Kosmos X
0.0.1

pip3 install --upgrade kosmosx import torch
from kosmosx . model import Kosmos
# Create a sample text token tensor
text_tokens = torch . randint ( 0 , 32002 , ( 1 , 50 ), dtype = torch . long )
# Create a sample image tensor
images = torch . randn ( 1 , 3 , 224 , 224 )
# Instantiate the model
model = Kosmos ()
text_tokens = text_tokens . long ()
# Pass the sample tensors to the model's forward function
output = model . forward (
text_tokens = text_tokens ,
images = images
)
# Print the output from the model
print ( f"Output: { output } " )次の手順で設定を確立します: accelerate configから: accelerate launch train.py
KOSMOS-1 は、Magneto (Foundation Transformers) に基づくデコーダ専用の Transformer アーキテクチャを使用します。つまり、アテンション モジュールの前 (pre-ln) とその後 (post-ln) の両方で層正規化が追加される、いわゆるサブ LN アプローチを採用するアーキテクチャです。 ln) それぞれのアプローチが言語モデリングと画像理解に関して持つ利点を組み合わせます。モデルは、論文でも説明されている特定のメトリクスに従って初期化されるため、より高い学習率でのより安定したトレーニングが可能になります。
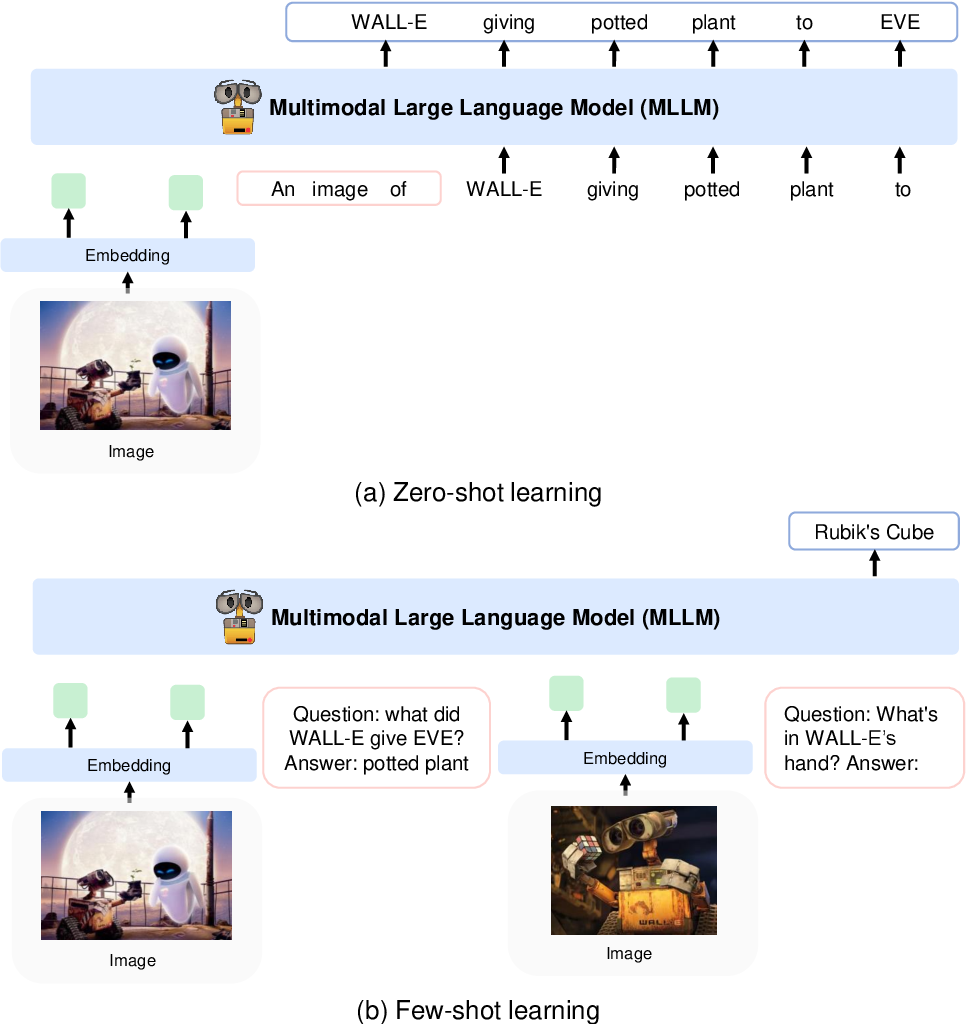
彼らは、CLIP VIT-L/14 モデルを使用して画像を画像特徴にエンコードし、Flamingo で導入された知覚リサンプラーを使用して画像特徴を256 -> 64トークンからプールします。画像特徴は、特別なトークン<image>と</image>で囲まれた入力シーケンスに追加することにより、トークン埋め込みと結合されます。例は、 <s> <image> image_features </image> text </s>です。これにより、画像を同じ順序でテキストと織り交ぜることができます。
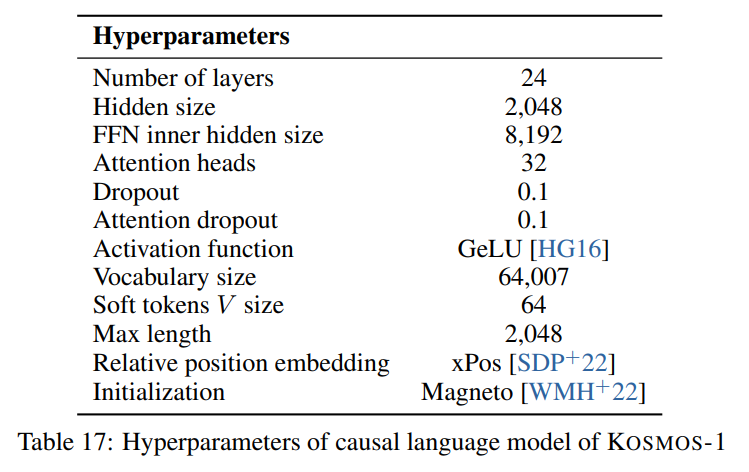
次の図に示されている論文で説明されているハイパーパラメータに従います。
Foundation Transformers のデコーダ専用 Transformer アーキテクチャのトーチスケール実装を使用します。
from torchscale . architecture . config import DecoderConfig
from torchscale . architecture . decoder import Decoder
config = DecoderConfig (
decoder_layers = 24 ,
decoder_embed_dim = 2048 ,
decoder_ffn_embed_dim = 8192 ,
decoder_attention_heads = 32 ,
dropout = 0.1 ,
activation_fn = "gelu" ,
attention_dropout = 0.1 ,
vocab_size = 32002 ,
subln = True , # sub-LN approach
xpos_rel_pos = True , # rotary positional embeddings
max_rel_pos = 2048
)
decoder = Decoder (
config ,
embed_tokens = embed ,
