Amazon Bedrock と Amazon Neptune を使用して非構造化財務データの隠れたつながりを明らかにする
このリポジトリには、Generative AI とナレッジ グラフを組み合わせて、金融サービス用の非構造化データを処理するためのスケーラブルなイベント駆動型のサーバーレス システムを作成する方法を示すプロトタイプ ソリューションをデプロイするためのコードが含まれています。このソリューションは、組織内の資産管理者が投資ポートフォリオの隠れたつながりを明らかにするのに役立ち、金融ニュースを利用して投資ポートフォリオとのつながりを理解するためのサンプルの使いやすいユーザー インターフェイスを提供します。
ビジネスユースケース
資産運用会社は通常、ポートフォリオ内の多数の企業に投資します。これらのニュースは、市場の動きを先取りし、投資機会を特定し、投資をより適切に管理するのに役立つため、これらの企業に関連するニュースを追跡できる必要があります。ポートフォリオ。
一般に、ニュース追跡は、投資先企業名を使用して単純なキーワードベースのニュースアラートを設定することで簡単に行うことができますが、ニュースイベントが投資先企業に直接影響を与えない場合、これはますます困難になります。たとえば、影響は投資先企業のサプライヤーに及ぶ可能性があり、企業のサプライチェーンを混乱させる可能性があります。あるいは、投資先企業の顧客の顧客に影響が及ぶ可能性もあります。これらの企業の収益が少数の主要顧客に集中している場合、投資に対して財務的にマイナスの影響を与える可能性があります。
このような二次または三次の影響を特定することは困難であり、追跡することはさらに困難です。この自動化されたソリューションを使用すると、資産管理者は投資ポートフォリオを取り巻く関係性のナレッジ グラフを構築し、この知識を利用して最新ニュースから相関関係や洞察を引き出すことができます。
建築
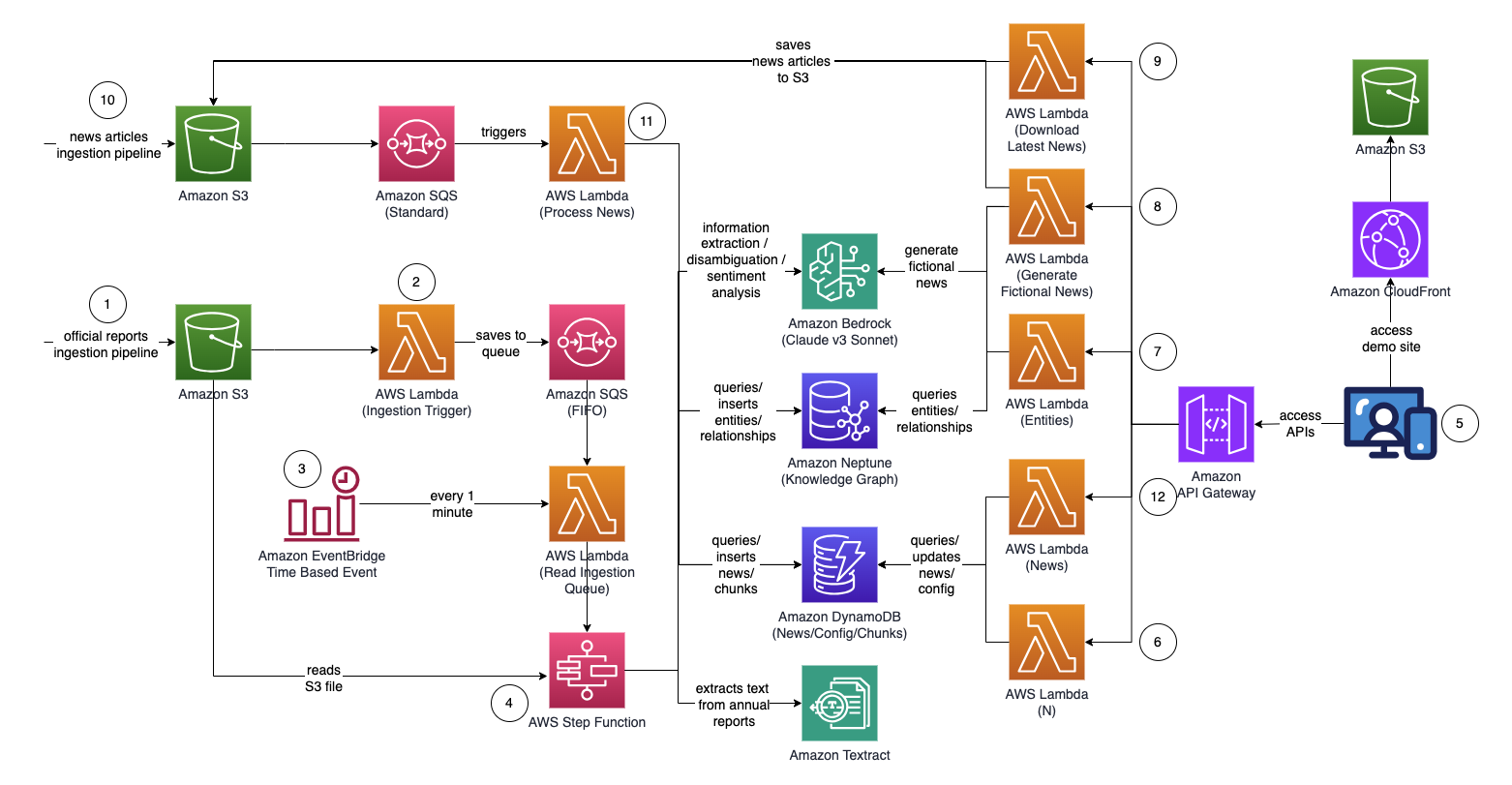
ステップ関数グラフ (ポイント #4 以降)
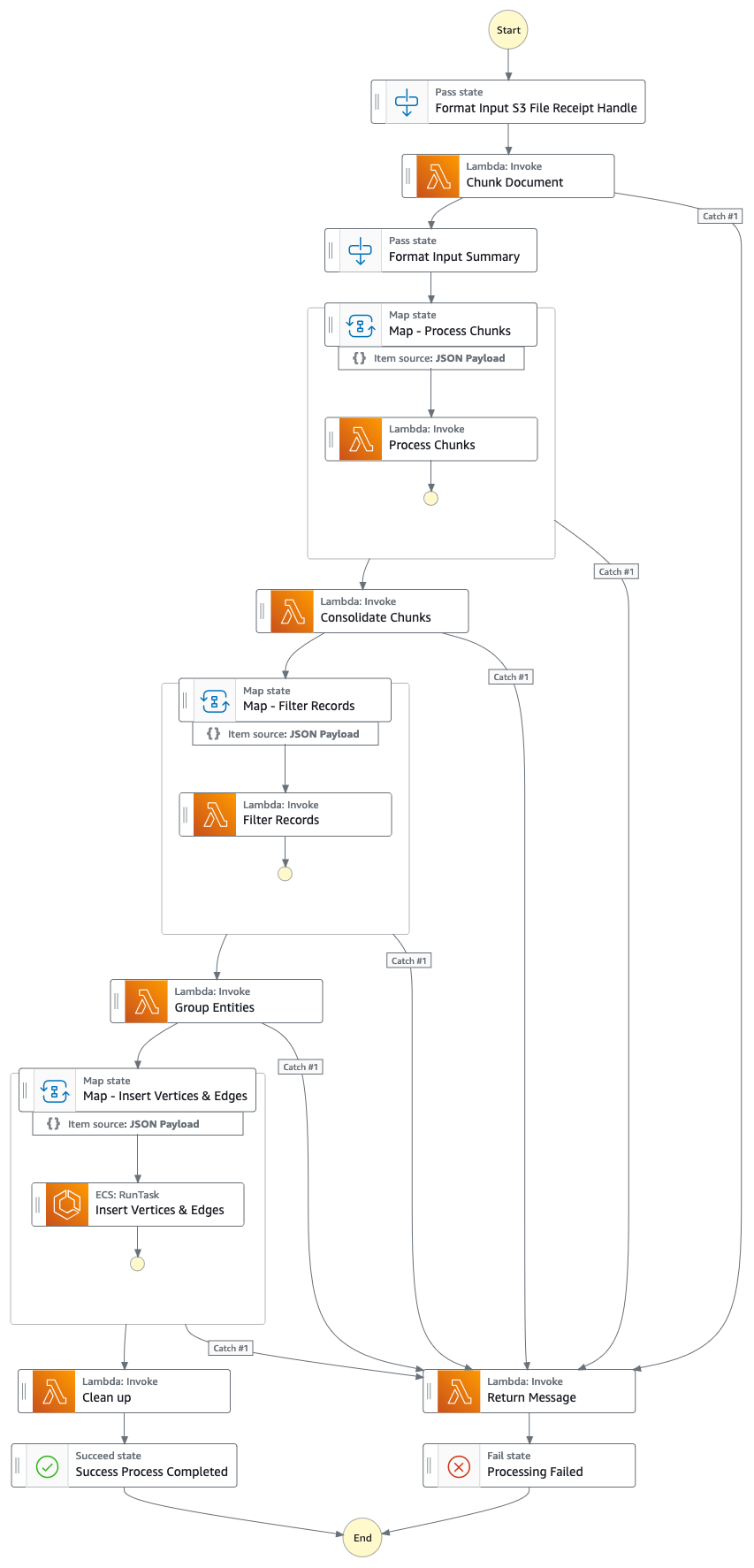
ソリューションの流れ(ステップバイステップ)
