EasyEdit
1.0.0

大規模な言語モデル向けの使いやすいナレッジ編集フレームワーク。
インストール • クイックスタート • ドキュメント • ペーパー • デモ • ベンチマーク • 寄稿者 • スライド • ビデオ • AK による特集
2024 年 10 月 23 日、EasyEdit は、ステアリング編集から LLM および MLLM の幻覚を軽減するための制約付きデコード手法を統合し、詳細情報は DoLa および DeCo で入手できます。
2024-09-26、??私たちの論文「WISE: Re Thinking the Knowledge Memory for Lifelong Model Editing of Large Language Models」がNeurIPS 2024に受理されました。
2024-09-20、??私たちの論文「大規模言語モデルの知識メカニズム: 調査と展望」および「大規模言語モデルの概念的知識の編集」がEMNLP 2024 Findingsに受理されました。
2024 年 7 月 29 日、EasyEdit に新しいモデル編集アルゴリズム EMMET が追加されました。これは、ROME をバッチ設定に一般化します。これにより、基本的に、ROME 損失関数を使用してバッチ編集を行うことができます。
2024 年 7 月 23 日、新しい論文「大規模言語モデルにおける知識メカニズム: 調査と展望」をリリースします。この論文では、大規模言語モデルで知識がどのように取得、利用、進化するかをレビューします。この調査は、LLM の知識を正確かつ効率的に操作 (編集) するための基本的なメカニズムを提供する可能性があります。
2024年6月4日、?? EasyEdit Paper は、 ACL 2024システム デモンストレーション トラックに受け入れられました。
2024 年 6 月 3 日、私たちは「WISE: 大規模言語モデルの生涯モデル編集のための知識記憶の再考」というタイトルの論文を発表し、新しい編集タスクである継続的知識編集と、それに対応する WISE と呼ばれる生涯編集手法を紹介しました。
2024 年 4 月 24 日、EasyEdit はLlama3-8B の ROME メソッドのサポートを発表しました。ユーザーは、トランスフォーマー パッケージをバージョン 4.40.0 に更新することをお勧めします。
2024 年 3 月 29 日、EasyEdit はGRACE のロールバック サポートを導入しました。詳細については、EasyEdit のドキュメントを参照してください。今後のアップデートには、他のメソッドのロールバック サポートが徐々に含まれる予定です。
2024 年 3 月 22 日、 「ナレッジ編集による大規模言語モデルの無毒化」というタイトルの新しい論文が、SafeEdit という新しいデータセットと DINM と呼ばれる新しい無毒化手法とともにリリースされました。
2024 年 3 月 12 日、 「大規模言語モデルのための概念知識の編集」というタイトルの別の論文がリリースされ、ConceptEdit という名前の新しいデータセットが紹介されました。
