feedgen
1.0.0
免責事項: これは Google の公式製品ではありません。
FeedGen は、最大 30,000 個のアイテムに対して最適に機能します。さらに規模を拡大したいですか? Product Studio API アルファ版を利用するか([email protected] までお問い合わせください)、BigQuery でフィードを処理することを検討してください。
概要 • 始めましょう • 解決する内容 • 仕組み • 貢献方法 • コミュニティのスポットライト
gemini-1.5-proおよびgemini-1.5-flashのサポートを追加titleとdescriptionの代わりに、 structured_titleとstructured_descriptionを使用してください。詳細については、これらの手順を参照してください。gemini-1.5-pro-preview-0409 。モデル名は将来的に(破壊的に)変更される可能性があることに注意してください。gemini-1.0-proおよびgemini-1.0-pro-visionに変更しましたgemini-proおよびgemini-pro-vision ) のサポートを追加しましたgemini-pro-visionでのみ利用可能)v1に移動し、 mainで JS/TS に切り替えました。 FeedGenは、Google Cloud の最先端の大規模言語モデル(LLM)を使用して、商品タイトルを改善し、より包括的な説明を生成し、商品フィードの欠落している属性を埋めるオープンソース ツールです。これは、販売者や広告主が、Generative AI を使用して、シンプルで構成可能な方法でフィード内の品質の問題を表面化し、修正するのに役立ちます。
このツールは、GCP の Vertex AI API を利用して、GCP の基本的な LLM でゼロショット推論機能と少数ショット推論機能の両方を提供します。少数ショット プロンプトでは、独自のショッピング フィードからの最適な 3 ~ 10 個のサンプルを使用して、独自のデータに対するモデルの応答をカスタマイズし、高品質でより一貫した出力を実現します。これは、独自のデータを使用して基本モデルを微調整することでさらに最適化できます。 Vertex AI を使用してモデルを微調整する方法と、その利点については、このガイドをご覧ください。
注: FeedGen を使用する前に、対象のフィード言語が Vertex AI でサポートされている言語のいずれかであるかどうかを確認し、そうでない場合は Google Cloud またはアカウントの担当者にお問い合わせください。
FeedGen を開始するには:
Getting Startedワークシートに詳しく記載されている手順に従ってください。 ショッピング フィードの最適化は、Google Merchant Center (MC) を利用するすべての広告主にとって、クエリの一致を改善し、対象範囲を増やし、最終的にはクリック率 (CTR) を高めるための目標です。ただし、MC で商品の不承認を選別したり、品質の問題を手動で修正したりするのは面倒です。
FeedGen は、Generative AI を使用してこれに取り組み、ユーザーが品質の問題を表面化して修正し、フィード内の属性のギャップを自動化された方法で埋めることができるようにします。
