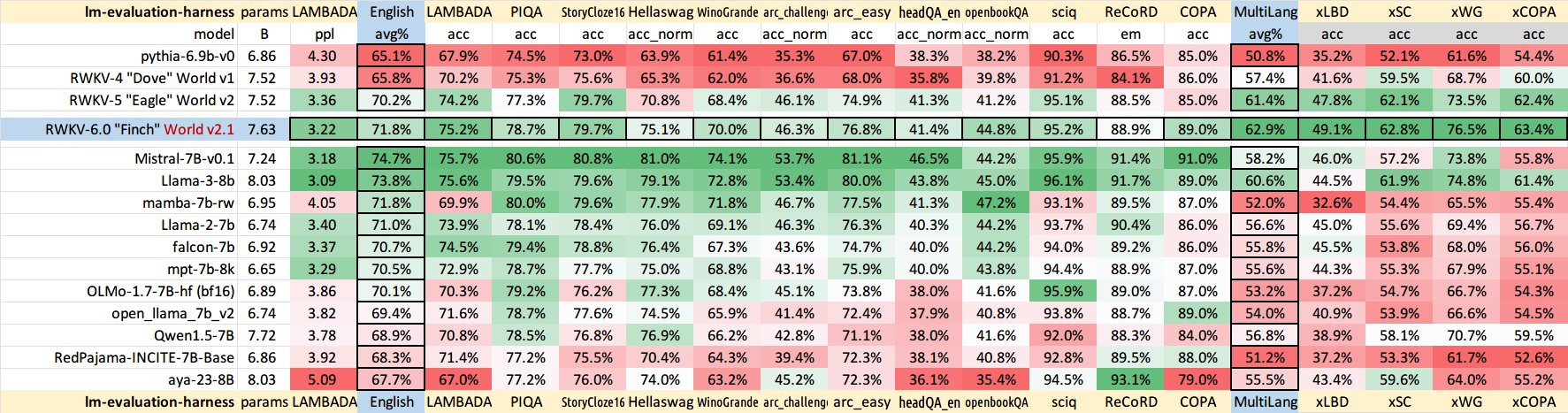
現在、RWKV-4a に 1 つの小さな追加の注意 (RWKV-4 と比較してわずか数行の追加) を加えてトレーニングし、小規模モデルのいくつかの困難なゼロショット タスク (LAMBADA など) をさらに改善します。 https://github.com/BlinkDL/RWKV-LM/commit/a268cd2e40351ee31c30c5f8a5d1266d35b41829 を参照してください。
ユーザーからのフィードバック:
これまでのところ、比較的小さな事前トレーニング データセット (約 10 GB のテキスト) でキャラクターベースのモデルを試してきましたが、結果は非常に良好で、トレーニングに非常に長い時間がかかるモデルと同様です。
親愛なる神、rwkvは速いです。ゼロからトレーニングを開始した後、別のタブに切り替えました。戻ったときには、もっともらしい英語とマオリの単語が発せられていました。電子レンジでコーヒーを淹れに行ったのですが、戻ってきたときには、完全に文法的に正しい文章が生成されていました。
Sepp Hochreiter からのツイート (ありがとう!): https://twitter.com/HochreiterSepp/status/1524270961314484227
EleutherAI Discord でも私 (BlinkDL) を見つけることができます: https://www.eleuther.ai/get-involved/
重要: deepspeed==0.7.0 pytorch-lightning==1.9.5 torch==1.13.1+cu117 および cuda 11.7.1 または 11.7 を使用してください (torch2 + deepspeed には奇妙なバグがあり、モデルのパフォーマンスに悪影響を与えることに注意してください)
https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v4neo (最新コード、v4 と互換性あり) を使用します。
これは、LLM の Q&A をテストするための優れたプロンプトです。どのモデルでも動作します: (RWKV 1.5B の ChatGPT ppls を最小化することで見つかります)
prompt = f' n Q & A n n Question: n { qq } n n Detailed Expert Answer: n ' # let the model generate after thisRWKV-4 パイル モデルを実行する: https://huggingface.co/BlinkDL からモデルをダウンロードします。 run.py に TOKEN_MODE = 'pile' を設定して実行します。 CPU (デフォルトモード) でも高速です。
RWKV-4 パイル 1.5B 用 Colab : https://colab.research.google.com/drive/1F7tZoPZaWJf1fsCmZ5tjw6sYHiFOYVWM
ブラウザー (および onnx バージョン) で RWKV-4 パイル モデルを実行します。この問題 #7 を参照してください。
RWKV-4 Web デモ: https://josephrocca.github.io/rwkv-v4-web/demo/ (注: 現時点では貪欲なサンプリングのみ)
古い RWKV-2 の場合: 0.72 BPC(dev) の enwik8 上の 27M params モデルについては、ここのリリースを参照してください。 https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v2-RNN で run.py を実行します。ブラウザで実行することもできます: https://github.com/BlinkDL/AI-Writer/tree/main/docs/eng https://blinkdl.github.io/AI-Writer/eng/ (これは使用しています) tf.js WASM シングルスレッド モード)。
pip install deepspeed==0.7.0 // pip install pytorch-lightning==1.9.5 // トーチ 1.13.1+cu117
注: 少量のデータでトレーニングする場合は、重み減衰 (0.1 または 0.01) とドロップアウト (0.1 または 0.01) を追加します。 x=x+dropout(att(x)) x=x+dropout(ffn(x)) x=dropout(x+att(x)) x=dropout(x+ffn(x)) などを試してください。
