graph gpt
v0.4.0
このリポジトリは、PyTorch での「GraphGPT: 生成事前トレーニング済みトランスフォーマーによるグラフ学習」の公式実装です。
GraphGPT: 生成事前トレーニング済みトランスフォーマーを使用したグラフ学習
Qifang Zhao、Weidong Ren、Tianyu Li、Xiaoxiao Xu、Hong Liu
2024 年 10 月 13 日
CHANGELOG.md確認してください。2024 年 8 月 18 日
CHANGELOG.md確認してください。2024/07/09
2024 年 3 月 19 日
permute_nodes実装します。StackedGSTTokenizerを追加すると、セマンティクス (つまり、ノード/エッジ属性) トークンを構造トークンと一緒にスタックできるようになり、シーケンスの長さが大幅に短縮されます。2024 年 1 月 23 日
2024 年 1 月 3 日

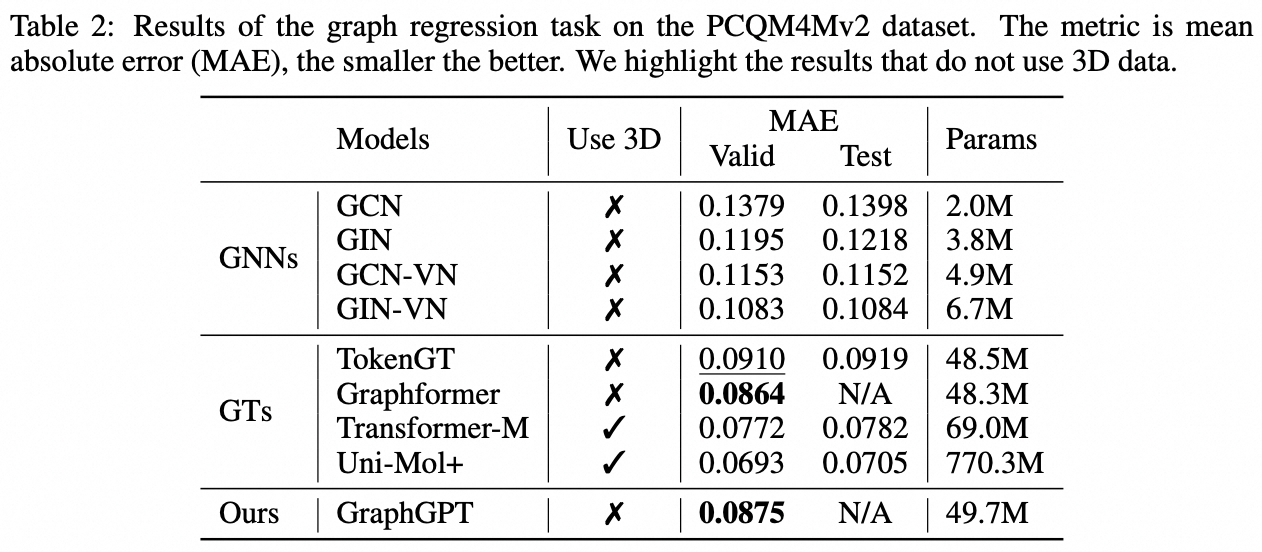
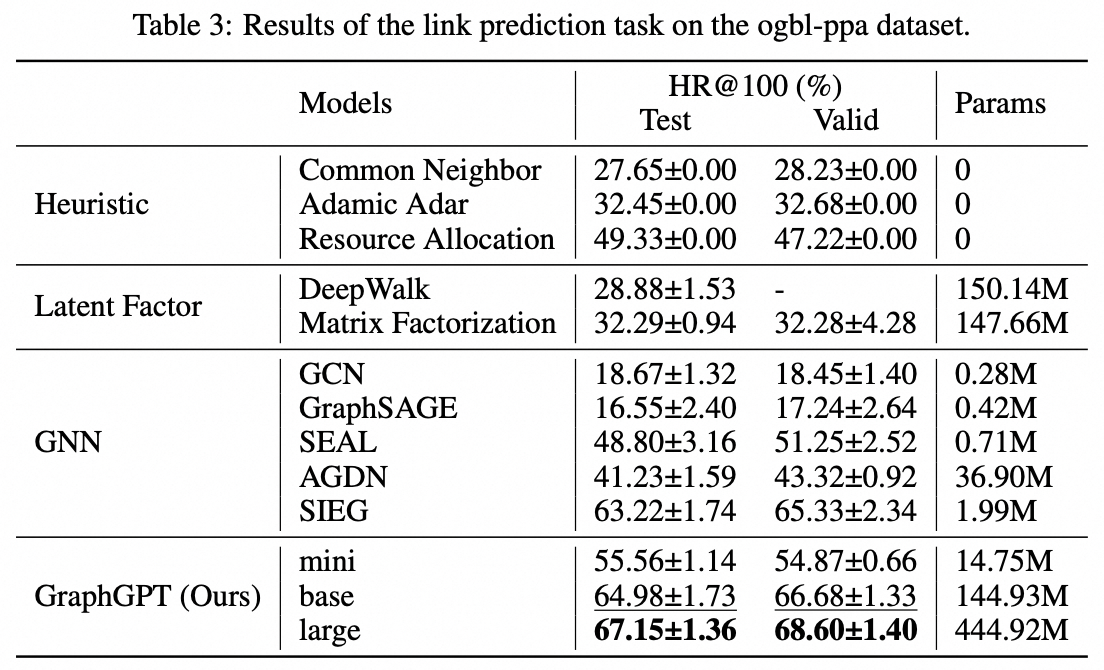
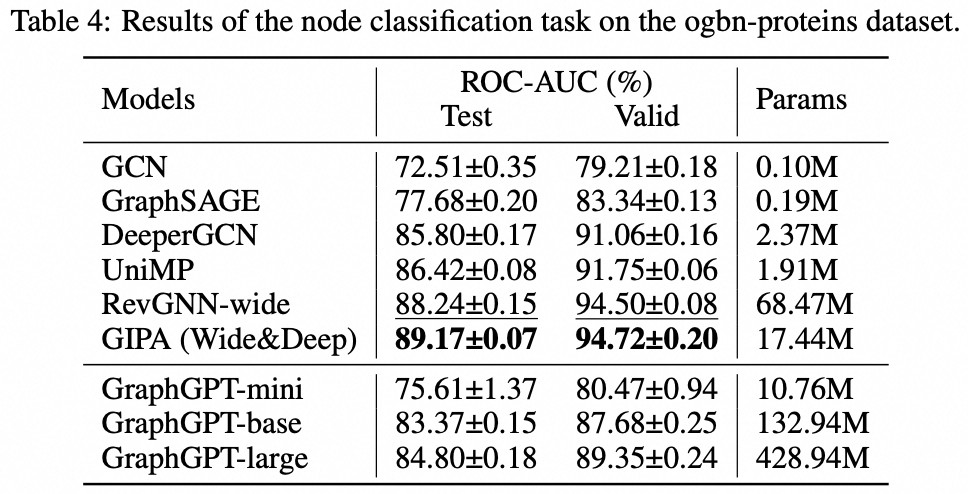
我々は、自己教師あり生成事前学習グラフオイラー変換器 (GET) によるグラフ学習のための新しいモデルである GraphGPT を提案します。まず、GET を紹介します。これは、バニラのトランスフォーマー エンコーダー/デコーダー バックボーンと、各グラフまたはサンプリングされたサブグラフを、オイラー パスを使用して可逆的にノード、エッジ、および属性を表すトークンのシーケンスに変換する変換で構成されます。次に、ネクスト トークン予測 (NTP) タスクまたはスケジュールされたマスク トークン予測 (SMTP) タスクのいずれかを使用して GET を事前トレーニングします。最後に、教師ありタスクを使用してモデルを微調整します。この直感的でありながら効果的なモデルは、大規模な分子データセット PCQM4Mv2、タンパク質間相関データセット ogbl-ppa 上のグラフ、エッジ、およびノード レベルのタスクで最先端の方法よりも優れた、またはそれに近い結果を達成します。 