CDial GPT
1.0.0
このプロジェクトは、大規模な中国語会話データセットと、このデータセット上の中国語会話事前トレーニング モデル (中国語 GPT モデル) を提供します。詳細については、論文を参照してください。
このプロジェクトのコードは TransferTransfo から変更されており、事前トレーニングと微調整に使用できる Transformers ライブラリの HuggingFace Pytorch バージョンを使用しています。
from datasets import load_dataset
dataset = load_dataset ( "lccc" , "base" ) # or "large"当社が提供するデータセット LCCC (Large-scale Cleaned Chinese Conversation) は、主にLCCC-base (Baidu Netdisk、Google Drive) とLCCC-large (Baidu Netdisk、Google Drive) の 2 つの部分で構成されています。このデータセット内の会話データの品質を保証します。 このデータ フィルタリング プロセスには、一連の手動ルールと機械学習アルゴリズムに基づくいくつかの分類子が含まれています。 私たちがフィルタリングするノイズには、汚い言葉、特殊文字、表情、文法的に間違った文、文脈に無関係な会話などが含まれます。
このデータセットの統計を下の表に示します。 このうち、2文のみからなる対話を「シングルターン対話」、2文以上からなる対話を「マルチターン対話」と呼びます。 単語リストのサイズを数えるときは、Jieba 単語分割を使用します。
| LCCCベース (百度クラウドディスク、Googleドライブ) | ワンターン会話 | 複数回の対話 |
|---|---|---|
| 会話の合計ターン数 | 3,354,232 | 3,466,274 |
| 総会話文 | 6,708,464 | 13,365,256 |
| 総文字数 | 68,559,367 | 163,690,569 |
| 語彙のサイズ | 372,063 | 666,931 |
| 会話文の平均単語数 | 6.79 | 8.32 |
| 会話ラウンドあたりの平均文数 | 2 | 3.86 |
LCCC ベースのデータセットのクリーニング プロセスは LCCC-large のクリーニング プロセスよりも厳格であるため、そのサイズも小さいことに注意してください。
| LCCC-大 (百度クラウドディスク、Googleドライブ) | ワンターン会話 | 複数回の対話 |
|---|---|---|
| 会話の合計ターン数 | 7,273,804 | 4,733,955 |
| 総会話文 | 14,547,608 | 18,341,167 |
| 総文字数 | 162,301,556 | 217,776,649 |
| 語彙のサイズ | 662,514 | 690,027 |
| 会話文の評価語数 | 7.45 | 8.14 |
| 会話ラウンドあたりの平均文数 | 2 | 3.87 |
LCCC ベースのデータ セット内の元の会話データは Weibo の会話から取得され、LCCC ラージ データ セット内の元の会話データは、次の Weibo の会話に基づいて他のオープンソースの会話データ セットと統合されます。
| データセット | 会話の合計ターン数 | 会話例 |
|---|---|---|
| Weiboコーパス | 79M | Q: 重慶の成都で火鍋を7、8回食べました。 A: はははは!そしたら口が腐るかもしれないよ! |
| PTT ゴシップ コーパス | 0.4M | Q: なぜ村人はいつも高校生をいじめるのですか? QQ A: 良い科目を選択すればビル・ゲイツになれると思うなら、学校を中退したほうがいいでしょう。 |
| 字幕コーパス | 274万 | Q: 京劇の人々は自由ではありません。 A: 彼らは人々を檻に入れます。 |
| 小黄語コーパス | 0.45M | Q: 恋をしたことはありますか? A: 恋をしたことはありますか? |
| タイバコーパス | 232万 | Q: 最前列のルーのファンはみんな立ち上がっていますよね? A: タイトルにはアシストと書いてありますが、あのボールを見たら、本当に生きた皮肉だと思いました。 |
| 清雲コーパス | 0.1M | Q: お金が大好きのようですね。 A: そうですか。そうすれば、もうすぐそこです |
| Douban 会話コーパス | 0.5M | Q: オリジナルの英語映画を見て純粋な英語を学びましょう A: フレンズが大好きで何回も見ています Q: 同じ CD を見て疲れそうになっています A: そうするとあなたの英語はもうかなり上手になるはずです |
| 電子商取引会話コーパス | 0.5M | Q: これはお買い得ですか? A: まだありますか? A: 未定です。 |