- 公式プロキシ/年次/10k レポート (.PDF) を Amazon S3 バケットにアップロードします。
- アップロード先の S3 バケットの名前は、CloudFormation コンソール - メイン スタック出力 - 「IngestionBucket」から取得できます。
- (ニュース/タブロイド紙ではなく) ナレッジ グラフに不正確なデータが含まれることを最小限に抑えるために、使用するレポートは公式に公開されたレポートである必要があることに注意してください。
- S3 イベント通知は、S3 バケット/ファイル名を Amazon Simple Queue Service キュー (FIFO) に送信する AWS Lambda 関数をトリガーします。
- FIFO キューを使用すると、レポート取り込みプロセスが確実に順次実行され、ナレッジ グラフに重複データが取り込まれる可能性が低くなります。
- Amazon EventBridge の時間ベースのイベントは 1 分ごとに実行され、AWS Lambda 関数を呼び出します。この関数は、次に利用可能なキュー メッセージを SQS から取得し、AWS Step Function の実行を非同期的に開始します。
- ステップ関数ステート マシンは、重要な情報を抽出してナレッジ グラフに挿入することで、アップロードされたドキュメントを処理する一連のタスクを実行します。
- タスク
- Amazon Textract を使用して、Amazon S3 のプロキシ/年次/10k レポート ファイル (PDF) からテキストコンテンツを抽出し、それを複数の小さなテキストチャンクに分割して処理します。テキストチャンクを Amazon DynamoDB に保存します。
- Amazon Bedrock で Anthropic の Claude v3 Sonnet を使用して、最初のいくつかのテキストチャンクを処理して、レポートが参照している主要なエンティティと、関連する属性 (業界など) を特定します。
- DynamoDB からテキストチャンクを取得し、テキストチャンクごとにラムダ関数を呼び出して、エンティティ (会社/個人) と、Amazon Bedrock を使用して主要エンティティとの関係 (顧客/サプライヤー/パートナー/競合他社/ディレクター) を抽出します。