、引用ネットワーク データセット ogbl-quote2 および Open Graph Benchmark (OGB) の ogbn-proteins データセット。さらに、生成事前トレーニングにより、一貫して向上するパフォーマンスで最大 2B+ パラメーターまで GraphGPT をトレーニングできます。これは、GNN や以前のグラフ トランスフォーマーの能力を超えています。
オイラー化グラフをシーケンスに変換した後、シーケンスにノード属性とエッジ属性を付加する方法がいくつかあります。これらのメソッドをshort 、 longおよびprolongedと名付けます。
与えられたグラフをまずオイラー化して、それから等価な数列に変換します。そして、ノードのインデックスを周期的に再作成します。
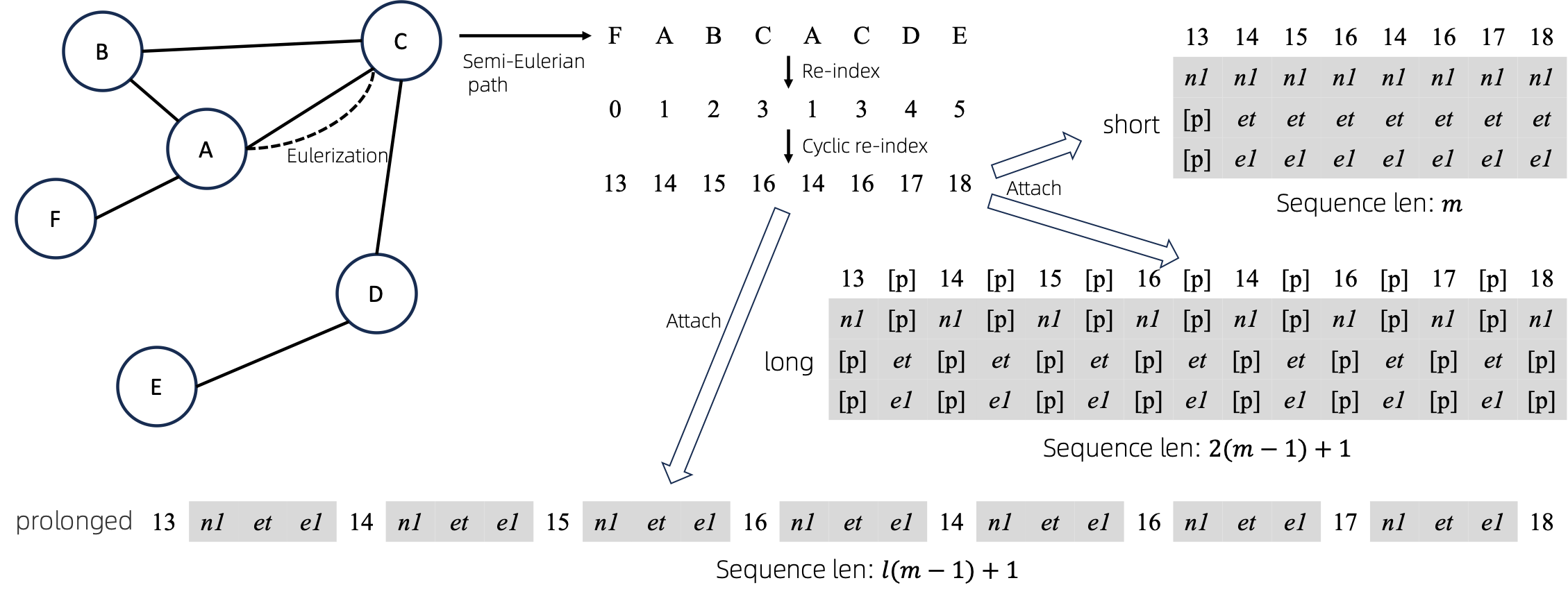
グラフに 1 つのノード属性と 1 つのエッジ属性があると仮定すると、 short 、 longおよびprolongメソッドが上に示されています。
上の図では、 n1 、 n2 、 e1ノードとエッジの属性のトークンを表し、 [p]パディング トークンを表します。
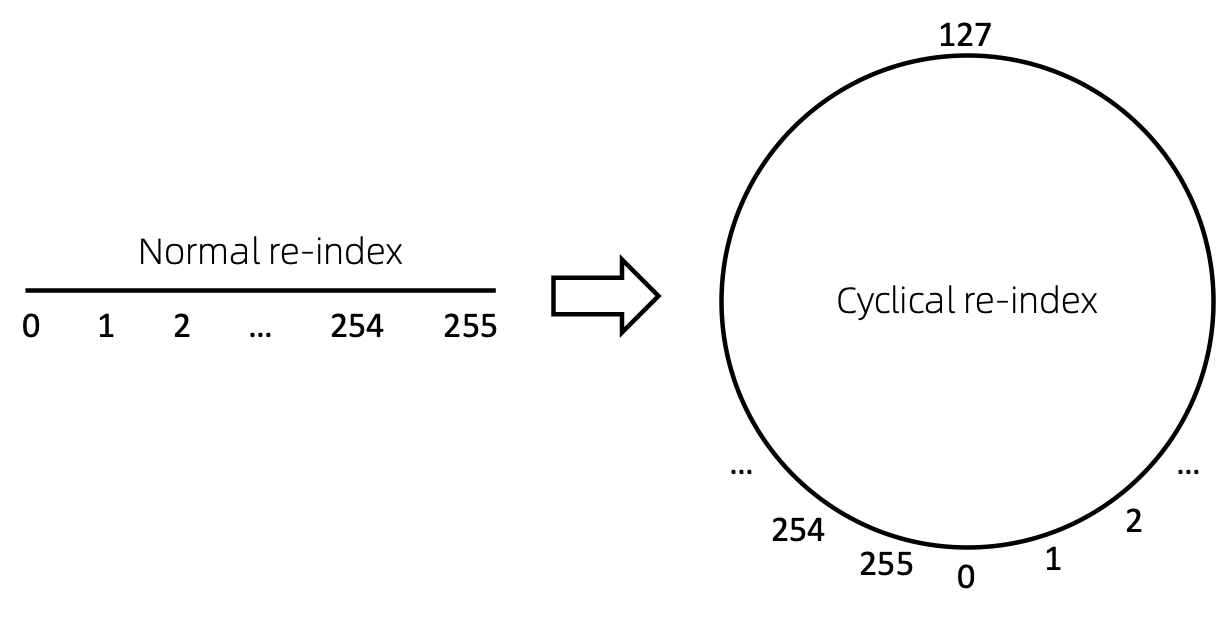
ノードのシーケンスのインデックスを再作成する簡単な方法は、0 から開始して段階的に 1 を追加することです。この方法により、小さなインデックスのトークンは十分にトレーニングされますが、大きなインデックスは十分にトレーニングされません。これを克服するために、 cyclical re-indexを提案します。これは、与えられた範囲の乱数、たとえば[0, 255]で始まり、1 ずつ増加します。境界、たとえば255に達した後、次のノード インデックスは 0 になります。 。
時代遅れです。近日中に更新予定です。
git clone https://github.com/alibaba/graph-gpt.gitconda create -n graph_gpt python=3.8 pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