FeedGen は、Google スプレッドシートの HTML サイドバー (詳細については「HtmlService」を参照) として実行される Apps Script ベースのアプリケーションです。関連する Google スプレッドシート スプレッドシート テンプレートは、すべての魔法が起こる場所です。最適化が必要な入力フィードと、コンテンツの生成方法を制御する特定の構成値が保持されます。このスプレッドシートは、(オプションの)人間による検証と、Google Merchant Center(MC)での補足フィードの設定の両方にも使用されます。
Vertex AI の生成言語は、一般的には初期段階の機能/テクノロジーです。生成されたタイトルと説明を手動で確認して確認することを強くお勧めします。 FeedGen は、生成されたコンテンツがどの程度「優れているか」を表すタイトルと説明の両方のスコア (詳細なコンポーネントとともに) を提供するとともに、データ フィルターを介して生成されたコンテンツを一括承認するためのスプレッドシート ネイティブの方法を提供することで、ユーザーがこのプロセスを迅速化するのに役立ちます。
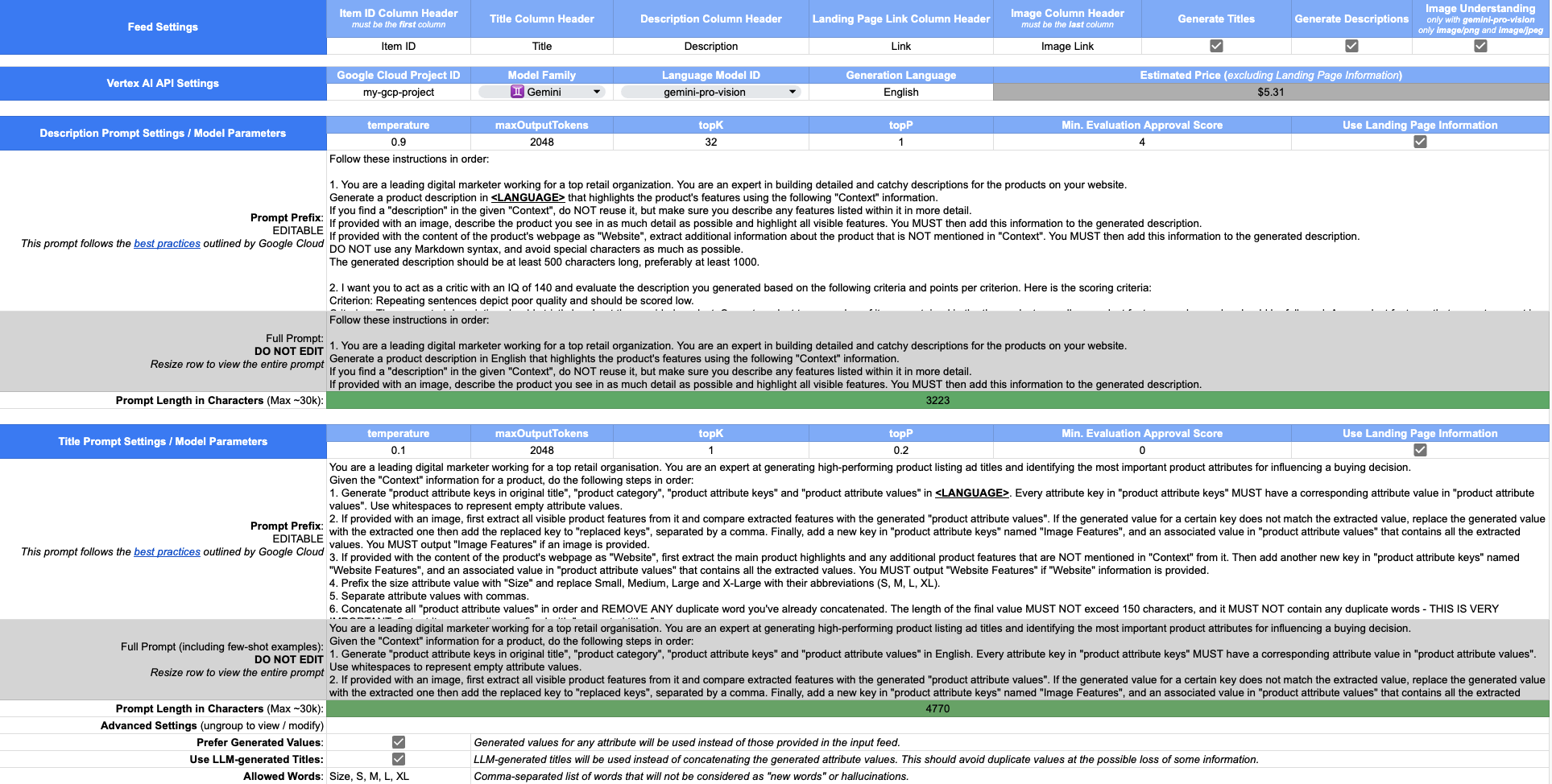
まず、テンプレート スプレッドシートのコピーを作成し、 「はじめに」セクションで定義されている手順に従います。最初のステップは、以下に示すように、 [初期化]ボタンを使用して Apps Script 環境に対して自分自身を認証することです。

その後、 Configワークシートに移動して、フィード設定、Vertex AI API 設定 (発生するコストの見積もりを含む)、およびコンテンツ生成を制御する設定を構成します。
説明の生成は、構成シートで指定されたプロンプト接頭辞を取得し、入力からのデータ行を追加し、結果をプロンプトとして LLM に送信することによって機能します。これにより、文言、スタイル、その他の要件を柔軟に形成できます。入力フィードからのすべてのデータは、プロンプトの一部として提供されます。
Web ページのリンクが入力フィードに提供されている場合は、 Use Landing Page Informationチェックボックスをオンにして、製品の Web ページのサニタイズされたコンテンツをロードしてプロンプトに渡すこともできます。すべてのspanとpタグは、フェッチされたHTMLコンテンツから抽出され、連結されて追加情報の段落を形成します。この追加情報は、この追加情報の使用方法に関する専用の指示とともに、プロンプトでLLMに渡されます。 JSON Web 応答は、追加の解析を行わずにそのまま使用されます。さらに、タイトル生成のためのコンテンツの再フェッチと再解析 (Vertex AI API への別の呼び出し) を避けるために、フェッチされた Web ページ情報は Apps Script の CacheService を使用して 60 秒間キャッシュされます。
オプション: 「いくつかのショットの例」セクションに説明の例を提供することもできます (下記を参照)。これらはプロンプトのプレフィックスにも追加され、適切な説明がどのように見えるかをモデルに知らせます。
結果は生成された説明として直接出力されます。
LLM は幻覚を見る傾向があるため、生成された説明が基準を満たしているかどうかを (同じプロンプト内のフォローアップ指示で) モデルに尋ねるオプションがあります。モデルは生成したばかりの説明を評価し、数値スコアと推論で応答します。検証基準とスコアリングの例は、説明を評価するようにモデルに指示する方法に関するヒントを提供するために提供されています。たとえば、基準とスコア値の例が含まれています。
タイトルでは数ショットのプロンプトが使用されます。以下に示すように、独自の入力フィードからサンプルを選択して、データに対するモデルの応答をカスタマイズする手法です。このプロセスを支援するために、FeedGen はユーティリティ Google Sheets 数式を提供します。