- 抽出されたすべての情報を統合する
- Amazon Bedrock を使用して、ノイズや無関係なエンティティ (つまり、「消費者」などの一般的な用語) を除外します。
- Amazon Bedrock を使用して、ナレッジグラフからの類似エンティティのリストに対して抽出された情報を使用して推論することにより、曖昧さを解消します。エンティティが存在しない場合は、エンティティを挿入します。それ以外の場合は、ナレッジ グラフにすでに存在するエンティティを使用します。抽出されたすべての関係を挿入します。
- SQS キュー メッセージと S3 ファイルを削除してクリーンアップを実行します。
- このステップが完了すると、ナレッジ グラフが更新され、使用できるようになります。
- ユーザーは React ベースの Web アプリケーションにアクセスして、エンティティ/センチメント/接続パス情報が充実したニュース記事を表示します。
- Web アプリケーションの URL は、CloudFormation コンソール - Web アプリケーション スタックの出力 - 「WebApplicationURL」からコピーできます。
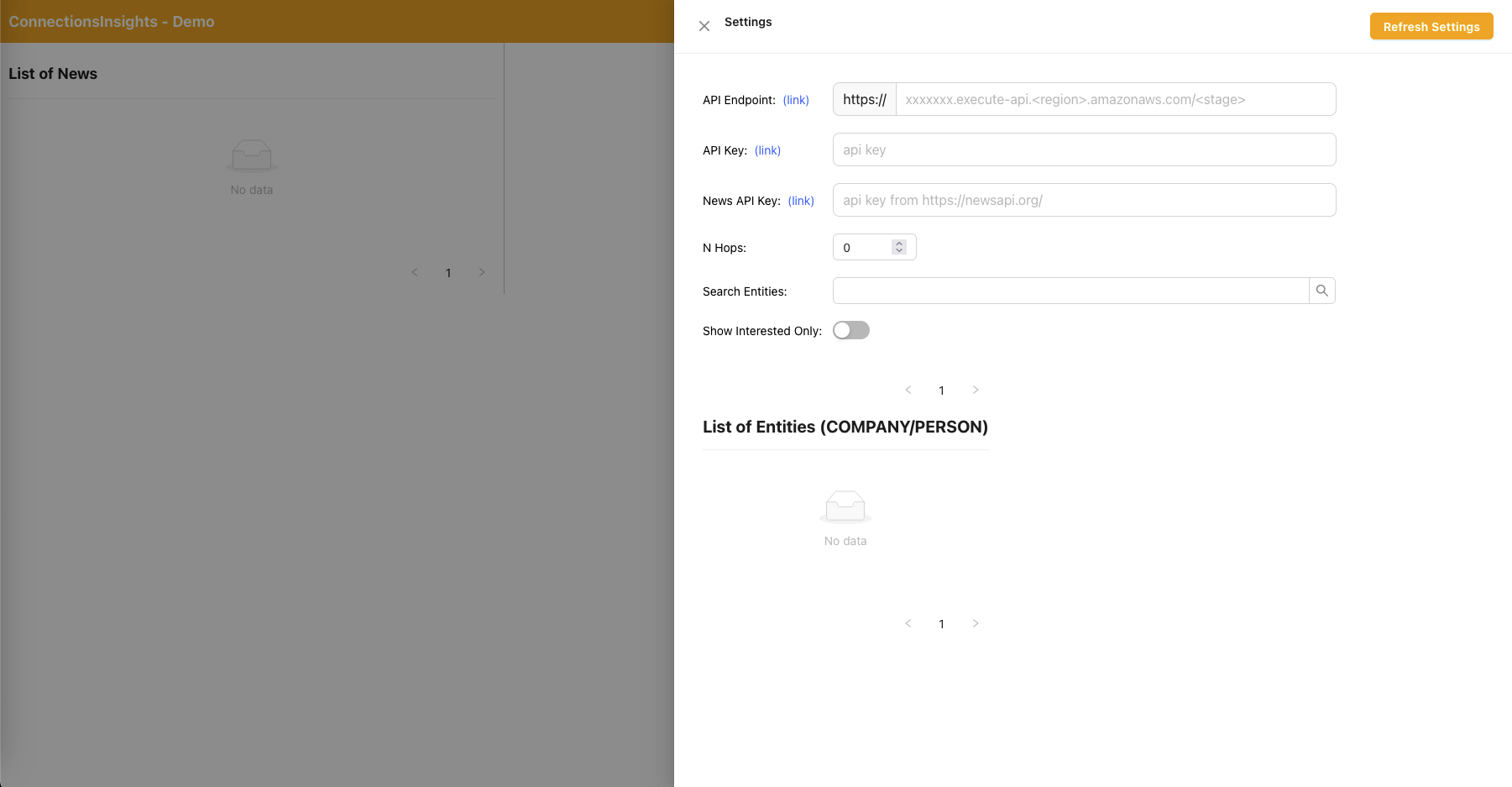
- これはデモ目的のサンプル ソリューションであるため、ユーザーは右上隅にある歯車アイコンをクリックして、Web アプリケーション上の API エンドポイント、API キー、および News API キーを指定します。
- API エンドポイントは、CloudFormation コンソール - メイン スタック出力 - 「APIEndpoint」からコピーできます。
- API キーは、API Gateway API キー コンソール - メイン スタックからコピーできます。
- News API キーは、アカウントを無料で作成した後、NewsAPI.org から取得できます。
- 値を入力したら、「設定を更新」ボタンをクリックします。
- Web アプリケーションを使用して、ユーザーは監視する接続パス上のホップ数 (デフォルトは N=2) を指定します。
- これを行うには、右上隅にある歯車アイコンをクリックし、N の値を指定します。
