YAYI2
1.0.0

[README] [?HF リポジトリ] [?Web バージョン]
中国語 | 英語
[2024.03.28] マジックコミュニティに全モデルとデータをアップロードしました。
[2023.12.22] テクニカルレポート「YAYI 2: Multilingual Open-Source Large Language Models」を公開しました。
YAYI 2 は、Zhongke Wenge によって開発された新世代のオープンソース大規模言語モデルで、Base バージョンと Chat バージョンを含み、パラメータ サイズは 30B です。 YAYI2-30B は、Transformer に基づく大規模な言語モデルで、事前トレーニングに 2 兆トークンを超える高品質の多言語コーパスを使用します。一般的なアプリケーション シナリオとドメイン固有のアプリケーション シナリオでは、何百万もの命令を使用して微調整し、ヒューマン フィードバック強化学習手法を使用してモデルを人間の価値観に合わせて調整します。
今回のオープンソースモデルはYAYI2-30B Baseモデルです。私たちは、Yayi 大型モデルのオープンソースを通じて中国の事前トレーニング済み大型モデル オープンソース コミュニティの発展を促進し、これに積極的に貢献したいと考えています。オープンソースを通じて、私たちはすべてのパートナーと協力して Yayi の大規模モデル エコシステムを構築します。
技術的な詳細については、技術レポート「YAYI 2: 多言語オープンソースの大規模言語モデル」を参照してください。
| データセット名 | サイズ | ? HF モデルの識別 | ダウンロードアドレス | マジックモデルのロゴ | ダウンロードアドレス |
|---|---|---|---|---|---|
| YAYI2 事前学習データ | 500G | wenge-research/yayi2_pretrain_data | データセットのダウンロード | wenge-research/yayi2_pretrain_data | データセットのダウンロード |
| 機種名 | コンテキストの長さ | ? HF モデルの識別 | ダウンロードアドレス | マジックモデルのロゴ | ダウンロードアドレス |
|---|---|---|---|---|---|
| ヤイ2-30B | 4096 | wenge-research/yayi2-30b | モデルのダウンロード | wenge-research/yayi2-30b | モデルのダウンロード |
| YAYI2-30B-チャット | 4096 | wenge-research/yayi2-30b-chat | 近日公開... |