| 中国語チャットコーパス | 0.5M | Q: 今日は足がダメなんです。だから、クリスマスにお金を稼ぎに行ったんです。彼氏がいないので、休日はどこでも同じです。 |
また、一連の中国語事前トレーニング モデル (中国語 GPT モデル) も提供しています。これらのモデルの事前トレーニング プロセスは 2 つのステップに分かれており、最初は中国の新規データでの事前トレーニング、次に LCCC データでの事前トレーニングです。セット。
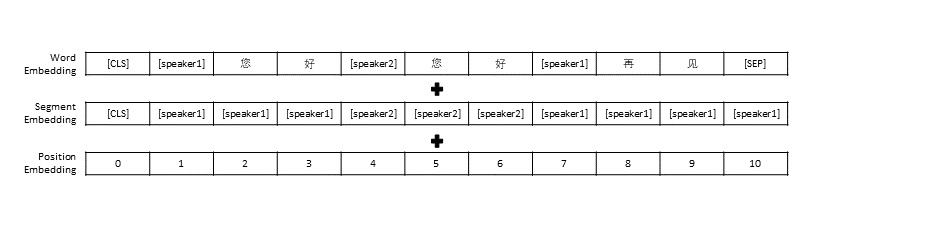
TransferTransfo のデータ前処理設定に従い、すべての会話履歴を 1 つの文につなぎ、この文を会話の応答を予測するモデルの入力として使用しました。各単語のベクトル表現に加えて、モデルの入力には話者ベクトル表現と位置ベクトル表現も含まれています。
| 事前トレーニング済みモデル | パラメータの数 | 事前トレーニングに使用されるデータ | 説明する |
|---|---|---|---|
| GPT小説 | 95.5M | 中国小説データ | 中国語の小説データに基づいて構築された中国語の事前トレーニング済み GPT モデル (小説データには合計 13 億語が含まれています) |
| CDial-GPT LCCC-ベース | 95.5M | LCCCベース | GPT Novelに基づいて、LCCC ベースでトレーニングされた中国語の事前トレーニング済み GPT モデルを使用します |
| CDial-GPT2 LCCCベース | 95.5M | LCCCベース | GPT Novelに基づいて、LCCC ベースでトレーニングされた中国語の事前トレーニング済み GPT2 モデルを使用します |
| CDial-GPT LCCC-ラージ | 95.5M | LCCC-大 | GPT Novelに基づいて、LCCC-large によってトレーニングされた中国語の事前トレーニング済み GPT モデルを使用します |
ソースから直接インストールします。
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
ステップ 1: モデルの事前トレーニングと微調整に必要なデータセット (STC データセットやおもちゃデータ「data/toy_data.json」など) をプロジェクト ディレクトリに準備します。データに英語が含まれている場合は分離する必要があることに注意してください手紙で、たとえば: こんにちは)
# 下载 STC 数据集 中的训练集和验证集 并将其解压至 "data_path" 目录 (如果微调所使用的数据集为 STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # 您可自行下载模型或者OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps: 次のリンクを使用して、STC (Baidu Cloud Disk、Google Drive) のトレーニング セットと検証セットをダウンロードできます。
ステップ 2: モデルをトレーニングする
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 使用单个GPU进行训练
または
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 以分布式的方式在8块GPU上训练
train_pathパラメーターもトレーニング スクリプトで提供されており、ユーザーはプレーン テキスト ファイルをスライスで読み取ることができます。メモリが限られたシステムを使用している場合は、このパラメータを使用してトレーニング データを読み取ることを検討してください。 train_path使用する場合は、 data_path空のままにする必要があります。
ステップ 3: テキストを生成する
# YOUR_MODEL_PATH: 你要使用的模型的路径,每次微调后的模型目录保存在./runs/中
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # 在测试数据上生成回复
python interact.py --model_checkpoint YOUR_MODEL_PATH # 在命令行中与模型进行交互
ps: 次のリンクを使用して、STC テスト セット (Baidu Cloud Disk、Google Drive) をダウンロードできます。
トレーニング スクリプトのパラメータ
| パラメータ | タイプ | デフォルト値 | 説明する |
|---|---|---|---|
| モデルチェックポイント | str | 「」 | モデル ファイルのパスまたは URL (事前トレーニング モデルと config/vocab ファイルのディレクトリ) |
| 事前訓練された | ブール | 間違い | False の場合、モデルを最初からトレーニングします |
| データパス | str | 「」 | データセットのパス |
