gen ai document sumarization
1.0.0
このプロジェクトでは、ドキュメント コンテンツの要約を自動化するための、オープンソースの生成 AI モデル、特に Transformer アーキテクチャに基づくモデルの可能性を探ります。目標は、既存の生成 AI モデルを評価および適用して、非構造化ドキュメントの分析、コンテキストの理解、要約の生成を行うことです。
これを達成するために、私は 2 つの著名なモデル、t5-small と facebook/bart-base を微調整し、要約パフォーマンスの向上に重点を置きました。
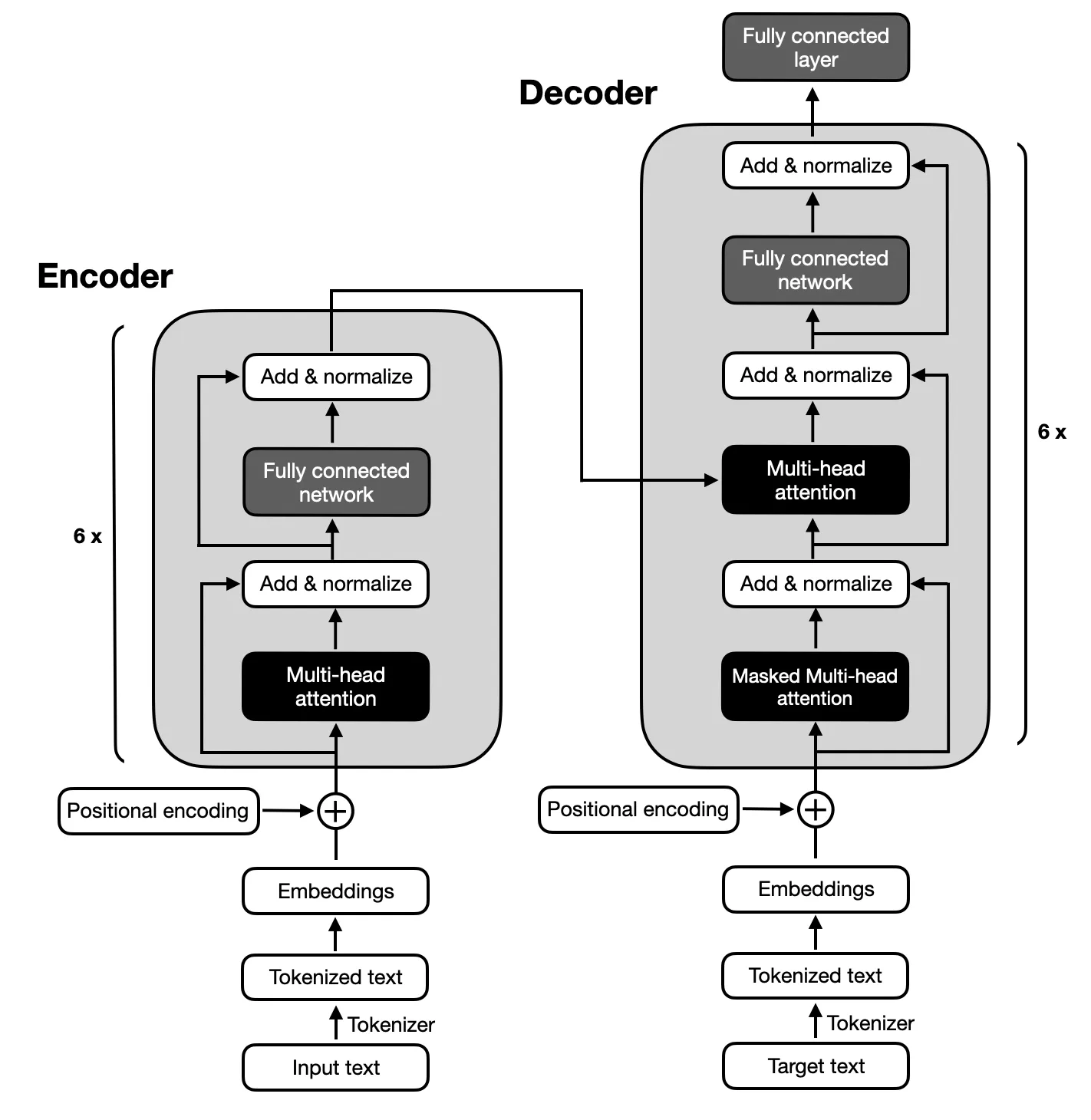
テキストの要約に必要な入力シーケンスと出力シーケンスの間の複雑なマッピングのため、オリジナルの Transformers によって提案されたアーキテクチャに従うエンコーダ/デコーダ モデルに焦点が当てられています。エンコーダ/デコーダ モデルは、これらのシーケンス内の関係を捉えることに優れているため、このタスクに適しています。
Python 3.x がシステムにインストールされていることを確認してください。次に、以下の手順に従って環境をセットアップします。
$ xcode-select --install
$ pip3 install --upgrade pip
$ pip3 install --upgrade setuptools$ pip3 install -r requirements.txt
python3 main.pyプロジェクトは 6 つの主要なフェーズで構成されます。
T5 モデルと BART モデルの微調整に使用されたデータセットは Big Patent Dataset で、これは 130 万件の米国特許文書と人間が作成した抽象的な要約で構成されています。このデータセット内の各文書は共同特許分類 (CPC) コードに基づいて分類されており、人間の必需品から物理学や電気まで幅広いトピックをカバーしています。この多様性により、モデルはさまざまな言語使用や専門用語に遭遇することが保証され、これは堅牢な要約機能を開発するために重要です。
Big Patent Dataset が選択されたのは、複雑な文書を要約するというプロジェクトの目標との関連性からです。特許は本質的に詳細かつ技術的なものであるため、核となるコンテンツとコンテキストを維持しながら情報を凝縮するモデルの能力をテストするのに理想的な課題となります。データセットの構造化された形式と高品質の概要の存在は、正確で一貫した概要を生成するモデルのパフォーマンスをトレーニングおよび評価するための強力な基盤を提供します。
モデルのパフォーマンスは ROUGE メトリクスを使用して評価され、人間が書いた要約と厳密に一致する要約を生成する能力が強調されました。 BART モデルと T5 モデルは両方とも、高品質の要約要約の実現に重点を置いて、ビッグ特許データセットを使用して微調整されました。
| メトリック | 価値 |
|---|---|
| 評価損失(Eval Loss) | 1.9244 |
| ルージュ-1 | 0.5007 |
| ルージュ-2 | 0.2704 |
| ルージュL | 0.3627 |
| ルージュ・ルサム | 0.3636 |
| 平均世代長 (Gen Len) | 122.1489 |
| 実行時間 (秒) | 1459.3826 |
| 1 秒あたりのサンプル数 | 1.312 |
| 1 秒あたりのステップ数 | 0.164 |
| メトリック | 価値 |
|---|---|
| 評価損失(Eval Loss) | 1.9984 |
| ルージュ-1 | 0.503 |
| ルージュ-2 | 0.286 |
| ルージュL | 0.3813 |
| ルージュ・ルサム | 0.3813 |
| 平均世代長 (Gen Len) | 151.918 |
| 実行時間 (秒) | 714.4344 |
| 1 秒あたりのサンプル数 | 2.679 |
| 1 秒あたりのステップ数 | 0.336 |