- Web アプリケーションを使用して、ユーザーは追跡するエンティティのリストを指定します。
- これを行うには、右上隅にある歯車アイコンをクリックし、対応するエンティティを INTERESTED=YES/NO としてマークする「Interested」スイッチを切り替えます。
- これは重要な手順であり、ニュース記事が処理される前に実行する必要があります。
- 架空のニュースを生成するには、ユーザーは「サンプル ニュースを生成」ボタンをクリックして、ニュース取り込みプロセスに供給されるランダムなコンテンツを含む 10 個のサンプル金融ニュースを生成します。
- コンテンツは Amazon Bedrock を使用して生成され、純粋にフィクションです。
- 実際のニュースをダウンロードするには、ユーザーは「最新ニュースをダウンロード」ボタンをクリックして、今日起こったトップ ニュース (NewsAPI.org を利用) をダウンロードします。
- ニュース (.TXT) を S3 バケットにアップロードします。
- アップロード先の S3 バケットの名前は、CloudFormation コンソール - メイン スタック出力 - 「NewsBucket」から取得できます。
- ステップ #8 または #9 ではニュースを S3 バケットに自動的にアップロードしましたが、AWS Data Exchange やサードパーティのニュースプロバイダーなどの好みのニュースプロバイダーとの統合を構築して、ニュース記事をファイルとして S3 バケットにドロップすることもできます。
- ニュース データ ファイルのコンテンツは、<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text> の形式にする必要があります。
- S3 イベント通知は、S3 バケット/ファイル名を SQS (標準) に送信し、複数の Lambda 関数をトリガーしてニュース データを並列処理します。
- Amazon Bedrock を使用して、ラムダ関数は、ニュースで言及されたエンティティを、言及されたエンティティの関連情報、関係性、センチメントとともに抽出します。