C-Eval、MMLU、CMMLU、AGIEval、GAOKAO-Bench、GSM8K、MATH、BBH、HumanEval、MBPP などの複数のベンチマーク データセットで評価を実施しました。私たちは、言語理解、主題の知識、数学的推論、論理的推論、およびコード生成におけるモデルのパフォーマンスを調べました。 YAYI 2 モデルは、同様のサイズのオープンソース モデルと比較して、大幅なパフォーマンスの向上を示しています。
| 主題の知識 | 数学 | 論理的推論 | コード | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| モデル | C-評価(値) | MMLU | AGIEval | CMMLU | GAOKAOベンチ | GSM8K | 数学 | BBH | HumanEval | MBPP |
| 5ショット | 5ショット | 3/0ショット | 5ショット | ゼロショット | 8/4ショット | 4ショット | 3ショット | ゼロショット | 3ショット | |
| MPT-30B | - | 46.9 | 33.8 | - | - | 15.2 | 3.1 | 38.0 | 25.0 | 32.8 |
| ファルコン-40B | - | 55.4 | 37.0 | - | - | 19.6 | 5.5 | 37.1 | 0.6 | 29.8 |
| LLaMA2-34B | - | 62.6 | 43.4 | - | - | 42.2 | 6.2 | 44.1 | 22.6 | 33.0 |
| 白川2-13B | 59.0 | 59.5 | 37.4 | 61.3 | 45.6 | 52.6 | 10.1 | 49.0 | 17.1 | 30.8 |
| クウェン-14B | 71.7 | 67.9 | 51.9 | 70.2 | 62.5 | 61.6 | 25.2 | 53.7 | 32.3 | 39.8 |
| インターンLM-20B | 58.8 | 62.1 | 44.6 | 59.0 | 45.5 | 52.6 | 7.9 | 52.5 | 25.6 | 35.6 |
| アクイラ2-34B | 98.5 | 76.0 | 43.8 | 78.5 | 37.8 | 50.0 | 17.8 | 42.5 | 0.0 | 41.0 |
| Yi-34B | 81.8 | 76.3 | 56.5 | 82.6 | 68.3 | 67.6 | 15.9 | 66.4 | 26.2 | 38.2 |
| ヤイ2-30B | 80.9 | 80.5 | 62.0 | 84.0 | 64.4 | 71.2 | 14.8 | 54.5 | 53.1 | 45.8 |
