mengzi retrieval lm
1.0.0
Langboat Technology では、実際の業界のニーズを満たすために、事前トレーニングされたモデルを強化して軽量化することに重点を置いています。この目標を達成するには、検索ベースのアプローチ (RETRO、REALM、RAG など) が不可欠です。
このリポジトリは、検索強化言語モデルの実験的な実装です。現在、GPT-Neo での検索フィッティングのみをサポートしています。
検索サポートを追加するために、Huggingface Transformers と lm-evaluation-harness をフォークしました。インデックス作成部分は、取得とトレーニングをより適切に分離するために HTTP サーバーとして実装されています。
モデル実装の大部分は RETRO-pytorch と GPT-Neo からコピーされています。 transformers-cli使用して、GPT-Neo に基づいたRe_gptForCausalLMという名前の新しいモデルを追加し、それに検索部分を追加します。
200G 検索ライブラリを使用して、EleutherAI/gpt-neo-125M に適合したモデルをアップロードしました。
次のようにモデルを初期化できます。
from transformers import Re_gptForCausalLM
model = Re_gptForCausalLM . from_pretrained ( 'Langboat/ReGPT-125M-200G' )そしてモデルを次のように評価します。
python main.py
--model retrieval
--model_args pretrained=model_path
--device 0
--tasks wikitext,lambada,winogrande,mathqa,pubmedqa
--batch_size 1text_transformers の埋め込みをテキスト表現として使用して類似度を計算します。 Sentence-BERT モデルは次のように初期化できます。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer ( 'all-MiniLM-L12-v2' )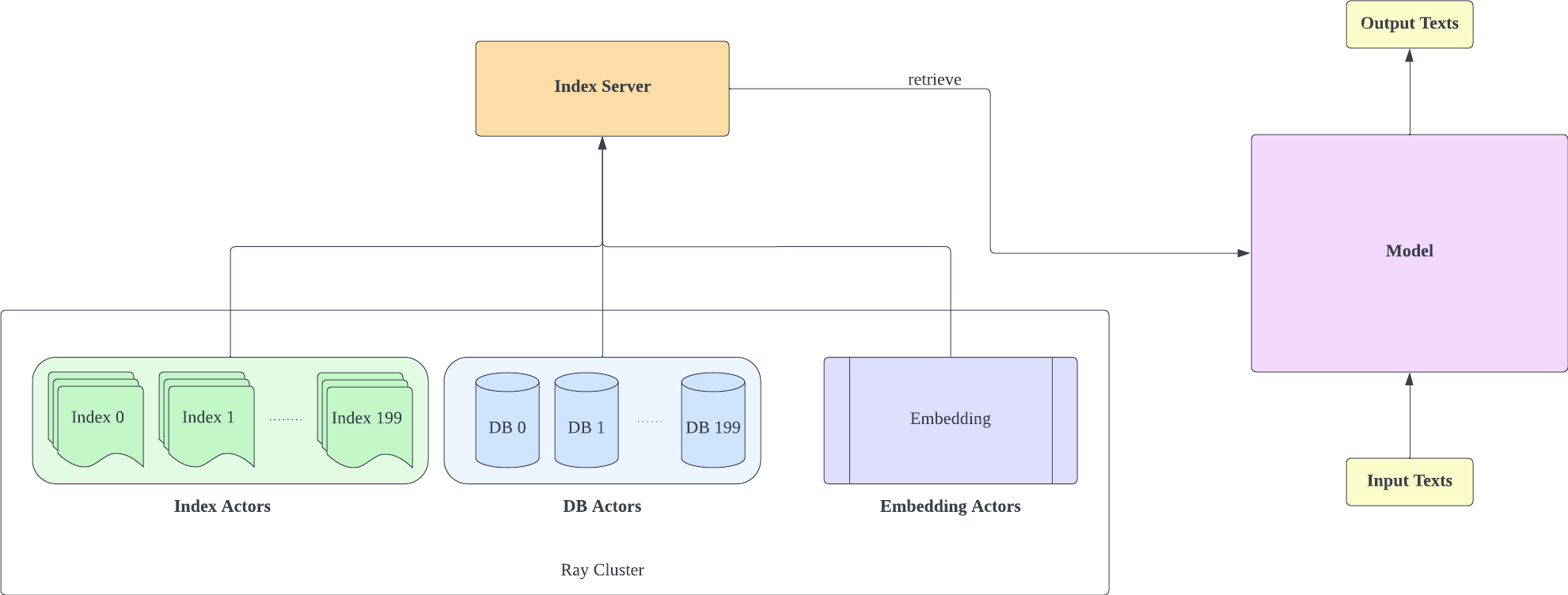
conda create -n mengzi-retrieval-fit python=3.7
conda activate mengzi-retrieval-fit
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidia
git clone https://github.com/Langboat/mengzi-retrieval-lm.git
cd mengzi-retrieval-lm
git submodule update --init --recursive
pip install -r requirement.txt
cd transformers/
pip install -e .