RWKV-4 を最初からトレーニングする: train.py を実行します。これはデフォルトで enwik8 データセットを使用します (https://data.deepai.org/enwik8.zip を解凍します)。
「GPT」バージョンは、パラレル化可能でトレーニングが速いため、「GPT」バージョンをトレーニングします。 RWKV-4 は外挿できるため、ctxLen 1024 でのトレーニングは ctxLen 2500 以上でも機能します。より長い ctxLen を使用してモデルを微調整することができ、より長い ctxLen にすぐに適応できます。
RWKV-4 パイル モデルの微調整: https://github.com/BlinkDL/RWKV-v2-RNN-Pile/tree/main/RWKV-v3 の「prepare-data.py」を使用して、.txt をトレインにトークン化します。 npyデータ。次に、https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/train.py を使用してトレーニングします。
src/model.py の推論コードを読み込んで、最終的な隠し状態(.xx .aa .bb)を他のタスクの忠実な文の埋め込みとして使用してみます。おそらく、.xx と .aa/.bb (.aa を .bb で割ったもの) から始める必要があります。
RWKV-4 パイル モデルを微調整するための Colab: https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb
大規模なコーパス: https://github.com/Abel2076/json2binidx_tool を使用して .jsonl を .bin および .idx に変換します。
jsonl 形式のサンプル (ドキュメントごとに 1 行):
{"text": "This is the first document."}
{"text": "HellonWorld"}
{"text": "1+1=2n1+2=3n2+2=4"}
次のようなコードによって生成されます。
ss = json.dumps({"text": text}, ensure_ascii=False)
out.write(ss + "n")
無限 ctxlen トレーニング (WIP): https://github.com/Blealtan/RWKV-LM-LoRA/tree/dev-infctx
RWKV 14B を検討してください。状態には 200 個のベクトル、つまりブロックごとに 5 つのベクトルがあります: fp16 (xx)、fp32 (aa)、fp32 (bb)、fp32 (pp)、fp16 (xx)。
状態内の異なるベクトル (xx aa bb pp xx) は意味と範囲が大きく異なるため、avg pool を使用しないでください。おそらくppを削除できるでしょう。
まず、各ベクトルの各チャネルの平均 + 標準偏差統計を収集し、それらをすべて正規化することをお勧めします (注: 正規化はデータに依存せず、さまざまなテキストから収集する必要があります)。次に、線形分類器を訓練します。
RWKV-5 はマルチヘッドですが、ここでは 1 つのヘッドを示しています。各ヘッドの LayerNorm もあります (したがって、実際には GroupNorm)。
ダイナミックミックスとダイナミックディケイ。例 (TimeMix と ChannelMix の両方に対してこれを実行します):
TIME_MIX_EXTRA_DIM = 32
self.time_mix_k_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_k_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_v_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_v_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_r_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_r_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_g_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_g_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
...