2024 年 3 月 1 日、EasyEdit はFT-Mと呼ばれる新しいメソッドのサポートを追加しました。この方法には、ターゲットの回答に対するクロスエントロピー損失を使用し、元のテキストをマスクして、特定の MLP 層をトレーニングすることが含まれます。これは、ROME のFT-L実装よりも優れたパフォーマンスを発揮します。第 173 号の著者のアドバイスに感謝します。
2024 年 2 月 27 日、EasyEdit は InstructEdit と呼ばれる新しいメソッドのサポートを追加しました。技術的な詳細は論文「InstructEdit: 大規模言語モデルのための命令ベースの知識編集」で提供されています。
Accelerate使用した複数の GPU でのモデル編集のサポートが追加されました。大規模言語モデルのための知識編集の包括的な研究 [論文][ベンチマーク][コード]
IJCAI 2024 チュートリアル Google ドライブ
COLING 2024 チュートリアル Google ドライブ
AAAI 2024 チュートリアル Google ドライブ
AACL 2023 チュートリアル [Google ドライブ] [Baidu Pan]
編集の実演もございます。 GIF ファイルは Terminalizer によって作成されます。
便利な Jupyter Notebook を提供します。これにより、米国大統領に関する LLM の知識を編集し、バイデンからトランプに切り替えたり、バイデンに戻すこともできます。これには、WISE、AlphaEdit、AdaLoRA、プロンプトベースの編集などの方法が含まれます。
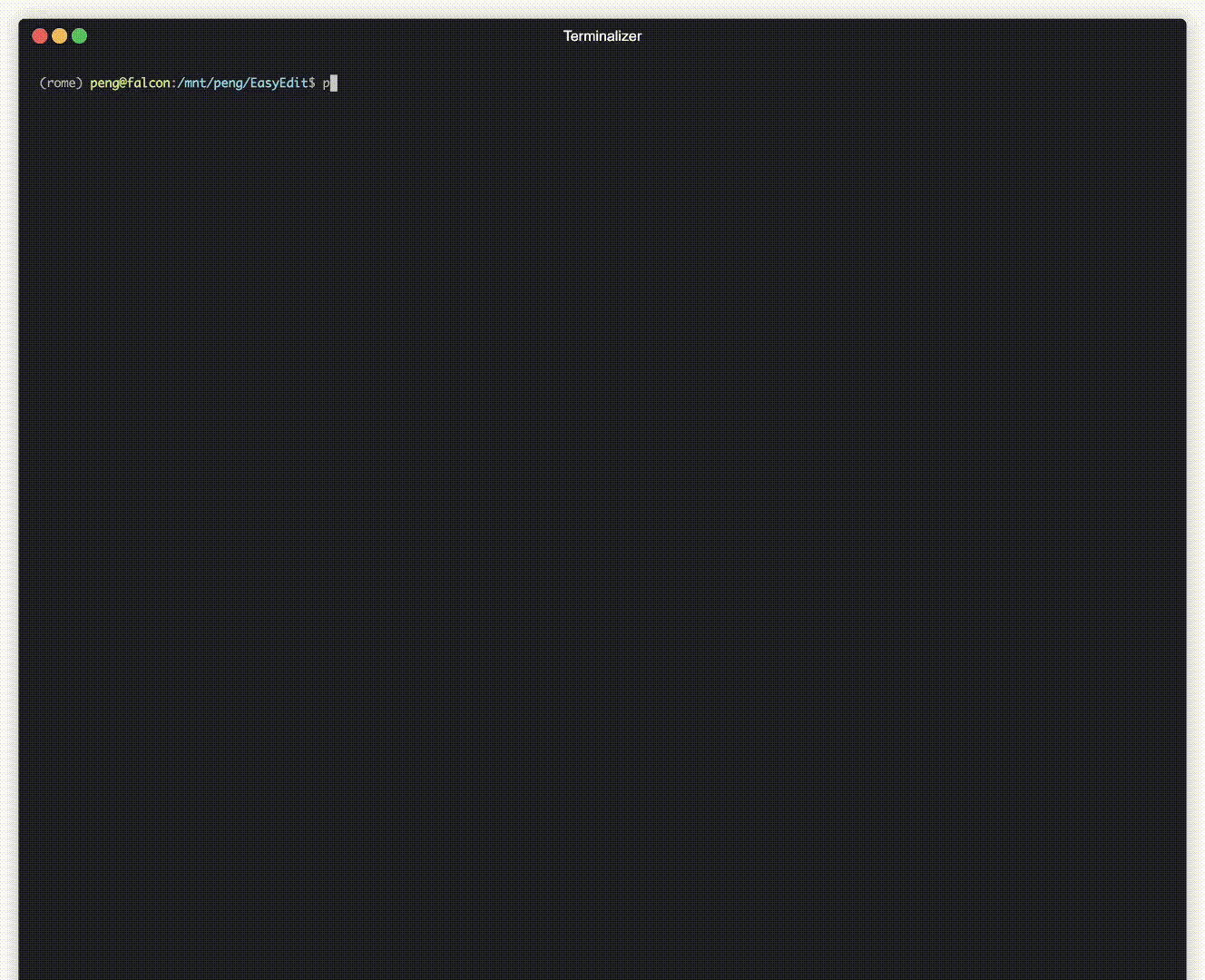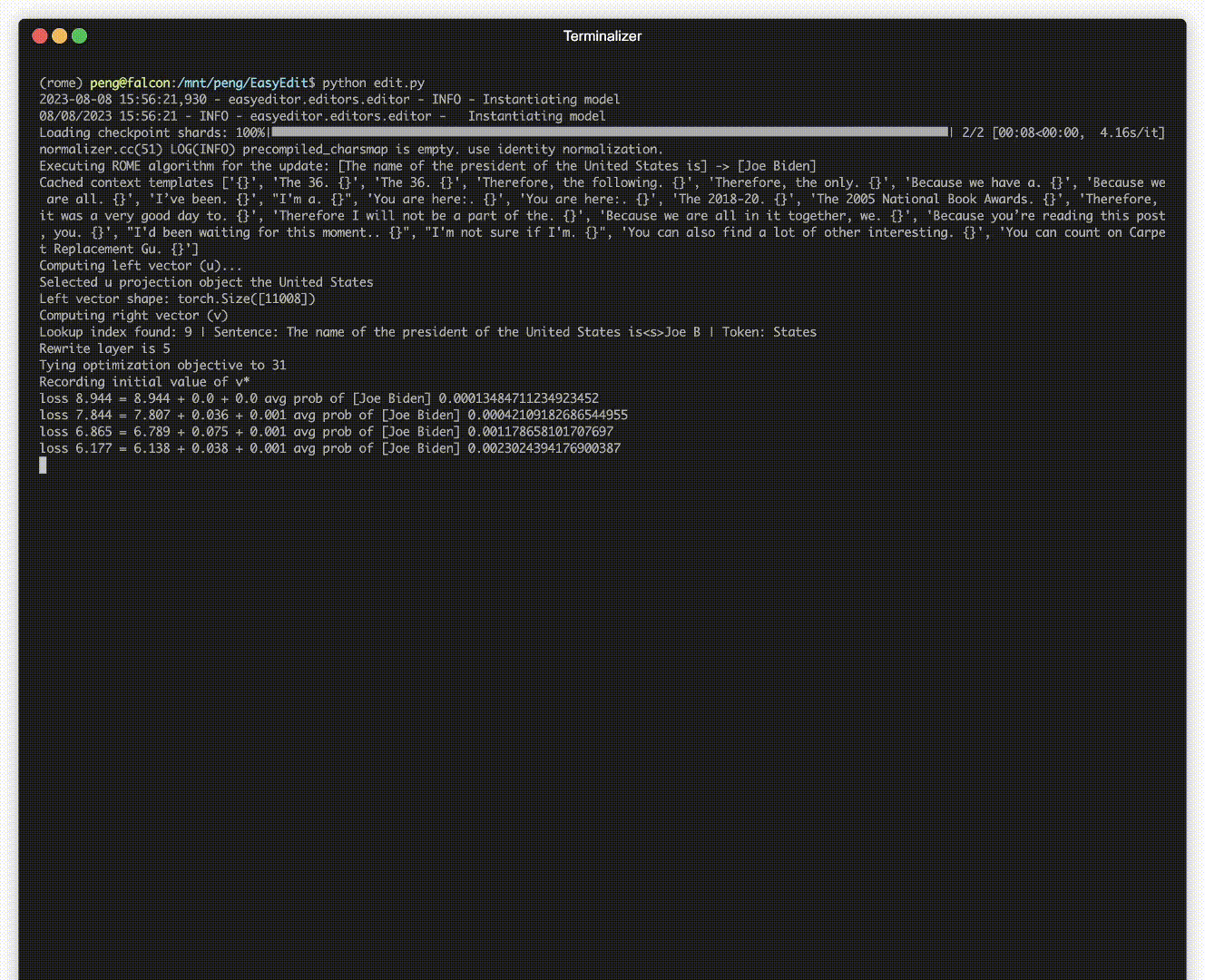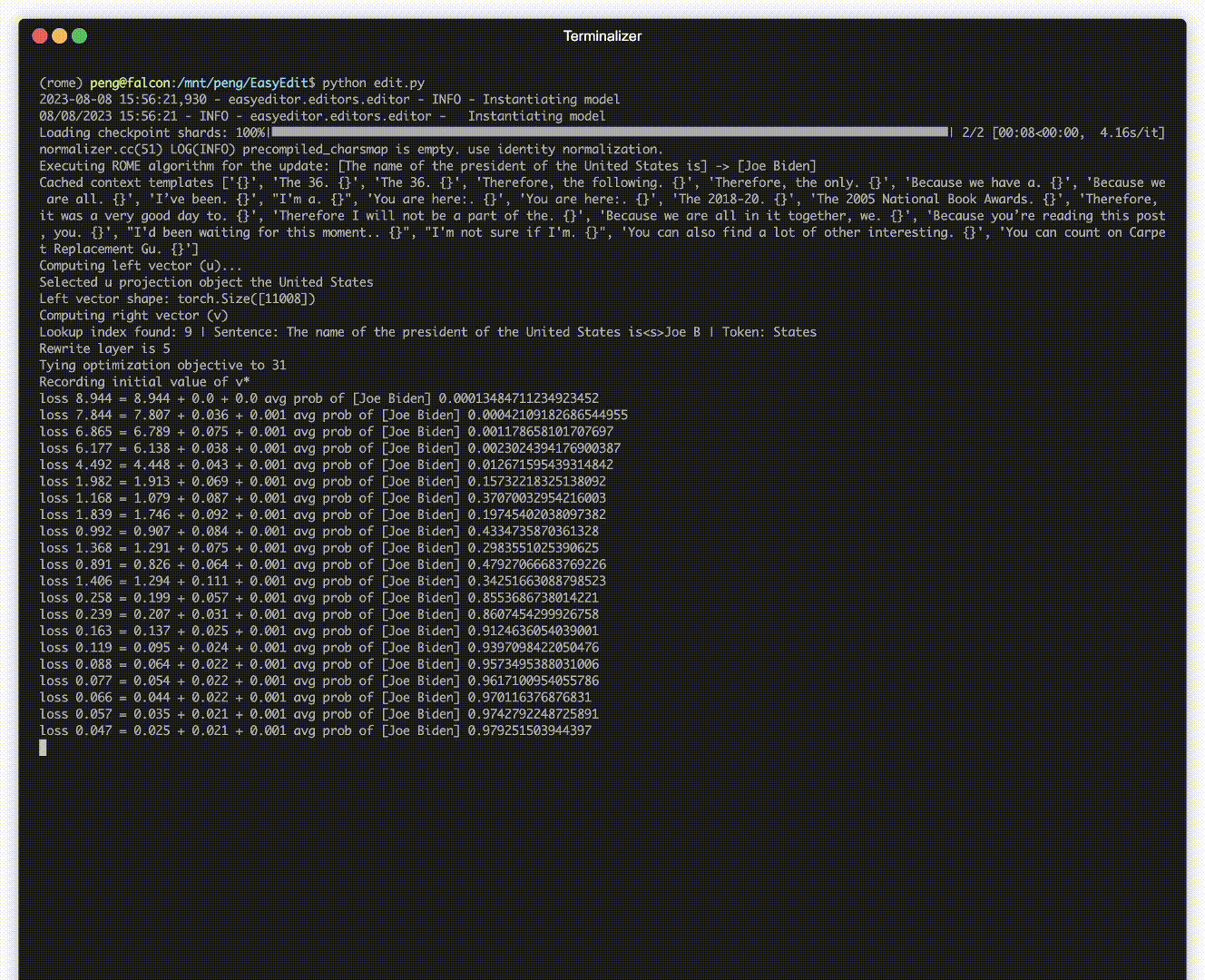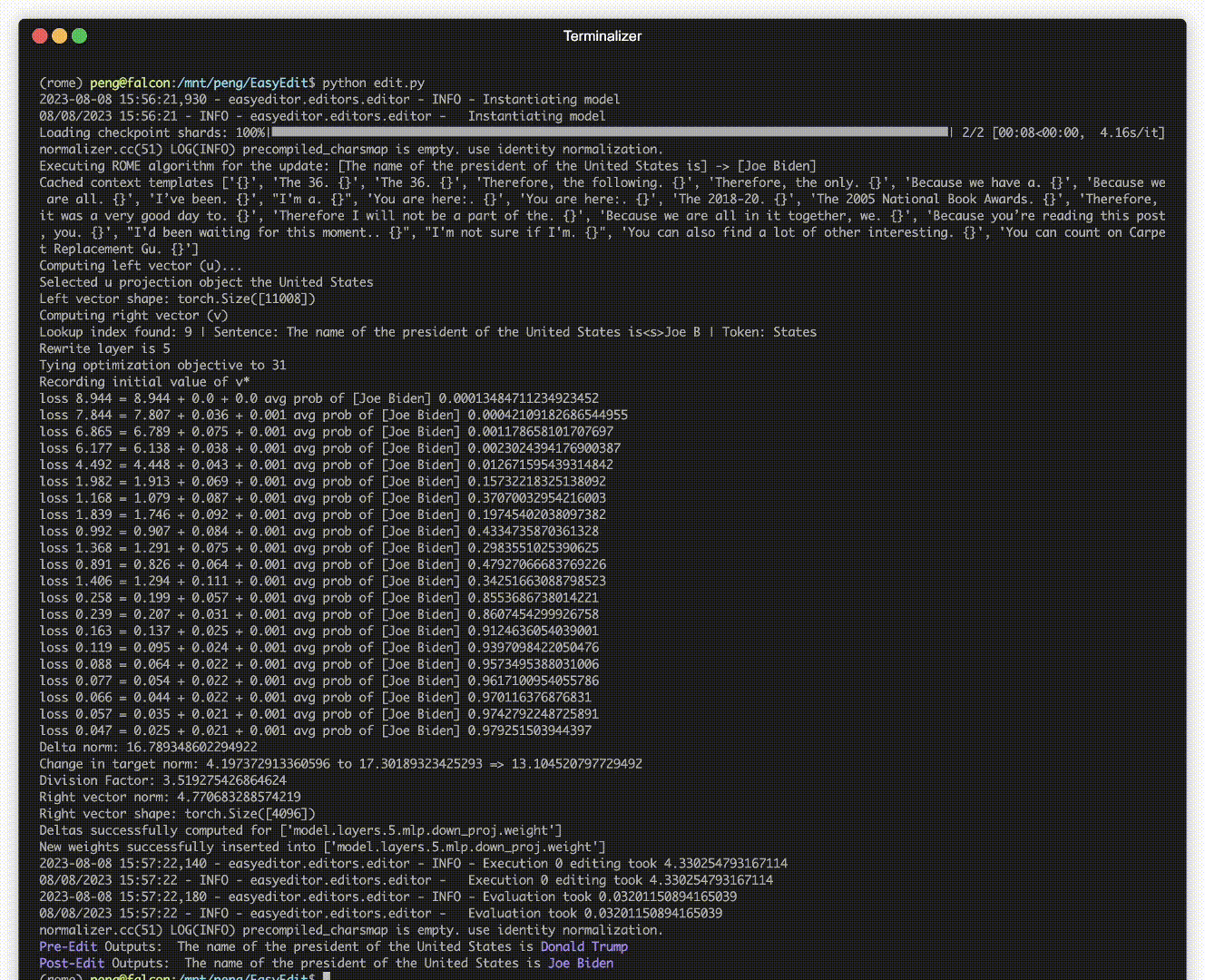
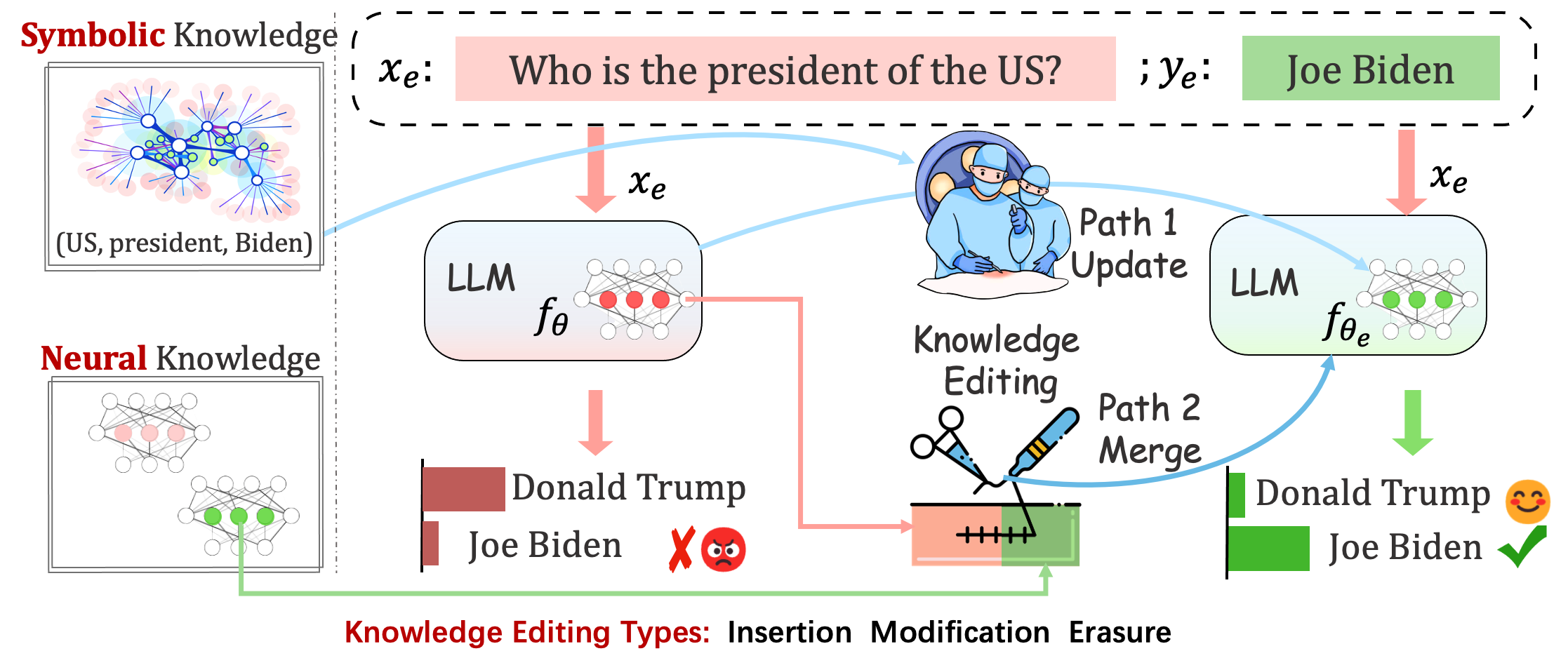
デプロイされたモデルでも、予期しないエラーが発生する可能性があります。たとえば、LLM は幻覚を起こし、バイアスを永続させ、事実上減衰することで悪名高いため、事前トレーニングされたモデルの特定の動作を調整できる必要があります。
ナレッジ編集は、ベースモデルの調整を目的としています。
1 回の編集後のモデルのパフォーマンスを評価します。モデルは 1 回の編集後に元の重みを再ロードします (たとえば、LoRA はアダプターの重みを破棄します)。 sequential_edit=Falseを設定する必要があります。
これには、順次編集する必要があり、すべてのナレッジ更新が適用された後に評価が実行されます。
パラメータ調整を行いますsequential_edit=True : README (詳細については) を設定できます。
無関係なサンプルのモデルの動作に影響を与えることなく、最終的な目標は編集されたモデルを作成することです。
画像キャプションと視覚的な質問回答の編集タスク。お読みください
提案されたタスクでは、個人の意見が性格特性の側面を反映している可能性があることを考慮して、特定のトピックに関する LLM の意見を編集することで、LLM の性格を編集するという予備的な試みが行われます。私たちは、データセットを構築し、LLM の性格表現を評価するための基礎として、確立された BIG FIVE 理論を利用します。お読みください