embed_positions = embed_positions ,
output_projection = output_projection
)画像モデル (CLIP VIT-L/14) には、事前トレーニングされた OpenClip モデルを使用します。
from transformers import CLIPModel
clip_model = CLIPModel . from_pretrained ( "laion/CLIP-ViT-L-14-laion2B-s32B-b82K" ). vision_model
# projects image to [batch_size, 256, 1024]
features = clip_model ( pixel_values = images )[ "last_hidden_state" ]論文ではハイパーパラメータが指定されていないため、知覚リサンプラーのデフォルトのハイパーパラメータに従います。
from flamingo_pytorch import PerceiverResampler
perceiver = PerceiverResampler (
dim = 1024 ,
depth = 2 ,
dim_head = 64 ,
heads = 8 ,
num_latents = 64 ,
num_media_embeds = 256
)
# projects image features to [batch_size, 64, 1024]
self . perceive ( images ). squeeze ( 1 )モデルは2048の隠れ次元を想定しているため、 nn.Linear層を使用して画像特徴を正しい次元に投影し、Magneto の初期化スキームに従って初期化します。
image_proj = torch . nn . Linear ( 1024 , 2048 , bias = False )
torch . nn . init . normal_ (
image_proj . weight , mean = 0 , std = 2048 ** - 0.5
)
scaled_image_features = image_proj ( image_features )この論文では、 64007トークンの語彙を持つ SentencePiece について説明しています。簡略化するために (トレーニング コーパスが利用できないため)、次に最適なオープンソースの代替手段として、HuggingFace の事前トレーニング済み T5-large トークナイザーを使用します。このトークナイザーには32002トークンの語彙があります。
from transformers import T5Tokenizer
tokenizer = T5Tokenizer . from_pretrained (
"t5-large" ,
additional_special_tokens = [ "<image>" , "</image>" ],
extra_ids = 0 ,
model_max_length = 1984 # 2048 - 64 (image features)
)次に、 nn.Embeddingレイヤーを使用してトークンを埋め込みます。実際には、bitandbytes のbnb.nn.Embeddingを使用します。これにより、後で 8 ビット AdamW を使用できるようになります。
import bitsandbytes as bnb
embed = bnb . nn . Embedding (
32002 , # Num embeddings
2048 , # Embedding dim
padding_idx
)位置埋め込みの場合は、以下を使用します。
from torchscale . component . embedding import PositionalEmbedding
embed_positions = PositionalEmbedding (
2048 , # Num embeddings
2048 , # Embedding dim
padding_idx
)また、出力射影層を追加して隠れ次元を語彙サイズに射影し、Magneto の初期化スキームに従って初期化します。