time_mix_k = self.time_mix_k.view(1,1,-1) + (x @ self.time_mix_k_w1) @ self.time_mix_k_w2
time_mix_v = self.time_mix_v.view(1,1,-1) + (x @ self.time_mix_v_w1) @ self.time_mix_v_w2
time_mix_r = self.time_mix_r.view(1,1,-1) + (x @ self.time_mix_r_w1) @ self.time_mix_r_w2
time_mix_g = self.time_mix_g.view(1,1,-1) + (x @ self.time_mix_g_w1) @ self.time_mix_g_w2
xx = self.time_shift(x)
xk = x * time_mix_k + xx * (1 - time_mix_k)
xv = x * time_mix_v + xx * (1 - time_mix_v)
xr = x * time_mix_r + xx * (1 - time_mix_r)
xg = x * time_mix_g + xx * (1 - time_mix_g)

並列化モードを使用して状態を迅速に生成し、その後、微調整された完全な RNN (トークン n の層はトークン n-1 のすべての層の出力を使用できます) を使用して順次生成します。
現在、時間減衰は 0.999^T のようになっています (0.999 は学習可能です)。これを (0.999^T + 0.1) のような値に変更します。0.1 も学習可能です。 0.1の部分は永久に保持されます。または、A^T + B^T + C = 速い減衰 + 遅い減衰 + 定数。異なる数式を使用することもできます (たとえば、減衰成分に e^K の代わりに K^2 を使用したり、正規化を行わずに使用したりすることもできます)。
一部のチャンネルでは複素数値の減衰 (つまり、減衰ではなく回転) を使用します。
トレーニング可能で推定可能な位置エンコーディングを注入しますか?
2 次元回転の他に、3 次元回転 ( SO(3) ) などの他のリー群を試すことができます。非アベル系RWKV(笑)。
RWKV はアナログ デバイスに最適です (「アナログ マトリックス ベクトル乗算」および「フォトニック マトリックス ベクトル乗算」を検索してください)。 RNN モードはハードウェアに非常に適しています (メモリ内で処理)。 SNN にすることもできます (https://github.com/ridgerchu/SpikeGPT)。量子計算に最適化できないかなぁ。
トレーニング可能な初期の隠れ状態 (xx aa bb pp xx)。
層ごと (または行/列ごと、要素ごと) LR、および Lion オプティマイザーのテスト。
self.pos_emb_x = nn.Parameter(torch.zeros((1,args.my_pos_emb,args.n_embd)))
self.pos_emb_y = nn.Parameter(torch.zeros((args.my_pos_emb,1,args.n_embd)))
...
x = x + pos_emb_x + pos_emb_y
おそらく、文脈を繰り返すだけで記憶力を向上させることができるでしょう (2 回で十分だと思います)。例:参考→参考(再)→質問→回答
目的は、vocab 内の各トークンがその長さと生の UTF-8 バイトを確実に理解できるようにすることです。
語彙内のすべてのトークンに対して a = max(len(token)) とします。 AA の定義: float[a][d_emb]
語彙内のすべてのトークンについて b = max(len_in_utf8_bytes(token)) とします。 BB を定義: float[b][256][d_emb]
vocab 内の各トークン X について、[x0, x1, ..., xn] をその生の UTF-8 バイトとします。埋め込み EMB(X) にいくつかの追加の値を追加します。
EMB(X) += AA[len(X)] + BB[0][x0] + BB[1][x1] + ... + BB[n][xn] (注: AA BB は学習可能な重みです)
トークン化を改善するアイデアがあります。一部のチャネルに意味を持たせるためにハードコーディングできます。例:
チャンネル0 = 「スペース」
チャンネル 1 = 「最初の文字を大文字にする」
チャンネル 2 = 「すべての文字を大文字にする」
したがって:
「abc」の埋め込み: [0, 0, 0, x0, x1, x2 , ..]
「abc」の埋め込み: [1, 0, 0, x0, x1, x2, ..]
「Abc」の埋め込み: [1, 1, 0, x0, x1, x2, ..]
「ABC」の埋め込み: [0, 0, 1, x0, x1, x2, ...]