OpenCompass Github リポジトリから提供されるソース コードを使用して評価を実施しました。比較モデルについては、2023年12月15日時点のOpenCompassリストに評価結果を掲載しています。 MPT、Falcon、LLaMa 2 など、OpenCompass プラットフォームでの評価に参加していない他のモデルについては、LLaMA 2 によって報告された結果を採用しました。
推論にYAYI2-30Bすばやく使用する方法を示す簡単な例を提供します。この例は 1 台の A100/A800 で実行できます。
git clone https://github.com/wenge-research/YAYI2.git
cd YAYI2conda create --name yayi_inference_env python=3.8
conda activate yayi_inference_envこのプロジェクトには Python 3.8 以降が必要であることに注意してください。
pip install transformers==4.33.1
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install accelerate==0.25.0
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi2-30b" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi2-30b" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( 'The winter in Beijing is' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda' )
>> > pred = model . generate (
** inputs ,
max_new_tokens = 256 ,
eos_token_id = tokenizer . eos_token_id ,
do_sample = True ,
repetition_penalty = 1.2 ,
temperature = 0.4 ,
top_k = 100 ,
top_p = 0.8
)
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))初めてアクセスする場合は、モデルをダウンロードしてロードする必要があるため、時間がかかる場合があります。
このプロジェクトは、分散トレーニング フレームワーク deepspeed に基づく命令の微調整をサポートしています。環境を構成し、対応するスクリプトを実行して、フルパラメータの微調整または LoRA の微調整を開始します。
conda create --name yayi_train_env python=3.10