| データセットキャッシュ | str | デフォルト = "データセットキャッシュ" | データセット キャッシュのパスまたは URL |
| 電車のパス | str | 「」 | 分散データセットのトレーニング セットのパス |
| 有効なパス | str | 「」 | 分散データセットの検証セットのパス |
| ログファイル | str | 「」 | このパスの下のファイルにログを出力します |
| num_workers | 整数 | 1 | データロード用のサブプロセスの数 |
| n_epochs | 整数 | 70 | トレーニング エポックの数 |
| train_batch_size | 整数 | 8 | トレーニングのバッチサイズ |
| valid_batch_size | 整数 | 8 | 検証用のバッチサイズ |
| max_history | 整数 | 15 | 履歴に保存する以前の交換の数 |
| スケジューラ | str | 「ノーム」 | オプティマイザの手法 |
| n_emd | 整数 | 768 | 設定ファイル内の n_emd の数 (noam の場合) |
| eval_before_start | ブール | 間違い | true の場合、トレーニング前に評価を開始します |
| ウォームアップ_ステップ | 整数 | 5000 | ウォームアップ手順 |
| 有効なステップ数 | 整数 | 0 | 0 でない場合は、X ステップごとに検証を実行します |
| gradient_accumulation_steps | 整数 | 64 | 複数のステップで勾配を蓄積する |
| 最大ノルム | フロート | 1.0 | クリッピング勾配ノルム |
| デバイス | str | "cuda" if torch.cuda.is_available() else "cpu" | デバイス (cuda または cpu) |
| FP16 | str | 「」 | fp16 トレーニングの場合は O0、O1、O2、または O3 に設定します (apex ドキュメントを参照) |
| ローカルランク | 整数 | -1 | 分散トレーニングのローカル ランク (-1: 分散されていない) |
STC データセット (トレーニング セット/検証セット (Baidu Netdisk、Google Drive)、テスト セット (Baidu Netdisk、Google Drive)) を使用して微調整された対話事前トレーニング モデルを評価しました。 すべての応答は核サンプリングを使用してサンプリングされました (p=0.9、温度=0.7)。
| モデル | モデルサイズ | PPL | ブルー-2 | ブルー-4 | 距離-1 | 距離-2 | 貪欲なマッチング | 埋め込み平均 |
|---|---|---|---|---|---|---|---|---|
| Attn-Seq2seq | 73M | 34.20 | 3.93 | 0.90 | 8.5 | 11.91 | 65.84 | 83.38 |
| トランス | 113M | 10月22日 | 6.72 | 3.14 | 8.8 | 13.97 | 66.06 | 83.55 |
| GPT2-雑談 | 88M | - | 2.28 | 0.54 | 10.3 | 16.25 | 61.54 | 78.94 |
| GPT小説 | 95.5M | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83.34 |
| GPT LCCCベース | 95.5M | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| GPT2 LCCCベース | 95.5M | 22.76 | 5.69 | 2.50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-ラージ | 95.5M | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66.25 | 83.63 |
各モデルについて 200 の回答をサンプリングし、アウトソーシング プラットフォームに 3 人のアノテーターを招待して、これらの回答を手動で評価してもらいました。評価の要素は、会話の流暢さ、文脈の関連性、および回答の多様性でした。各次元のスコア範囲は 2/1/0 です。詳細については、論文を参照してください。
| モデル | +2 | +1 | +0 | カッパ |
|---|---|---|---|---|
| Attn-Seq2Seq | 27.1% | 21.4% | 51.4% | 0.4544 |
| トランス | 42.4% | 23.6% | 34.0% | 0.4429 |
| GPT2-雑談 | 24.3% | 19.1% | 56.6% | 0.3941 |
| GPT LCCCベース | 46.7% | 21.8% | 31.5% | 0.3954 |