conda activate graph_gpt
cd graph-gpt
pip install -r ./requirements.txt
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-1.13.1+cpu.html
sudo apt-get install bcデータセットは、Python パッケージ ogb を使用してダウンロードされます。
./examplesでスクリプトを実行すると、データセットが自動的にダウンロードされます。
ただし、データセット PCQM4M-v2 は巨大なので、ダウンロードと前処理に問題が生じる可能性があります。 cd ./src/utils/とpython dataset_utils.py使用して、データセットを個別にダウンロードして前処理することをお勧めします。
./examples/graph_lvl/pcqm4m_v2_pretrain.shのパラメーター (例: dataset_name 、 model_name 、 batch_size 、 workerCountなど) を変更し、 ./examples/graph_lvl/pcqm4m_v2_pretrain.shを実行して、PCQM4M-v2 でモデルを事前トレーニングします。データセット。./examples/toy_examples/reddit_pretrain.shを直接実行します。./examples/graph_lvl/pcqm4m_v2_supervised.shのパラメータ (例: dataset_name 、 model_name 、 batch_size 、 workerCount 、 pretrain_cptなど) を変更してから、 ./examples/graph_lvl/pcqm4m_v2_supervised.shを実行してダウンストリーム タスクを微調整します。 。./examples/toy_examples/reddit_supervised.shを直接実行します。 .pre-commit-config.yaml : Python 用に次の内容のファイルを作成します。 repos :