- 次に、ナレッジ グラフと照合し、Amazon Bedrock を使用して、ニュースおよびナレッジ グラフ内から入手可能な情報を使用して推論して曖昧さを排除し、対応するエンティティを特定します。
- エンティティが見つかると、ナレッジ グラフ内で INTERESTED=YES とマークされたエンティティに接続する、N=2 ホップ以内にある接続パスを検索して返します。
- Web アプリケーションは 1 秒ごとに自動更新され、最新の処理済みニュースのセットが取得されて Web アプリケーションに表示されます。
React Web アプリケーション - 設定
グラフエクスプローラー
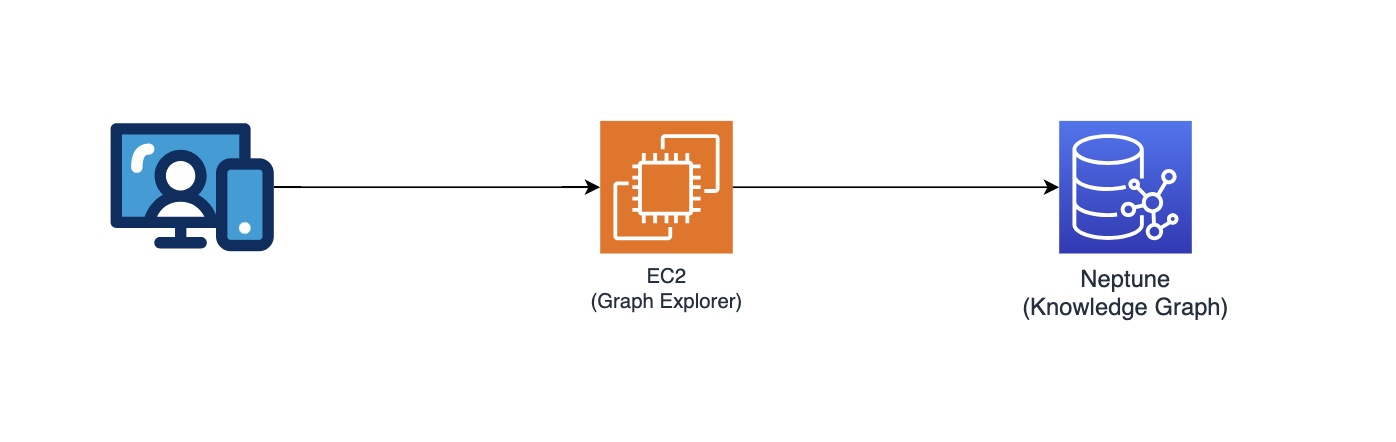
このリポジトリは、ユーザーが抽出されたエンティティと関係を視覚化できるようにする React ベースの Web アプリケーションである Graph Explorer (github/aws/graphexplorer) もデプロイします。
- Graph Explorer にアクセスするには、CloudFormation コンソール - メイン スタック出力 - 「GraphExplorer」から URL を取得します。
- Web アプリケーションにアクセスすると、サイトに使用されている証明書が自己署名されているため、ブラウザーに潜在的なセキュリティ リスクに関する警告が表示されます。そのまま続行しても構いません。警告を取り除くには、これをお読みください。
- 起動すると、アプリケーションは自動的に AWS Neptune データベースに接続し、そのデータを同期します。更新アイコンをクリックすると、いつでもデータを再同期できます。
- 右上の「Open Graph Explorer」をクリックして、ナレッジグラフの視覚化を開始します。
- Graph Explorer の詳細については、github/aws/graphexplorer にアクセスしてください。
- Graph Explorer はソリューションの一部として必須ではありませんが、これにより、抽出された関係を簡単に探索できることに注意してください。
デモ - グラフ エクスプローラーの入門
グラフエクスプローラー入門.mp4
Graph Explorer の機能に関する別のビデオ デモは次のとおりです: ビデオ デモへのリンク