| GPT LCCC-ラージ | 48.6% | 24.5% | 27.0% | 0.4203 |
会話の返信 1,000 件をランダムにサンプリングし、これらの返信の中から悪い返信を数えました。
| 繰り返しの記述が含まれています | 呪いの言葉が含まれています | その他の悪い返信 |
|---|---|---|
| 23 | 9 | 2 |
STC データセット上の GPT LCCC-largeモデルのパラメーターを微調整し、この微調整されたモデルを使用して次の会話例を生成しました。
| 役職 | 応答 |
|---|---|
| ここは実際にはハルビンではなく北京です。 | ハルビンの天気は北京よりも良いようです。雨は小雨で、日中は風が強いです。 |
| 運営者のキャンパス広告コンテストはとても楽しかったです! ハハハ。 | ジャック・マーの広告かと思った。 |
| Delsa S posa キャンディーカラー シリーズのウェディング ドレス、ピンク、ブルー、レッド、パープル、遊び心と新鮮さ、気に入りましたか? | ラストは本当に美しい、とても美しい! |
また、上記の微調整されたモデルを使用して、次の対話結果が得られました。
| ロエル | 応答 |
|---|---|
| ユーザー | 無駄に私を愛さないで |
| ボット | 実りのない恋はとても苦しいです。 |
| ユーザー | でも好きだったら大丈夫 |
| ボット | 時には、愛はゲームです。 |
| ユーザー | いつも負けてしまう |
| ボット | 私はあなたを愛しているのと同じくらいあなたを愛しています。 |
| ユーザー | 引っ張ってもらえますか? |
| ボット | 引っ張ることができます。 |
| ユーザー | 私の真似しないでください |
| ボット | 私が言いたいのは、あなたにはそれができないということです。 |
| ユーザー | 私にそれを強制するんですよね? |
| ボット | いや、強制的に喋らせているんですよね? |
ワン・イーダ、ペイ・ケ、鄭銀和、ファン・カイリー、ジャン・ヨン、朱暁燕、黄ミンリー
Zuoxian Ye、Yao Wang、Yifan Pan
このプロジェクトによって提供される LCCC データセットと事前トレーニングされた対話モデルは、科学研究のみを目的としています。 LCCC データセット内の会話はさまざまなソースから収集されていますが、当社は厳格なデータクリーニングプロセスを設計していますが、すべての不適切なコンテンツがフィルタリングされたことを保証するものではありません。このデータに含まれるすべてのコンテンツと意見は、このプロジェクトの作成者から独立しています。 このプロジェクトで提供されるモデルとコードは、完全な対話システムのコンポーネントにすぎません。私たちが提供するデコード スクリプトは、科学研究のみを目的としており、このプロジェクトのモデルとスクリプトを使用して生成されたすべての対話コンテンツは、作者とは何の関係もありません。このプロジェクト。
私たちのプロジェクトが役立つと思われる場合は、私たちの論文を引用してください。
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}
このプロジェクトは、大規模なクリーン化された中国語会話データセットと、このデータセットで事前トレーニングされた中国語 GPT モデルを提供します。詳細については、論文を参照してください。
事前トレーニングに使用されるコードは、Transformers ライブラリに基づく TransferTransfo モデルから適応されています。事前トレーニングと微調整の両方に使用されるコードは、このリポジトリで提供されます。
以下を含む大規模なクリーン化された中国語会話コーパス (LCCC) を紹介します。 LCCC-base (Baidu Netdisk、Google Drive) およびLCCC-large (Baidu Netdisk、Google Drive) の品質を確保するために、厳格なデータ クリーニング パイプラインが設計されています。このパイプラインには、一連のルールと、不快な言葉やデリケートな言葉、特殊な記号、絵文字、文法的に間違った文、支離滅裂な会話などのいくつかの分類子ベースのフィルターが含まれます。濾過された。
コーパスの統計は、2 つの発話のみを含む対話を「シングルターン」とみなし、3 つ以上の発話を含む対話を「マルチターン」とみなし、語彙サイズを単語レベルで計算します。 Jieba は、各発話を単語にトークン化するために使用されます。
| LCCCベース (百度ネットディスク、Google ドライブ) | シングルターン | マルチターン |
|---|---|---|
| セッション | 3,354,382 | 3,466,607 |
| 発話 | 6,708,554 | 13,365,268 |
| キャラクター | 68,559,727 | 163,690,614 |
| 語彙 | 372,063 | 666,931 |