評価
ロジットベース
世代ベース
AccとTPEI を評価するために、ここからトレーニング済みの分類子をダウンロードできます。
ナレッジ編集プロセスは一般に、編集スコープと呼ばれる、編集例と密接に関連する広範な入力セットの予測に影響を与えます。
編集が成功すると、無関係な入力を残したまま、編集スコープ内でモデルの動作が調整されるはずです。
Reliability : 特定の編集記述子を使用した編集の成功率Generalization : 編集範囲内の編集の成功率Locality : 無関係な入力を編集した後にモデルの出力が変化するかどうかPortability : 推論/応用(ワンホップ、シノニム、論理汎化)のための編集の成功率Efficiency : 時間とメモリの消費量EasyEdit は、 GPT-J 、 Llama 、 GPT-NEO 、 GPT2 、 T5 ( 1Bから65Bまでのモデルをサポート) などの大規模言語モデル (LLM) を編集するための Python パッケージです。その目的は、言語内で LLM の動作を効率的に変更することです。他の入力全体のパフォーマンスに悪影響を与えることなく、特定のドメインにアクセスできます。使いやすく、拡張も簡単になるように設計されています。
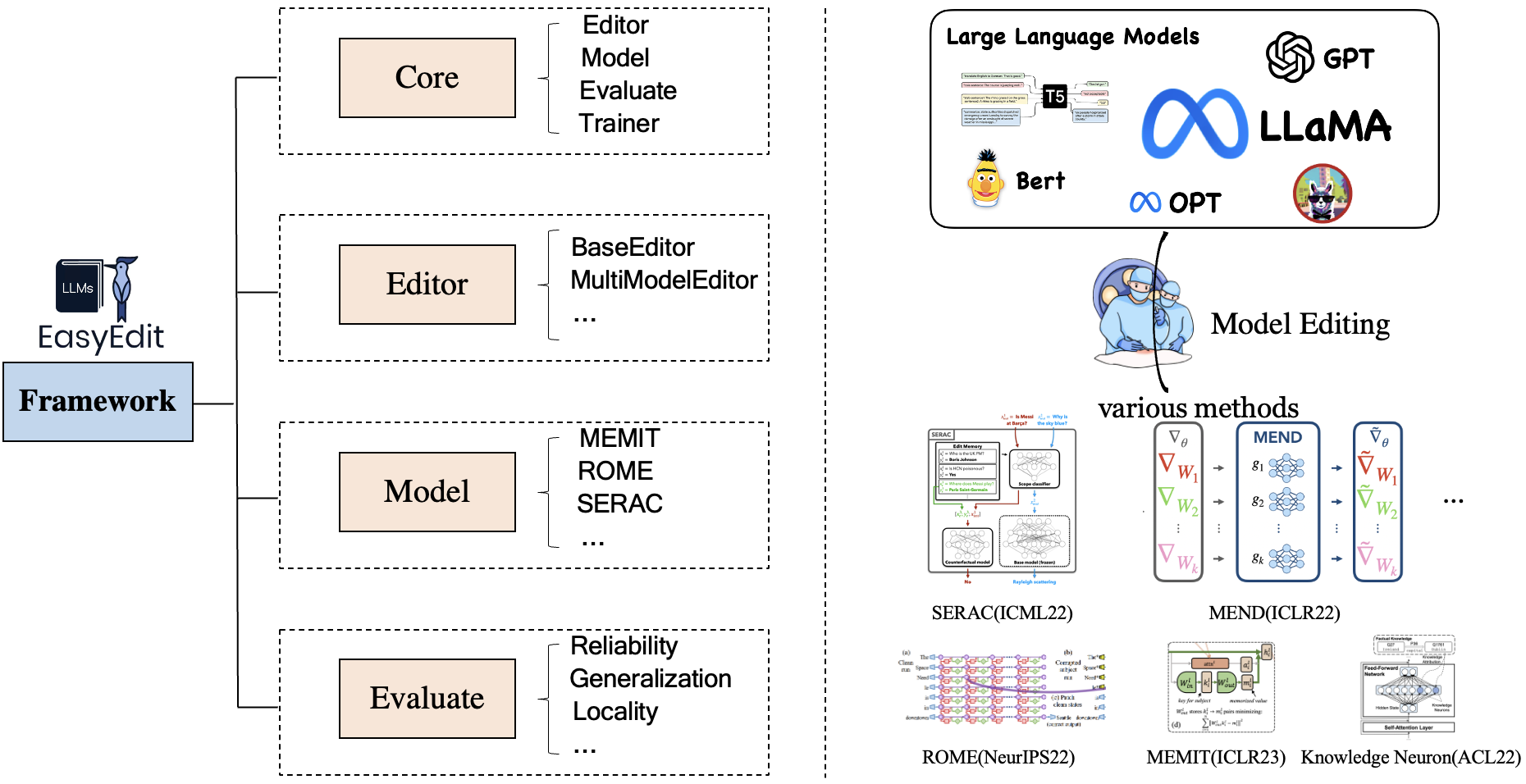
EasyEdit には、編集シナリオ、編集手法、評価方法をそれぞれ表すEditor 、 Method 、およびEvaluateの統合フレームワークが含まれています。
各ナレッジ編集シナリオは、次の 3 つのコンポーネントで構成されます。
Editor : LM用のBaseEditor(事実知識と生成エディタ)、MultiModalEditor(マルチモーダル知識)など。Method : 使用される特定の知識編集手法 ( ROME 、 MENDなど)。Evaluate : ナレッジ編集のパフォーマンスを評価するための指標。Reliability 、 Generalization 、 Locality 、 Portability現在サポートされているナレッジ編集手法は次のとおりです。
注 1: このツールキットの互換性は限られているため、T-Patcher、KE、CaliNet などの一部のナレッジ編集方法はサポートされていません。
注 2: 同様に、MALMEN メソッドも同様の理由により部分的にのみサポートされており、引き続き改良される予定です。
特定のニーズに応じて、さまざまな編集方法を選択できます。
| 方法 | T5 | GPT-2 | GPT-J | GPT-NEO | ラマ | 白川 | チャットGLM | インターンLM | クウェン | ミストラル |
|---|---|---|---|---|---|---|---|---|---|---|
| FT | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| アダロラ | ✅ | ✅ | ||||||||
| セラック | ✅ | ✅ | ✅ | ✅ | ||||||