……
したがって、埋め込みの大部分を共有することになります。そして、「abc」のすべてのバリエーションの出力確率を迅速に計算できます。
注: 上記の方法は、p(" xyz") / p("xyz") がどの "xyz" でも同じであると仮定していますが、これは間違っている可能性があります。
より良い方法: emb_space emb_capitalize_first emb_capitalize_all を emb の関数として定義します。
おそらくベスト: 'abc' ' abc' などに埋め込みの最後の 90% を共有させます。
現時点では、すべてのトークナイザーは、「abc」、「abc」、「Abc」などのすべてのバリエーションを表すにはアイテムが多すぎます。さらに、これらのバリエーションの一部がデータセット内でまれである場合、モデルはこれらが実際に類似していることを検出できません。ここで紹介する方法でこれを改善できます。これを新しいバージョンの RWKV でテストする予定です。
例 (1 ラウンド Q&A):
すべての Wiki ドキュメントの最終状態を生成します。
任意のユーザー Q に対して、最適な Wiki ドキュメントを見つけて、その最終状態を初期状態として使用します。
モデルをトレーニングして、任意のユーザー Q に最適な初期状態を直接生成します。
ただし、複数ラウンドの Q&A の場合、これは少し難しくなる可能性があります:)
RWKV は Apple の AFT (https://arxiv.org/abs/2105.14103) からインスピレーションを得ています。
さらに、次のような私のトリックをいくつか使用しています。
SmallInitEmb: https://github.com/BlinkDL/SmallInitEmb (すべてのトランスフォーマーに適用可能)。埋め込みの品質を高め、Post-LN を安定させます (私が使用しているものです)。
トークンシフト: https://github.com/BlinkDL/RWKV-LM#token-shift-time-shift-mixing (すべてのトランスフォーマーに適用可能)、特に文字レベルのモデルに役立ちます。
Head-QK: https://github.com/BlinkDL/RWKV-LM#the-head-qk-trick-learning-to-copy-and-avoid-tokens (すべてのトランスフォーマーに適用されます)。注: これは便利ですが、100% RNN を維持するために Pile モデルで無効にしました。
FFN の追加 R ゲート (すべてのトランスに適用)。私もPrimerのreluSquaredを使用しています。
初期化の改善: ほとんどの行列を 0 に初期化します (https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v2-RNN/src/model.py の RWKV_Init を参照)。
より速くより良い収束を実現するために、いくつかのパラメーターを小さなモデルから大きなモデルに転送することができます (注: 並べ替えと平滑化も行います)。 /)。
私の CUDA カーネル: https://github.com/BlinkDL/RWKV-CUDA トレーニングを高速化します。

abcd 係数は連携して時間減衰曲線 [X, 1, W, W^2, W^3, ...] を作成します。
「位置 2 のトークン」と「位置 3 のトークン」の式を書き出すと、アイデアが得られます。
kv / k は記憶メカニズムです。チャネル内で W が 1 に近い場合、k の高いトークンは長期間記憶される可能性があります。
R ゲートはパフォーマンスにとって重要です。 k = このトークンの情報強度 (将来のトークンに渡される)。 r = このトークンに情報を適用するかどうか。
SA および FF レイヤーの R / K / V に異なるトレーニング可能な TimeMix 係数を使用します。例:
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )postLN の代わりに preLN を使用します (より安定し、より高速な収束):
if self . layer_id == 0 :
x = self . ln0 ( x )
x = x + self . att ( self . ln1 ( x ))
x = x + self . ffn ( self . ln2 ( x ))RWKV-3 GPT モードの構成要素は、通常の preLN GPT の構成要素と似ています。
唯一の違いは、埋め込み後の追加の LN です。トレーニングの終了後に、この LN を埋め込みに吸収できることに注意してください。
x = self . emb ( idx ) # input: idx = token indices
x = self . ln_emb ( x ) # extra LN after embedding
x = x + self . att_0 ( self . ln_att_0 ( x )) # preLN
x = x + self . ffn_0 ( self . ln_ffn_0 ( x ))
...
x = x + self . att_n ( self . ln_att_n ( x ))
x = x + self . ffn_n ( self . ln_ffn_n ( x ))
x = self . ln_head ( x ) # final LN before projection
x = self . head ( x ) # output: x = logits私のトリック https://github.com/BlinkDL/SmallInitEmb を利用するには、emb を nn.init.uniform_(a=-1e-4, b=1e-4) などの小さな値に初期化することが重要です。
1.5B RWKV-3 の場合、8 * A100 40G で Adam (wd なし、ドロップアウトなし) オプティマイザーを使用します。
バッチSz = 32 * 896、ctxLen = 896。私はtf32を使用しているため、バッチSzは少し小さいです。
最初の 15B トークンでは、LR は 3e-4 に固定され、beta=(0.9, 0.99) になります。
次に、beta=(0.9, 0.999) を設定し、LR の指数関数的減衰を実行し、332B トークンで 1e-5 に達します。
RWKV-3 には通常の意味では何の注意もありませんが、とにかくこのブロックを ATT と呼びます。
B , T , C = x . size () # x = (Batch,Time,Channel)
# Mix x with the previous timestep to produce xk, xv, xr
xx = self . time_shift ( x ) # self.time_shift = nn.ZeroPad2d((0,0,1,-1))