- repo : https://github.com/pre-commit/pre-commit-hooks
rev : v4.4.0
hooks :
- id : check-yaml
- id : end-of-file-fixer
- id : trailing-whitespace
- repo : https://github.com/psf/black
rev : 23.7.0
hooks :
- id : blackpre-commit install : git フックに pre-commit をインストールします。pre-commit install実行することが最初に行う必要があります。pre-commit run --all-files : リポジトリ上のすべての pre-commit フックを実行します。pre-commit autoupdate : フックを最新バージョンに自動的に更新しますgit commit -n : コマンドを使用して、特定のコミットに対してコミット前チェックを無効にできますこの研究が役立つと思われる場合は、次の論文を引用してください。
@article{zhao2024graphgpt,
title={GraphGPT: Graph Learning with Generative Pre-trained Transformers},
author={Zhao, Qifang and Ren, Weidong and Li, Tianyu and Xu, Xiaoxiao and Liu, Hong},
journal={arXiv preprint arXiv:2401.00529},
year={2024}
}趙啓芳 ([email protected])
私たちの仕事に関するご提案に心から感謝いたします。
MIT ライセンスに基づいてリリースされています ( LICENSEを参照):
Ali-GraphGPT-project is an AI project on training large scale transformer decoder with graph datasets,
developed by Alibaba and licensed under the MIT License.