output_projection = torch . nn . Linear (
2048 , 32002 , bias = False
)
torch . nn . init . normal_ (
output_projection . weight , mean = 0 , std = 2048 ** - 0.5
)フォワード パスで既に埋め込まれている機能を受け入れられるようにするには、デコーダーに若干の変更を加える必要がありました。これは、上で説明したより複雑な入力シーケンスを可能にするために必要でした。変更はtorchscale/architecture/decoder.pyの 391 行目の次の差分に表示されます。
+ if kwargs.get("passed_x", None) is None:
+ x, _ = self.forward_embedding(
+ prev_output_tokens, token_embeddings, incremental_state
+ )
+ else:
+ x = kwargs["passed_x"]
- x, _ = self.forward_embedding(
- prev_output_tokens, token_embeddings, incremental_state
- )以下は、論文で言及されているデータセットのメタデータを含むマークダウン テーブルです。
| データセット | 説明 | サイズ | リンク |
|---|---|---|---|
| ザ・パイル | 多様な英語テキストコーパス | 800GB | ハグフェイス |
| 一般的なクロール | ウェブクロールデータ | - | 一般的なクロール |
| ライオン-400M | Common Crawl からの画像とテキストのペア | 400Mペア | ハグフェイス |
| ライオン-2B | Common Crawl からの画像とテキストのペア | 2Bペア | ArXiv |
| コヨ | Common Crawl からの画像とテキストのペア | 700Mペア | ギットハブ |
| 概念的なキャプション | 画像と代替テキストのペア | 1500万ペア | ArXiv |
| インターリーブされた CC データ | Common Crawl のテキストと画像 | 7,100 万件のドキュメント | カスタム データセット |
| ストーリー閉じる | 常識的な推論 | 16,000 個の例 | ACLアンソロジー |
| ヘラスワッグ | コモンセンスNLI | 70,000 個の例 | ArXiv |
| ウィノグラードスキーマ | 単語の曖昧さ | 273 例 | PKRR 2012 |
| ウィノグランデ | 単語の曖昧さ | 1.7k の例 | AAAI 2020 |
| ピカ | 物理的な常識 QA | 16,000 個の例 | AAAI 2020 |
| ブールQ | QA | 15,000 個の例 | ACL 2019 |
| CB | 自然言語推論 | 250 の例 | シンとベドゥトゥング 2019 |
| コパ | 因果推論 | 1,000 個の例 | AAAI春季シンポジウム2011 |
| 相対サイズ | 常識的な推論 | 486足 | アルザイブ 2016 |
| 記憶色 | 常識的な推論 | 720 件の例 | ArXiv 2021 |
| 色の用語 | 常識的な推論 | 320 件の例 | ACL 2012 |
| IQテスト | 非言語的推論 | 50の例 | カスタム データセット |
| ココのキャプション | 画像のキャプション | 413k 画像 | パミ2015 |
| Flickr30k | 画像のキャプション | 31,000 枚の画像 | TACL2014 |
| VQAv2 | ビジュアルQA | 100万のQAペア | CVPR 2017 |
| ビズウィズ | ビジュアルQA | 31,000のQAペア | CVPR 2018 |
| WebSRC | ウェブQA | 1.4k の例 | EMNLP 2021 |
| イメージネット | 画像分類 | 128万枚の画像 | CVPR 2009 |
| カブ | 画像分類 | 200種類の鳥 | TOG2011 |
アパッチ