conda activate yayi_train_envpip install -r requirements.txtpip install --upgrade acceleratepip install flash-attn==2.0.3 --no-build-isolation
pip install triton==2.0.0.dev20221202 --no-deps データ形式: 標準の JSON ファイルであるdata/yayi_train_example.jsonを参照してください。各データは"system"と"conversations"で構成され"conversations" 。 "system"はグローバル ロール設定情報であり、空の文字列にすることができます。 "conversations"とは、人間とヤイのキャラクター間の複数ラウンドの会話です。
操作手順: 次のコマンドを実行して、Yayi モデルのフルパラメータ微調整を開始します。このコマンドは、マルチマシンおよびマルチカード トレーニングをサポートします。16*A100 (80G) 以上のハードウェア構成を使用することをお勧めします。
deepspeed --hostfile config/hostfile
--module training.trainer_yayi2
--report_to " tensorboard "
--data_path " ./data/yayi_train_example.json "
--model_name_or_path " your_model_path "
--output_dir " ./output "
--model_max_length 2048
--num_train_epochs 1
--per_device_train_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 10
--learning_rate 5e-6
--warmup_steps 2000
--lr_scheduler_type cosine
--logging_steps 1
--gradient_checkpointing True
--deepspeed " ./config/deepspeed.json "
--bf16 True または、コマンドラインから開始します。
bash scripts/start.sh指示の微調整に ChatML テンプレートを使用する必要がある場合は、コマンドの--module training.trainer_yayi2 --module training.trainer_chatmlに変更できることに注意してください。Chat テンプレートをカスタマイズする必要がある場合は、次のように変更できます。 Trainer_chatml.py のチャット テンプレート内のシステム 、ユーザー、アシスタントの 3 つの役割の特別なトークンの定義。以下は ChatML テンプレートの例です。このテンプレートまたはカスタム テンプレートがトレーニング中に使用される場合、推論中にも一貫性がある必要があります。