| 発話ごとの平均単語数 | 6.79 | 8.32 |
| セッションあたりの平均発話数 | 2 | 3.86 |
LCCC-base は、LCCC-large と比較して、より厳格なルールを使用してクリーンアップされることに注意してください。
| LCCC-大 (百度ネットディスク、Google ドライブ) | シングルターン | マルチターン |
|---|---|---|
| セッション | 7,273,804 | 4,733,955 |
| 発話 | 14,547,608 | 18,341,167 |
| キャラクター | 162,301,556 | 217,776,649 |
| 語彙 | 662,514 | 690,027 |
| 発話ごとの平均単語数 | 7.45 | 8.14 |
| セッションあたりの平均発話数 | 2 | 3.87 |
LCCC-base の生のダイアログは、Weibo からクロールした Weibo コーパスに由来しており、LCCC-large の生のダイアログは、Weibo コーパスに加えていくつかの会話データセットを組み合わせて構築されています。
| データセット | セッション | サンプル |
|---|---|---|
| Weiboコーパス | 79M | Q: 重慶の成都で火鍋を7、8回食べました。 A: はははは!そしたら口が腐るかもしれないよ! |
| PTT ゴシップ コーパス | 0.4M | Q: なぜ村人はいつも高校生をいじめるのですか? QQ A: 良い科目を選択すればビル・ゲイツになれると思うなら、学校を中退したほうがいいでしょう。 |
| 字幕コーパス | 274万 | Q: 京劇の人々は自由ではありません。 A: 彼らは人々を檻に入れます。 |
| 小黄語コーパス | 0.45M | Q: 恋をしたことはありますか? A: 恋をしたことはありますか? |
| タイバコーパス | 232万 | Q: 最前列のルー選手のファンはみんな立ち上がっていますよね? A: タイトルにはアシストと書いてありますが、あのボールを見たら本当に生きた皮肉だと思いました。 |
| 清雲コーパス | 0.1M | Q: お金が大好きのようですね。 A: そうですか。そうすれば、もうすぐそこです |
| Douban 会話コーパス | 0.5M | Q: オリジナルの英語映画を見て純粋な英語を学びましょう A: フレンズが大好きで何回も見ています Q: 同じ CD を見て疲れそうになっています A: そうするとあなたの英語はもうかなり上手になるはずです |
| 電子商取引会話コーパス | 0.5M | Q: これはお買い得になりますか? A: まだありますか? A: 未定です。 |
| 中国語チャットコーパス | 0.5M | Q: 今日は足がダメなんです。だから、クリスマスにお金を稼ぎに行ったんです。彼氏がいないので、休日はどこでも同じです。 |
また、最初に中国の新しいデータセットで事前トレーニングされ、次に LCCC データセットで事後トレーニングされた一連の中国 GPT モデルも紹介します。
TransferTransfo と同様に、すべての対話履歴を 1 つのコンテキスト文に連結し、この文を使用して応答を予測します。モデルの入力は、単語の埋め込み、話者の埋め込み、各単語の位置の埋め込みで構成されます。
| モデル | パラメータのサイズ | 事前トレーニング データセット | 説明 |
|---|---|---|---|
| GPT小説 | 95.5M | 中国の小説 | 中国小説データセットで事前トレーニングされた GPT モデル (13 億ワード、このモデルの詳細は提供していないことに注意してください) |
| CDial-GPT LCCC-ベース | 95.5M | LCCCベース | GPT Novelの LCCC ベースのデータセットでポストトレーニングされた GPT モデル |
| CDial-GPT2 LCCCベース | 95.5M | LCCCベース | GPT Novelの LCCC ベースのデータセットでポストトレーニングされた GPT2 モデル |
| CDial-GPT LCCC-ラージ | 95.5M | LCCC-大 | GPT Novelの LCCC 大規模データセットでポストトレーニングされた GPT モデル |
ソースコードからインストールします。
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
ステップ 1: 微調整用のデータ (例: STC データセット、またはリポジトリ内の「data/toy_data.json」) と事前試行モデルを準備します。
# Download the STC dataset and unzip into "data_path" dir (fine-tuning on STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # or OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps: 次のリンクから STC のトレインと有効な分割をダウンロードできます: (Baidu Netdisk、Google Drive)
ステップ 2: モデルをトレーニングする