| イケ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 直す | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| KN | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| ローマ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| r-ROME | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| メミット | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| エメット | ✅ | ✅ | ✅ | |||||||
| グレース | ✅ | ✅ | ✅ | |||||||
| メロ | ✅ | |||||||||
| PMET | ✅ | ✅ | ||||||||
| 指示編集 | ✅ | ✅ | ||||||||
| ディンム | ✅ | ✅ | ✅ | |||||||
| 賢い | ✅ | ✅ | ✅ | ✅ | ✅ | |||||
| アルファ編集 | ✅ | ✅ | ✅ |
❗️❗️ Mistral を使用する場合は、
transformersライブラリを手動でバージョン 4.34.0 に更新してください。次のコードを使用できます:pip install transformers==4.34.0。
| 仕事 | 説明 | パス |
|---|---|---|
| 指示編集 | InstructEdit: 大規模言語モデル向けの命令ベースの知識編集 | クイックスタート |
| ディンム | 知識編集による大規模言語モデルの無毒化 | クイックスタート |
| 賢い | WISE: 大規模な言語モデルの生涯にわたるモデル編集のための知識記憶を再考する | クイックスタート |
| コンセプト編集 | 大規模言語モデルの概念的知識の編集 | クイックスタート |
| MM編集 | マルチモーダルな大規模言語モデルを編集できますか? | クイックスタート |
| 性格編集 | 大規模な言語モデルのパーソナリティの編集 | クイックスタート |
| プロンプト | PROMPTベースのナレッジ編集手法 | クイックスタート |
ベンチマーク: KnowEdit [顔を抱きしめる][WiseModel][ModelScope]
❗️❗️ なお、 KnowEdit は、知識編集の包括的な評価を行うために、 WikiBio 、 ZsRE 、 WikiData Counterfact 、 WikiData Recent 、 convsent 、 Sanitationを含む既存のデータセットを再編成および拡張することによって構築されています。これらのデータセットの構築者と管理者に特に感謝します。
Counterfact と WikiData Counterfact は同じデータセットではないことに注意してください。
| タスク | 知識の挿入 | 知識の修正 | 知識の消去 | |||
|---|---|---|---|---|---|---|
| データセット | 最近のウィキ | ZsRE | ウィキバイオ | ウィキデータの反論 | 同意した | 衛生 |
| タイプ | 事実 | 質問への回答 | 幻覚 | 反証 | 感情 | 不要な情報 |