<|im_start|>system
You are a helpful and harmless assistant named YAYI.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today?<|im_end|>
<|im_start|>user
1+1=<|im_end|>
<|im_start|>assistant
1+1 equals 2.<|im_end|>
bash scripts/start_lora.sh事前トレーニング段階では、モデルの言語能力をトレーニングするためにインターネット データを使用するだけでなく、モデルの専門スキルを強化するために一般的に選択されたデータとドメイン データも追加しました。データの分布は以下の通りです。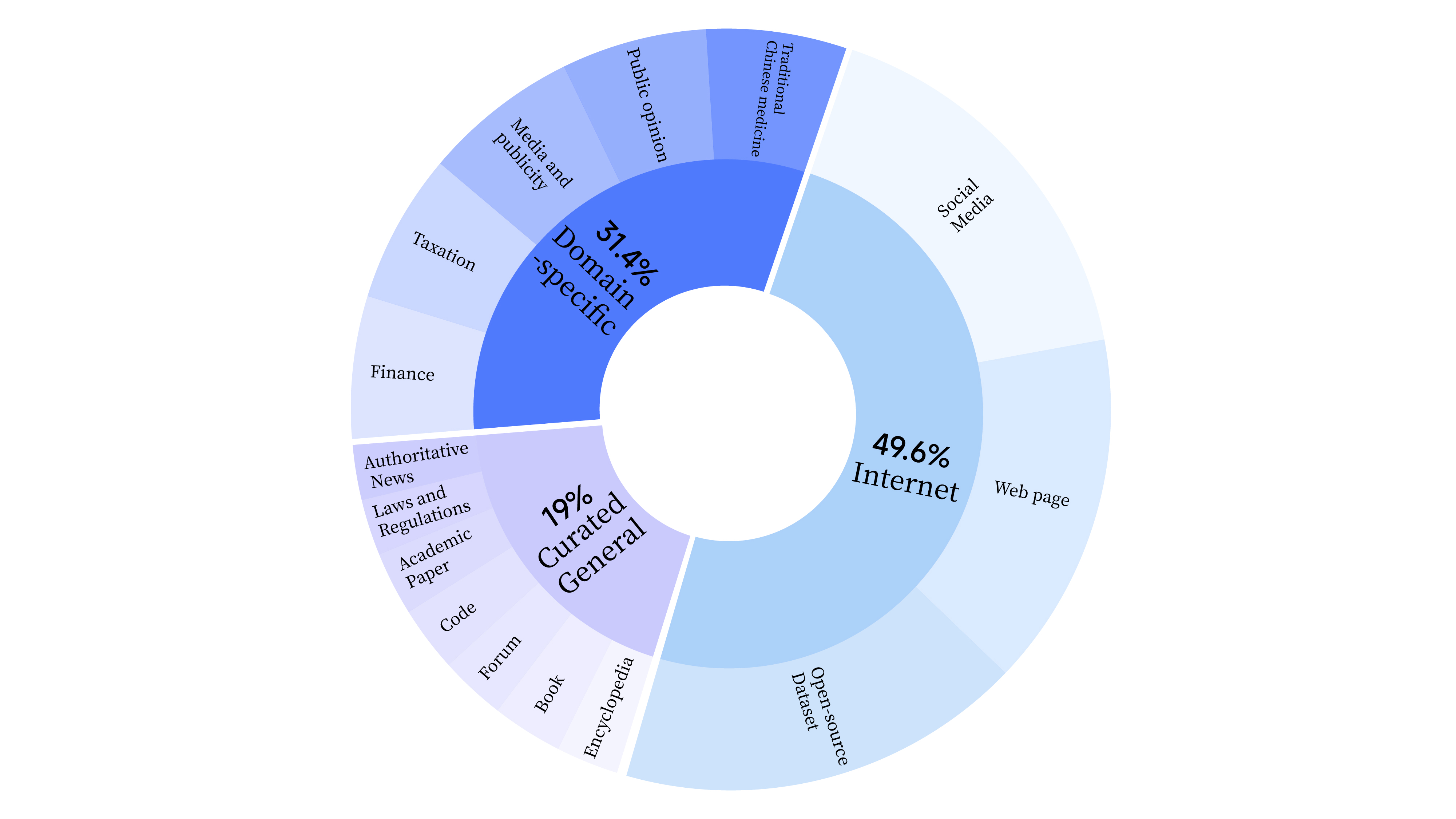
当社は、標準化、ヒューリスティック クリーニング、マルチレベル重複排除、有害性フィルタリングの 4 つのモジュールを含む、あらゆる側面でデータ品質を向上させる一連のデータ処理パイプラインを構築しました。合計 240 TB の生データを収集しましたが、前処理後に残った高品質データは 10.6 TB のみでした。全体的なプロセスは次のとおりです。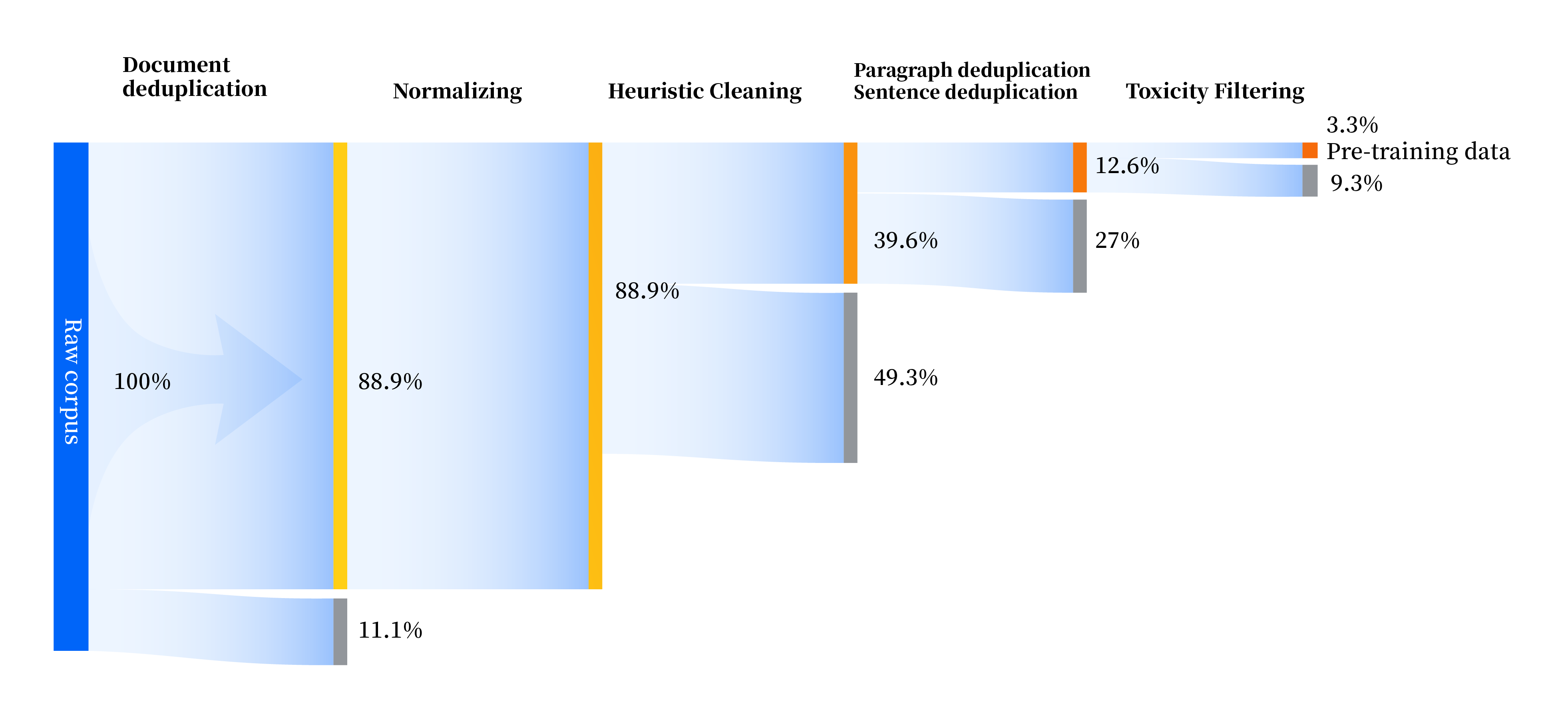

YAYI 2 モデルの損失曲線を次の図に示します。 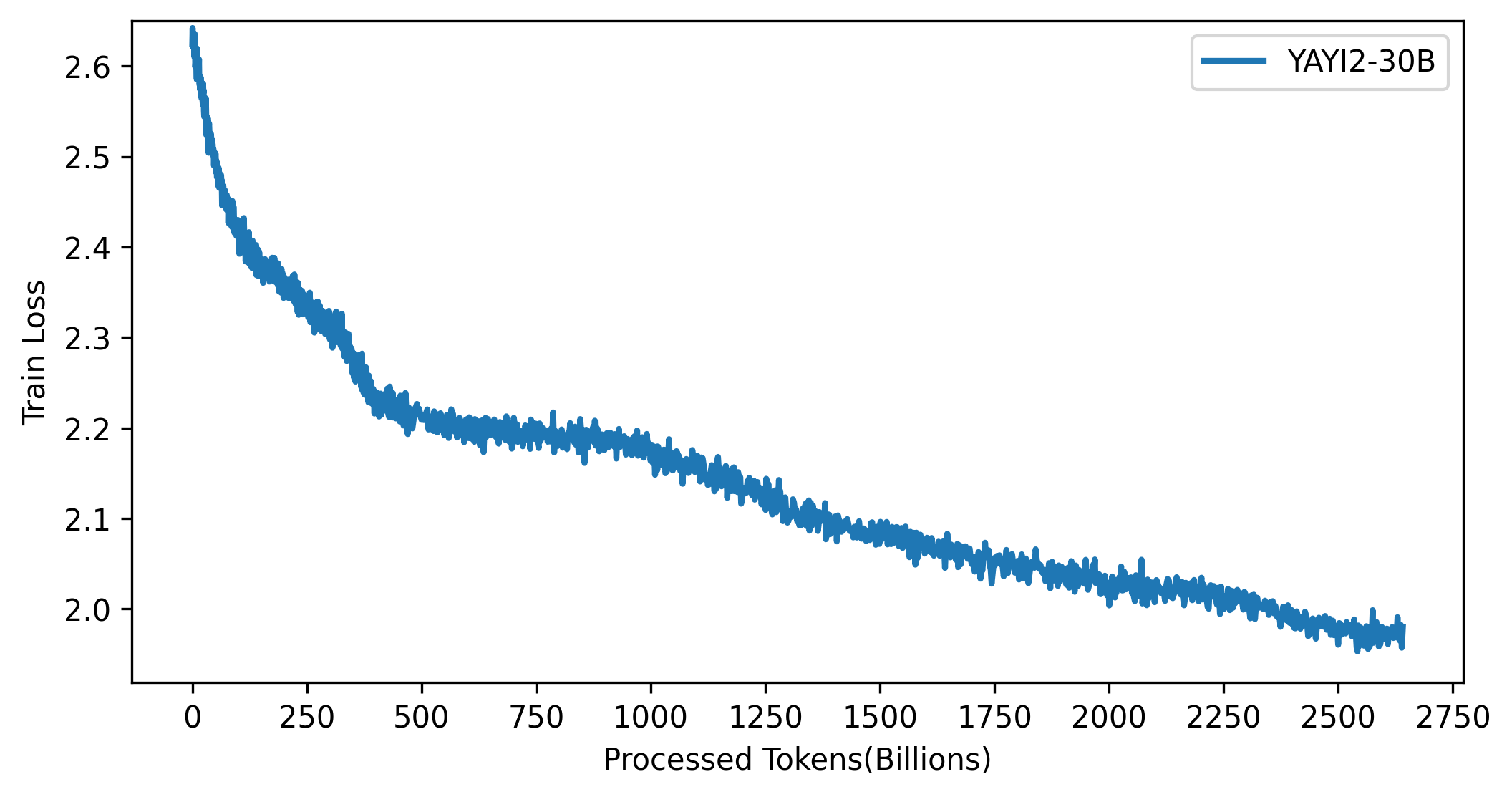
このプロジェクトのコードは、Apache-2.0 プロトコルに準拠したオープン ソースであり、コミュニティによる YAYI 2 モデルおよびデータの使用は、「Yayi YAYI 2 モデル コミュニティ ライセンス契約」に準拠する必要があります。 YAYI 2 シリーズ モデルまたはその派生モデルを商業目的で使用する必要がある場合は、「YAYI 2 モデル商用登録情報」を記入して [email protected] に送信してください。メール受信後 3 営業日以内に返信されます。審査に合格すると商用ライセンスが付与されますので、ご利用の際は「YAYI 2モデル商用ライセンス契約」の内容を厳守してください。
仕事で私たちのモデルを使用する場合は、私たちの論文を引用してください。
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}