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# Use xk, xv, xr to produce k, v, r
k = self . key ( xk ). transpose ( - 1 , - 2 )
v = self . value ( xv ). transpose ( - 1 , - 2 )
r = self . receptance ( xr )
k = torch . clamp ( k , max = 60 ) # clamp k to avoid overflow
k = torch . exp ( k )
kv = k * v
# Compute the W-curve = [e^(-n * e^time_decay), e^(-(n-1) * e^time_decay), ..., 1, e^(time_first)]
self . time_w = torch . cat ([ torch . exp ( self . time_decay ) * self . time_curve . to ( x . device ), self . time_first ], dim = - 1 )
w = torch . exp ( self . time_w )
# Use W to mix kv and k respectively. Add K_EPS to wk to avoid divide-by-zero
if RUN_DEVICE == 'cuda' :
wkv = TimeX . apply ( w , kv , B , C , T , 0 )
wk = TimeX . apply ( w , k , B , C , T , K_EPS )
else :
w = w [:, - T :]. unsqueeze ( 1 )
wkv = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( kv ), w , groups = C )
wk = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( k ), w , groups = C ) + K_EPS
# The RWKV formula
rwkv = torch . sigmoid ( r ) * ( wkv / wk ). transpose ( - 1 , - 2 )
rwkv = self . output ( rwkv ) # final output projectionself.key、self.receptance、self.output 行列はすべてゼロに初期化されます。
time_mix、time_decay、time_first ベクトルは、より小さなトレーニング済みモデルから転送されます (注: 並べ替えと平滑化も行っています)。
FFN ブロックには、通常の GPT と比較して 3 つのトリックがあります。
私のtime_mixトリック。
Primer ペーパーの sqReLU。
追加のレセプタンス ゲート (ATT ブロックのレセプタンス ゲートと同様)。
# Mix x with the previous timestep to produce xk, xr
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# The usual FFN operation
k = self . key ( xk )
k = torch . square ( torch . relu ( k )) # from the Primer paper
kv = self . value ( k )
# Apply an extra receptance-gate to kv
rkv = torch . sigmoid ( self . receptance ( xr )) * kv
return rkvself.value、self.receptance 行列はすべてゼロに初期化されます。

F[t]をtにおけるシステム状態とする。
x[t] を t における新しい外部入力とする。
GPT では、F[t+1] を予測するには、F[0]、F[1]、...F[t] を考慮する必要があります。したがって、長さ T シーケンスを生成するには O(T^2) かかります。
GPT の簡略化された式は次のとおりです。
理論的には非常に有能ですが、それは通常のオプティマイザーでその機能を完全に活用できることを意味するものではありません。私たちの現在の方法では、損失の状況は難しすぎるのではないかと思います。
RWKV の簡略化された式と比較してください (並列モード。Apple の AFT に似ています)。
R、K、V はトレーニング可能な行列、W はトレーニング可能なベクトル (各チャネルの時間減衰係数) です。
GPT では、F[i] から F[t+1] への寄与は によって重み付けされます。
RWKV-2 では、F[i] から F[t+1] への寄与は によって重み付けされます。
ここでオチが生まれます。これを RNN (再帰式) に書き換えることができます。注記:
したがって、次のことを確認するのは簡単です。
ここで、A[t] と B[t] はそれぞれ前のステップの分子と分母です。
W は対角行列を繰り返し適用するようなものであるため、RWKV はパフォーマンスが高いと思います。 (P^{-1} DP)^n = P^{-1} D^n P であることに注意してください。したがって、これは一般的な対角化可能な行列を繰り返し適用することに似ています。
さらに、これを連続 ODE (状態空間モデルに少し似ています) に変えることもできます。それについては後で書きます。
LM(トランス、RWKVなど)を使用して[テキスト --> 32x32 RGB画像]のアイデアがあります。すぐにテストします。
まず、LM 損失 (L2 損失ではなく) なので、画像はぼやけません。
次に、色の量子化です。たとえば、R/G/B には 8 レベルのみが許可されます。この場合、画像語彙のサイズは 2^24 ではなく、8x8x8 = 512 (ピクセルごと) になります。したがって、32x32 RGB 画像 = vocab512 (画像トークン) の len1024 シーケンス、これは通常の LM の典型的な入力です。 (後で、拡散モデルを使用してアップサンプリングして RGB888 画像を生成できます。これには LM も使用できるかもしれません。)
3 番目に、モデルが理解しやすい 2D 位置埋め込みです。たとえば、ワンホット X 座標と Y 座標を最初の 64(=32+32) チャネルに追加します。たとえば、ピクセルが x=8、y=20 にある場合、チャネル 8 とチャネル 52 (=32+20) に 1 を加算します。さらにおそらく、浮動小数点 X および Y 座標 (0 ~ 1 の範囲に正規化) を別の 2 つのチャネルに追加することもできます。その他定期pos。エンコーディングも役立つかもしれません(テストします)。
最後に、RandRound の場合