| # 電車 | 570 | 10,000 | 592 | 1,455 | 14,390 | 80 |
| # テスト | 1,266 | 1301 | 1,392 | 885 | 800 | 80 |
ユーザーがKnowEditを簡単に使用できるように、詳細なスクリプトを提供しています。例を参照してください。
knowedit
├── WikiBio
│ ├── wikibio-test-all.json
│ └── wikibio-train-all.json
├── ZsRE
│ └── ZsRE-test-all.json
├── wiki_counterfact
│ ├── test_cf.json
│ └── train_cf.json
├── convsent
│ ├── blender_test.json
│ ├── blender_train.json
│ └── blender_val.json
├── convsent
│ ├── trivia_qa_test.json
│ └── trivia_qa_train.json
└── wiki_recent
├── recent_test.json
└── recent_train.json
| データセット | ハグ顔 | ワイズモデル | モデルスコープ | 説明 |
|---|---|---|---|---|
| CKnow編集 | [ハグフェイス] | 【ワイズモデル】 | [モデルスコープ] | 中国語の知識を編集するためのデータセット |
CKnowEdit は、中国語を特徴とするナレッジ編集用の高品質な中国語データセットであり、すべてのデータは中国語のナレッジ ベースから取得されています。現在の LLM による中国語の理解に内在する微妙なニュアンスや課題をより深く理解できるよう細心の注意を払って設計されており、LLM 内で中国語特有の知識を磨き上げるための強力なリソースを提供します。
CKnowEditのデータのフィールドの説明は次のとおりです。
"prompt" : query inputed to the model ( str )
"target_old" : the incorrect response previously generated by the model ( str )
"target_new" : the accurate answer of the prompt ( str )
"portability_prompt" : new prompts related to the target knowledge ( list or None )
"portability_answer" : accurate answers corresponding to the portability_prompt ( list or None )
"locality_prompt" : new prompts unrelated to the target knowledge ( list or None )
"locality_answer" : accurate answers corresponding to the locality_prompt ( list or None )
"rephrase" : alternative ways to phrase the original prompt ( list ) CknowEdit
