Copulas
v0.12.0 - 2024-11-12
このリポジトリは、DataCebo のプロジェクトである The Synthetic Data Vault Project の一部です。

Copulas は、コピュラ関数を使用して多変量分布をモデル化し、そこからサンプリングするための Python ライブラリです。数値データのテーブルが与えられた場合、コピュラを使用して分布を学習し、同じ統計的特性に従って新しい合成データを生成します。
主な特徴:
多変量データをモデル化します。アルキメディアン コピュラ、ガウス コピュラ、つるコピュラなど、さまざまな一変量分布とコピュラから選択します。
モデルを構築した後、実際のデータと合成データを視覚的に比較します。視覚化は、1D ヒストグラム、2D 散布図、および 3D 散布図として利用できます。
学習したパラメータにアクセスして操作します。モデルの内部に完全にアクセスできるため、パラメーターを好みに合わせて設定または調整できます。
pip または conda を使用して Copulas ライブラリをインストールします。
pip install copulasconda install -c conda-forge copulasデモ データセットの使用を開始します。このデータセットには 3 つの数値列が含まれています。
from copulas . datasets import sample_trivariate_xyz
real_data = sample_trivariate_xyz ()
real_data . head ()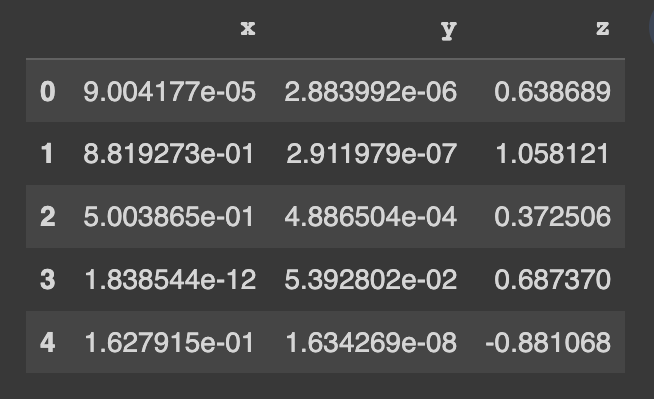
コピュラを使用してデータをモデル化し、それを使用して合成データを作成します。コピュラ ライブラリには、ガウス コピュラ、つるコピュラ、アルキメディアン コピュラなど、多くのオプションが用意されています。
from copulas . multivariate import GaussianMultivariate
copula = GaussianMultivariate ()
copula . fit ( real_data )
synthetic_data = copula . sample ( len ( real_data ))実際のデータと合成データを並べて視覚化します。これを 3D で実行してみましょう。完全なデータセットをご覧ください。
from copulas . visualization import compare_3d
compare_3d ( real_data , synthetic_data )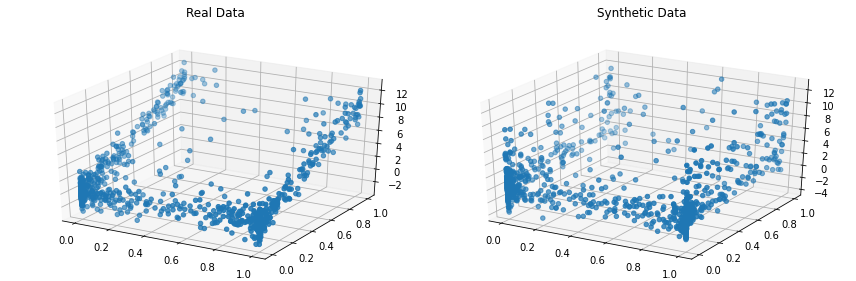
以下をクリックして、Colab ノートブックでコードを実行し、新しい機能を発見してください。
Copulas ライブラリの詳細については、ドキュメント サイトをご覧ください。
質問や問題はありますか? Slack チャンネルに参加して、Copulas と合成データについて詳しく話し合いましょう。バグを見つけた場合や機能リクエストがある場合は、GitHub で問題をオープンすることもできます。
Copulas に貢献することに興味がありますか?始めるには、貢献ガイドをお読みください。
Copulas オープン ソース プロジェクトは、2018 年に MIT の Data to AI Lab で最初に開始されました。長年にわたってライブラリを構築および保守してきた貢献者チームに感謝します。
寄稿者を表示

Synthetic Data Vault プロジェクトは、2016 年に MIT の Data to AI Lab で初めて作成されました。4 年間の研究と企業との協力を経て、プロジェクトの成長を目的として 2020 年に DataCebo を作成しました。現在、DataCebo は、合成データの生成と評価のための最大のエコシステムである SDV の開発者として誇りを持っています。ここには、合成データをサポートする次のような複数のライブラリがあります。
SDV パッケージの使用を開始してください。これは完全に統合されたソリューションであり、合成データのワンストップ ショップです。または、特定のニーズに応じてスタンドアロン ライブラリを使用します。