グラフ エクスプローラー - ナレッジ グラフ
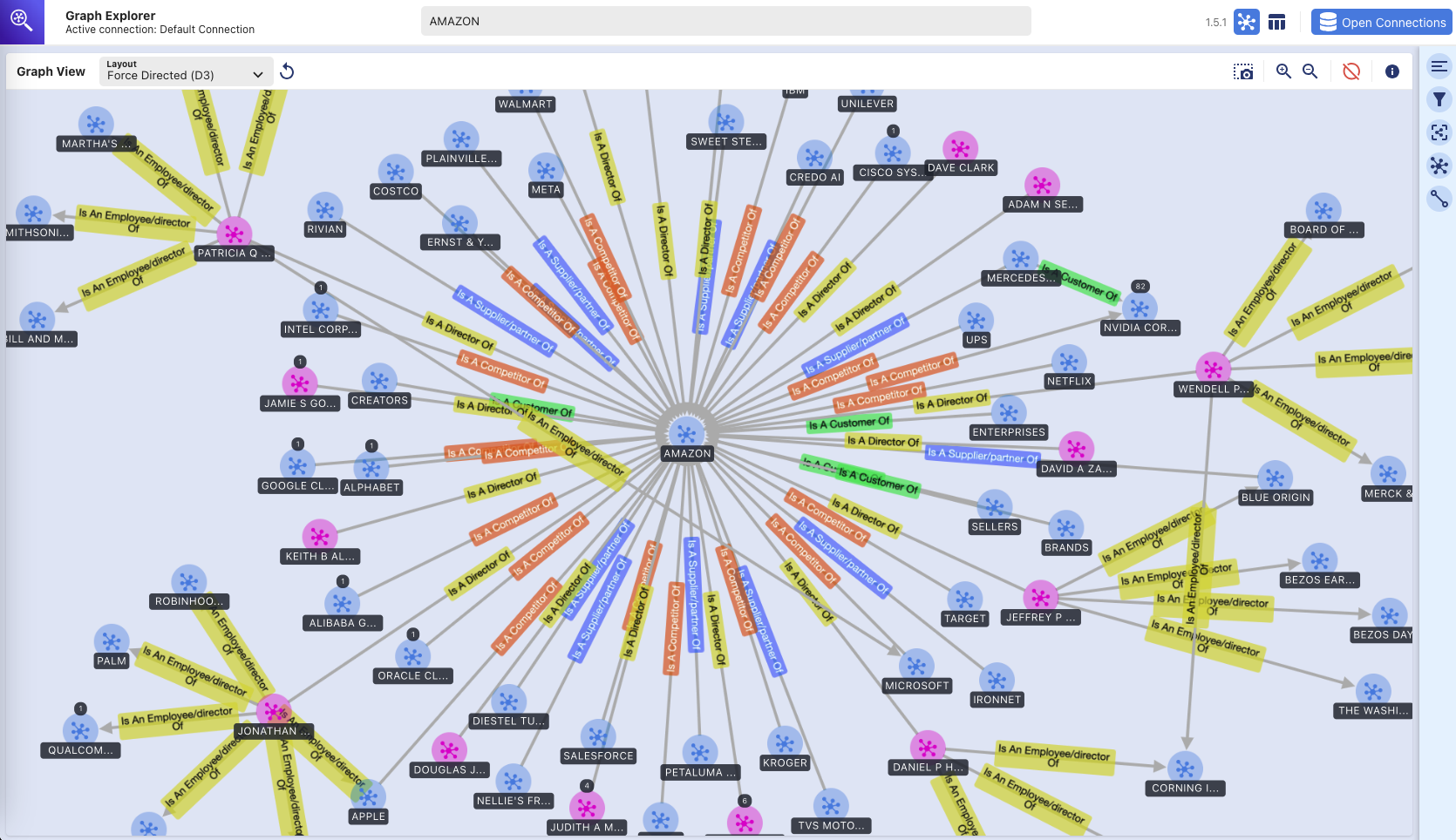
(Graph Explorer ツールを使用した Amazon Neptune グラフ データベースの視覚的な探索)
導入手順
このリポジトリは、プロトタイプ ソリューション全体を 2 つの CDK スタックにデプロイする CDK アプリケーションを提供します。
- メインアプリケーションスタック (「メインスタック」) は、必要なサービスと Amazon Bedrock モデルがある任意のリージョン (us-east-1、us-west-2 など) にデプロイできます。
- ウェブ アプリケーション スタック (「webapp スタック」) は、AWS WAF が必要なため、 us-east-1にのみデプロイできます。
2 つのスタックを異なるリージョンにデプロイすることも、同じリージョン (つまり us-east-1) にデプロイすることもできます。
使用されているAWSサービス
- アマゾンの岩盤
- アマゾン ネプチューン
- Amazon テキストラクト
- Amazon DynamoDB
- AWS ステップ関数
- AWSラムダ
- Amazon シンプル キュー サービス (SQS)
- Amazon イベントブリッジ
- Amazon シンプル ストレージ サービス (S3)
- Amazon CloudFront
- AWS WAF
- Amazon Elastic Compute Cloud (EC2)
- アマゾン VPC
- Amazon APIゲートウェイ
- AWS ID とアクセス管理
事前準備事項
- Amazon Bedrock - Anthropic Claude v3 Sonnet にアクセスする必要があります。 Amazon Bedrock でモデルへのアクセスを設定するには、これをお読みください。
- Python - Python 3 以降が必要です。
- ノード - v18.0.0 以降が必要です。
- Docker - Docker Buildx では v24.0.0 以降が必要で、docker デーモンが実行されています。
仮想環境をセットアップする