├── Chinese Literary Knowledge
│ ├── Ancient Poetry
│ ├── Proverbs
│ └── Idioms
├── Chinese Linguistic Knowledge
│ ├── Phonetic Notation
│ └── Classical Chinese
├── Chinese Geographical Knowledge
└── Ruozhiba
| データセット | Googleドライブ | 百度ネットディスク | 説明 |
|---|---|---|---|
| ZsREプラス | 【Googleドライブ】 | [百度ネットディスク] | 質問の言い換えを使用した質問応答データセット |
| カウンターファクトプラス | 【Googleドライブ】 | [百度ネットディスク] | エンティティ置換を使用してデータセットを対抗する |
ナレッジ編集の有効性を検証するために、zsre および counterfact データセットを提供します。ここからダウンロードできます。 [Google ドライブ]、[BaiduNetDisk]。
editing-data
├── counterfact
│ ├── counterfact-edit.json
│ ├── counterfact-train.json
│ └── counterfact-val.json
├── locality
│ ├── Commonsense Task
│ │ ├── piqa_valid-labels.lst
│ │ └── piqa_valid.jsonl
│ ├── Distracting Neighbor
│ │ └── counterfact_distracting_neighbor.json
│ └── Other Attribution
│ └── counterfact_other_attribution.json
├── portability
│ ├── Inverse Relation
│ │ └── zsre_inverse_relation.json
│ ├── One Hop
│ │ ├── counterfact_portability_gpt4.json
│ │ └── zsre_mend_eval_portability_gpt4.json
│ └── Subject Replace
│ ├── counterfact_subject_replace.json
│ └── zsre_subject_replace.json
└── zsre
├── zsre_mend_eval.json
├── zsre_mend_train_10000.json
└── zsre_mend_train.json
spouseなどの一対一の関係に対する評価| データセット | Googleドライブ | ハグ顔データセット | 説明 |
|---|---|---|---|
| コンセプト編集 | 【Googleドライブ】 | [ハグフェイスデータセット] | 概念的な知識を編集するためのデータセット |
data
└──concept_data.json
├──final_gpt2_inter.json
├──final_gpt2_intra.json