cd ..
python -c " from sentence_transformers import SentenceTransformer; model = SentenceTransformer('all-MiniLM-L12-v2') " IVF1024PQ48 を faiss インデックス ファクトリとして使用し、インデックスとデータベースを ハグフェイス モデル ハブにアップロードしました。これは、次のコマンドを使用してダウンロードできます。
download_index_db.py では、ダウンロードするインデックスとデータベースの数を指定できます。
python -u download_index_db.py --num 200ここから適合モデルを手動でダウンロードできます: https://huggingface.co/Langboat/ReGPT-125M-200G
インデックス サーバーは FastAPI と Ray に基づいています。 Ray の Actor を使用すると、計算負荷の高いタスクが非同期にカプセル化され、1 つの FastAPI サーバー インスタンスだけで CPU と GPU リソースを効率的に利用できるようになります。次のようにインデックス サーバーを初期化できます。
cd index-server/
ray start --head
python -u api.py
--config config_IVF1024PQ48.json
--db_path ../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966
- 構成 IVF1024PQ48.json シャード数は、ダウンロードされたインデックスの数と一致する必要があることに注意してください。現在ダウンロードされているインデックス番号は db_path で確認できます。
- この構成は A100-40G でテストされているため、別の GPU をお使いの場合は、ハードウェアに合わせて調整することをお勧めします。
- インデックス サーバーをデプロイした後、 lm-evaluation-harness/config.json および train/config.json の request_server を変更する必要があります。
- config_IVF1024PQ48.json の encoder_actor_count を減らして、必要なメモリ リソースを減らすことができます。
· db_path:huggingface からのデータベースのダウンロード場所。 「../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966」は例です。
このコマンドは、huggingface からデータベースとインデックス データをダウンロードします。
構成ファイル (config IVF1024PQ48) 内のインデックス フォルダーをインデックス フォルダーのパスを指すように変更し、データベース フォルダーのスナップショットを db パスとして api.py スクリプトに送信します。
次のコマンドでインデックス サーバーを停止します。
ray stop
- トレーニング、評価、推論中はインデックス サーバーを有効にしておく必要があることに注意してください。
train/train.py を使用してトレーニングを実装します。 train/config.json を変更してトレーニング パラメーターを変更できます。
次のようにトレーニングを初期化できます。
cd train
python -u train.py
- インデックス サーバーはメモリ リソースを使用する必要があるため、インデックス サーバーとモデルのトレーニングを別の GPU にデプロイすることをお勧めします。
train/inference.py を推論として利用して、テキストの損失とその複雑さを判断します。
cd train
python -u inference.py
--model_path Langboat/ReGPT-125M-200G
--file_name data/test_data.json
- データ フォルダー内の test_data.json と train_data.json は現在サポートされているファイル形式であり、データをこの形式に変更できます。
評価方法として lm-evaluation-harness を使用する
モデルトレーニングの seq_len が 1025 であるため、モデル比較の初期設定として lm-evaluation-harness の seq_len を 1025 に設定します。
cd lm-evaluation-harness
python setup.py installpython main.py
--model retrieval
--model_args pretrained=Langboat/ReGPT-125M-200G
--device 0
--tasks wikitext
--batch_size 1· model_path:フィッティングモデルのパス
python main.py
--model gpt2
--model_args pretrained=EleutherAI/gpt-neo-125M
--device 0
--tasks wikitext
--batch_size 1評価結果は以下の通りです
| モデル | ウィキテキスト word_perplexity |
|---|---|
| エレウザーAI/gpt-neo-125M | 35.8774 |
| ラングボート/ReGPT-125M-200G | 22.115 |
| EleutherAI/gpt-neo-1.3B | 17.6979 |
| ラングボート/ReGPT-125M-400G | 14.1327 |
@software { mengzi-retrieval-lm-library ,
title = { {Mengzi-Retrieval-LM} } ,
author = { Wang, Yulong and Bo, Lin } ,
url = { https://github.com/Langboat/mengzi-retrieval-lm } ,
month = { 9 } ,
year = { 2022 } ,
version = { 0.0.1 } ,
}