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Single GPU training
または
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Training on 8 GPUs
注: データセットをプレーン テキストで読み取るためのtrain_path引数もトレーニング スクリプトに提供しました。これは、データセットがシステムのメモリに対して大きすぎる場合に、この引数を使用することを検討できます。 train_path使用している場合は、 data_path引数を空のままにしてください)。
ステップ 3: 推論モード
# YOUR_MODEL_PATH: the model path used for generation
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # Do Inference on a corpus
python interact.py --model_checkpoint YOUR_MODEL_PATH # Interact on the terminal
ps: STC のテスト分割は次のリンクからダウンロードできます: (Baidu Netdisk、Google Drive)
トレーニング引数
| 引数 | タイプ | デフォルト値 | 説明 |
|---|---|---|---|
| モデルチェックポイント | str | 「」 | モデル ファイルのパスまたは URL (事前トレーニング モデルと config/vocab ファイルのディレクトリ) |
| 事前訓練された | ブール | 間違い | False の場合、モデルを最初からトレーニングします |
| データパス | str | 「」 | データセットのパス |
| データセットキャッシュ | str | デフォルト = "データセットキャッシュ" | データセット キャッシュのパスまたは URL |
| 電車のパス | str | 「」 | 分散データセットのトレーニング セットのパス |
| 有効なパス | str | 「」 | 分散データセットの検証セットのパス |
| ログファイル | str | 「」 | このパスの下のファイルにログを出力します |
| num_workers | 整数 | 1 | データロード用のサブプロセスの数 |
| n_epochs | 整数 | 70 | トレーニング エポックの数 |
| train_batch_size | 整数 | 8 | トレーニングのバッチサイズ |
| valid_batch_size | 整数 | 8 | 検証用のバッチサイズ |
| max_history | 整数 | 15 | 履歴に保存する以前の交換の数 |
| スケジューラ | str | 「ノーム」 | オプティマイザの手法 |
| n_emd | 整数 | 768 | 設定ファイル内の n_emd の数 (noam の場合) |
| eval_before_start | ブール | 間違い | true の場合、トレーニング前に評価を開始します |
| ウォームアップ_ステップ | 整数 | 5000 | ウォームアップ手順 |
| 有効なステップ数 | 整数 | 0 | 0 でない場合は、X ステップごとに検証を実行します |
| gradient_accumulation_steps | 整数 | 64 | 複数のステップで勾配を蓄積する |
| 最大ノルム | フロート | 1.0 | クリッピング勾配ノルム |
| デバイス | str | "cuda" if torch.cuda.is_available() else "cpu" | デバイス (cuda または cpu) |
| FP16 | str | 「」 | fp16 トレーニングの場合は O0、O1、O2、または O3 に設定します (apex ドキュメントを参照) |
| ローカルランク | 整数 | -1 | 分散トレーニングのローカル ランク (-1: 分散されていない) |
微調整されたモデルによって生成された結果に対して評価が実行されます。
STC データセット (トレーニング/有効分割 (Baidu Netdisk、Google Drive)、テスト分割 (Baidu Netdisk、Google Drive)) すべての応答は、しきい値 0.9 と温度 0.7 の Nucleus サンプリング スキームを使用して生成されます。
| モデル | モデルサイズ | PPL | ブルー-2 | ブルー-4 | 距離-1 | 距離-2 | 貪欲なマッチング | 埋め込み平均 |