├──final_gptj_inter.json
├──final_gptj_intra.json
├──final_llama2chat_inter.json
├──final_llama2chat_intra.json
├──final_mistral_inter.json
└──final_mistral_intra.json
コンセプト固有の評価指標
Instance Change : インスタンスレベルの変更の複雑さを把握します。Concept Consistency : 生成されたコンセプト定義の意味上の類似性| データセット | Googleドライブ | 百度ネットディスク | 説明 |
|---|---|---|---|
| E-IC | 【Googleドライブ】 | [百度ネットディスク] | 画像キャプション編集用のデータセット |
| E-VQA | 【Googleドライブ】 | [百度ネットディスク] | Visual Question Answering を編集するためのデータセット |
editing-data
├── caption
│ ├── caption_train_edit.json
│ └── caption_eval_edit.json
├── locality
│ ├── NQ dataset
│ │ ├── train.json
│ │ └── validation.json
├── multimodal_locality
│ ├── OK-VQA dataset
│ │ ├── okvqa_loc.json
└── vqa
├── vqa_train.json
└── vqa_eval.json
| データセット | ハグ顔データセット | 説明 |
|---|---|---|
| セーフエディット | [ハグフェイスデータセット] | LLM を無毒化するためのデータセット |
data
└──SafeEdit_train.json
└──SafeEdit_val.json
└──SafeEdit_test.json
特定の評価指標を解毒する
Defense Duccess (DS) : LLM を変更するために使用される、敵対的な入力 (攻撃プロンプト + 有害な質問) に対する編集済み LLM の解毒成功率。Defense Generalization (DG) : ドメイン外の悪意のある入力に対する編集された LLM の無毒化成功率。General Performance : 無関係なタスクのパフォーマンスに対する副作用。 | 方法 | 説明 | GPT-2 | ラマ |
|---|---|---|---|
| イケ | インコンテキスト学習 (ICL) 編集 | [Colab-gpt2] | 【コラボラマ】 |
| ローマ | ニューロンを見つけて編集する | [Colab-gpt2] | 【コラボラマ】 |
| メミット | ニューロンを見つけて編集する | [Colab-gpt2] | 【コラボラマ】 |
注: EasyEdit には Python 3.9 以降を使用してください。開始するには、単に conda をインストールして実行します。
git clone https://github.com/zjunlp/EasyEdit.git
conda create -n EasyEdit python=3.9.7
...