MacOS および Linux で virtualenv を手動で作成するには:
init プロセスが完了し、virtualenv が作成されたら、次の手順を使用して virtualenv をアクティブ化できます。
$ source .venv/bin/activate
Windows プラットフォームの場合は、次のように virtualenv をアクティブ化します。
% .venvScriptsactivate.bat
virtualenv がアクティブ化されたら、必要な依存関係をインストールできます。
$ pip install -r requirements.txt
導入前
CDK 経由でコードを AWS アカウントに初めてデプロイする場合は、まず us-east-1 とデプロイ先のリージョンの両方で AWS アカウントをブートストラップする必要があります。それ以外の場合は、この手順をスキップできます。
$ cdk bootstrap aws://<account no>/us-east-1 aws://<account no>/<aws region to deploy main application stack>
次に、以下のコマンドを実行して次のことを行います。
- ReactベースのWebアプリケーションを構築する
- AWS Lambda レイヤーの作成に必要な Python 依存関係をダウンロードします。
- カスタム ライブラリのコピー (connectionsinsight)
展開する
ソリューションを展開するには (約 30 分かかります):
$ ./deploy.sh <aws region to deploy main application stack>
掃除
ソリューションを破棄するには:
$ ./destroy.sh <aws region where main application stack was deployed>
S3 バケットが空ではないために削除に失敗した場合は、cdk destroy プロセスの一部として S3 バケットが空になった後に S3 バケットに書き込まれたアクセス ログ ファイルが原因である可能性があります。この問題が発生した場合は、それらのバケットを空にして、クリーンアップ コマンドを再度実行してください。