|---|---|---|---|---|---|---|---|---|
| Attn-Seq2seq | 73M | 34.20 | 3.93 | 0.90 | 8.5 | 11.91 | 65.84 | 83.38 |
| トランス | 113M | 10月22日 | 6.72 | 3.14 | 8.8 | 13.97 | 66.06 | 83.55 |
| GPT2-雑談 | 88M | - | 2.28 | 0.54 | 10.3 | 16.25 | 61.54 | 78.94 |
| GPT小説 | 95.5M | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83.34 |
| GPT LCCCベース | 95.5M | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| GPT2 LCCCベース | 95.5M | 22.76 | 5.69 | 2.50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-ラージ | 95.5M | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66.25 | 83.63 |
また、クラウドソースのアノテーター 3 人を採用し、2/1/0 スコア スキーマに基づいて各モデルの 200 サンプルを評価しました。詳細については、論文を参照してください。
| モデル | +2 | +1 | +0 | カッパ |
|---|---|---|---|---|
| Attn-Seq2Seq | 27.1% | 21.4% | 51.4% | 0.4544 |
| トランス | 42.4% | 23.6% | 34.0% | 0.4429 |
| GPT2-雑談 | 24.3% | 19.1% | 56.6% | 0.3941 |
| GPT LCCCベース | 46.7% | 21.8% | 31.5% | 0.3954 |
| GPT LCCC-ラージ | 48.6% | 24.5% | 27.0% | 0.4203 |
生成された 1000 個のサンプルをランダムに選択し、有毒生成の統計を作成します。
| 繰り返し | 汚い言葉 | その他の悪いケース |
|---|---|---|
| 23 | 9 | 2 |
STC データセットからシングルターンで生成された例 (STC で微調整):
| 役職 | 応答 |
|---|---|
| ここは実際にはハルビンではなく北京です。 | ハルビンの天気は北京よりも良いようです。雨は小雨で、日中は風が強いです。 |
| 運営者のキャンパス広告コンテストはとても楽しかったです! ハハハ。 | ジャック・マーの広告かと思った。 |
| Delsa S posa キャンディーカラー シリーズのウェディング ドレス、ピンク、ブルー、レッド、パープル、遊び心と新鮮さ、気に入りましたか? | ラストは本当に美しい、とても美しい! |
インタラクティブ スクリプトを使用してマルチターンで生成された例:
| ロエル | 応答 |
|---|---|
| ユーザー | 無駄に私を愛さないで |
| ボット | 実りのない恋はとても苦しいです。 |
| ユーザー | でも好きだったら大丈夫 |
| ボット | 時には、愛はゲームです。 |
| ユーザー | いつも負けてしまう |
| ボット | 私はあなたを愛しているのと同じくらいあなたを愛しています。 |
| ユーザー | 引っ張ってもらえますか? |
| ボット | 引っ張ることができます。 |
| ユーザー | 私の真似しないでください |
| ボット | 私が言いたいのは、あなたにはそれができないということです。 |
| ユーザー | 私にそれを強制するんですよね? |
| ボット | いや、強制的に喋らせているんですよね? |
イーダ・ワン、ペイ・ケ、インヘ・ジェン、カイリー・ファン、ヨン・ジャン、シャオヤン・ジュー、ミンリー・ファン
Zuoxian Ye、Yao Wang、Yifan Pan
LCCC データセットと事前トレーニング済みモデルは、会話生成のための研究を促進することを目的としています。このリポジトリで提供されている LCCC データセットはさまざまなソースから作成されていますが、すべての不適切なコンテンツが含まれているという保証はありません。このデータセットに含まれるすべての内容は、作成者の意見を表すものではありません。このリポジトリには、実際に対話モデルを作成するために必要なモデリング機構の一部のみが含まれています。このリポジトリで提供されるデコード スクリプトは、研究目的のみを目的としています。私たちは責任を負いません。当社のモデルを使用して生成されたコンテンツ。
研究でデータセットまたはモデルを使用する場合は、論文を引用してください。
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}