pip install -r requirements.txt結果はすべてデフォルト設定に基づいています
| ラマ-2-7B | チャットグラム2 | gpt-j-6b | gpt-xl | |
|---|---|---|---|---|
| FT | 60GB | 58GB | 55GB | 7GB |
| セラック | 42GB | 32GB | 31GB | 10GB |
| イケ | 52GB | 38GB | 38GB | 10GB |
| 直す | 46GB | 37GB | 37GB | 13GB |
| KN | 42GB | 39GB | 40GB | 12GB |
| ローマ | 31GB | 29GB | 27GB | 10GB |
| メミット | 33GB | 31GB | 31GB | 11GB |
| アダロラ | 29GB | 24GB | 25GB | 8GB |
| グレース | 27GB | 23GB | 6GB | |
| 賢い | 34GB | 27GB | 7GB |
大規模言語モデル (LLM) を約5 秒で編集します
次の例は、EasyEdit を使用して編集を実行する方法を示しています。その他の例とチュートリアルは例で見つけることができます。
BaseEditor、言語モダリティ知識編集のためのクラスです。特定のニーズに基づいて、適切な編集方法を選択できます。
EasyEditのモジュール性と柔軟性により、これを使用してモデルを簡単に編集できます。
ステップ 1: PLM を編集対象として定義します。編集する PLM を選択します。 EasyEdit HuggingFace で取得できる部分モデル (これまでのT5 、 GPTJ 、 GPT-NEO 、 LlaMA ) をサポートしています。対応する構成ファイル ディレクトリはhparams/YUOR_METHOD/YOUR_MODEL.YAML ( hparams/MEND/gpt2-xl.yamlなど) で、対応するmodel_nameを設定してナレッジ編集用のオブジェクトを選択します。
model_name : gpt2-xl
model_class : GPT2LMHeadModel
tokenizer_class : GPT2Tokenizer
tokenizer_name : gpt2-xl
model_parallel : false # true for multi-GPU editingステップ 2: 適切なナレッジ編集方法を選択する
## In this case, we use MEND method, so you should import `MENDHyperParams`
from easyeditor import MENDHyperParams
## Loading config from hparams/MEMIT/gpt2-xl.yaml
hparams = MENDHyperParams . from_hparams ( './hparams/MEND/gpt2-xl' )ステップ 3: 編集記述子と編集ターゲットを指定する
## edit descriptor: prompt that you want to edit
prompts = [
'What university did Watts Humphrey attend?' ,
'Which family does Ramalinaceae belong to' ,
'What role does Denny Herzig play in football?'
]
## You can set `ground_truth` to None !!!(or set to original output)
ground_truth = [ 'Illinois Institute of Technology' , 'Lecanorales' , 'defender' ]
## edit target: expected output
target_new = [ 'University of Michigan' , 'Lamiinae' , 'winger' ]ステップ 4: これらをBaseEditorに結合するEasyEdit 、huggingface: from_hparamsのようなEditor初期化するためのシンプルで統合された方法を提供します。
## Construct Language Model Editor
editor = BaseEditor . from_hparams ( hparams )ステップ 5: 評価用のデータを提供する移植性と局所性のデータは両方ともオプションであることに注意してください (基本的な編集成功率評価の場合のみ [なし] に設定します)。どちらのデータ形式もdictであり、各測定次元に対して、対応するプロンプトとそれに対応するグラウンド トゥルースを提供する必要があります。データの例を次に示します。
locality_inputs = {
'neighborhood' :{
'prompt' : [ 'Joseph Fischhof, the' , 'Larry Bird is a professional' , 'In Forssa, they understand' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
},
'distracting' : {
'prompt' : [ 'Ray Charles, the violin Hauschka plays the instrument' , 'Grant Hill is a professional soccer Magic Johnson is a professional' , 'The law in Ikaalinen declares the language Swedish In Loviisa, the language spoken is' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
}
}上記の例では、「近所」と「気が散る」に関する編集方法のパフォーマンスを評価します。
ステップ 6: 編集と評価が完了しました。編集対象モデルの編集・評価を承ります。 edit関数は、編集プロセスに関連する一連のメトリックと、変更されたモデルの重みを返します。 [ sequential_edit=True ]
metrics , edited_model , _ = editor . edit (
prompts = prompts ,
ground_truth = ground_truth ,
target_new = target_new ,
locality_inputs = locality_inputs ,
sequential_edit = False # True: start continuous editing ✈️
)
## metrics: edit success, rephrase success, locality e.g.
## edited_model: post-edit modelEasyEdit の最大入力長は 512 です。この長さを超えると、「CUDA エラー: デバイス側アサートがトリガーされました」というエラーが発生します。次のファイルで最大長を変更できます:LINK
ステップ 7: ロールバック逐次編集では、いずれかの編集の結果に満足できず、以前の編集内容を失いたくない場合は、ロールバック機能を使用して以前の編集を取り消すことができます。現在、GRACE メソッドのみがサポートされています。必要なのは、edit_key を使用して編集を元に戻す 1 行のコードだけです。
editor.rolllback('edit_key')
EasyEdit では、デフォルトで target_new を edit_key として使用します。
編集前後のモデル予測評価を含む、戻りメトリクスをdict形式で指定します。編集ごとに、次のメトリクスが含まれます。
rewrite_acc rephrase_acc locality portablility 