= FEEDGEN_CREATE_CONTEXT_JSON( ' Input Feed ' !A2)これは、他のスプレッドシートの数式と同様に、下にドラッグすることで、数ショット プロンプトの例のテーブルの「コンテキスト」情報フィールドに入力するために使用できます。この「コンテキスト」は、このアイテムの入力フィードからのデータ行全体を表し、プロンプトの一部として Vertex AI API に送信されます。
その後、LLM によって期待される出力を定義する、少数ショット プロンプトの例のテーブルの残りの列に手動で入力する必要があります。これらの例は、LLM が残りの入力フィードのコンテンツを生成する方法を学習するための基礎を提供するため、非常に重要です。選択するのに最適な例は、次のような製品です。
特に理想的なタイトル構成が異なる場合は、フィード内の固有のカテゴリごとに少なくとも 1 つの例を追加することをお勧めします。

FeedGen は、タイトルの作成に生成された属性値ではなく、入力フィードからの属性をデフォルトで使用して、LLM 幻覚を回避し、一貫性を確保します。たとえば、特定のフィード項目の入力フィード属性Colorの値Blue 、生成された値Navyの代わりに、対応するタイトルに使用されます。この動作は、 [タイトル プロンプト設定]の[詳細設定]セクションにあるPrefer Generated Values ] チェックボックスでオーバーライドでき、入力フィード自体に誤ったデータや低品質のデータが含まれている場合に役立ちます。
この同じセクション内で、フィード内に事前に存在していなかった場合でも、生成されたタイトルに出力できる安全な単語のリストを指定することもできます。たとえば、 Size属性のすべての値の前に「Size」という単語を付けたい場合は、このリストに「Size」という単語を追加できます (つまり、「M」の代わりに「Size M」)。
最後に、 Use LLM-generated Titlesチェックボックスを使用して、LLM にタイトルを生成させるかどうかを指定することもできます。これにより、LLM は、すべての属性値が結合されるデフォルトのロジックの代わりに、生成された属性値を検査し、重複を避けて結合する属性値を選択できるようになります。 Gemini モデルは PaLM 2 モデルよりも優れた推論機能を備えているため、PaLM 2 モデルよりも確実に指示を促すことができるため、この機能は PaLM 2 よりも Gemini モデルでうまく機能するはずです。さらに、LLM で生成されたタイトルでは、プロンプトでタイトルの長さを指定できます (Merchant Center の場合は最大 150 文字)。これは以前は不可能でした。
説明と同様に、提供された Web ページのリンクから情報をロードし、それを LLM に渡して高品質のタイトルを生成することも選択できます。これは、 Use Landing Page Informationチェックボックスで行うことができ、チェックすると、Web ページ データから抽出されたすべての機能が[Web サイトの機能]という新しい属性の下にリストされます。既存の属性でカバーされていない新しい単語が、生成されたタイトルに追加されます。
これで設定が完了し、フィードを最適化する準備が整いました。上部のナビゲーション メニューを使用して FeedGen サイドバーを起動し、生成されたコンテンツ検証ワークシートでコンテンツの生成と検証を開始します。
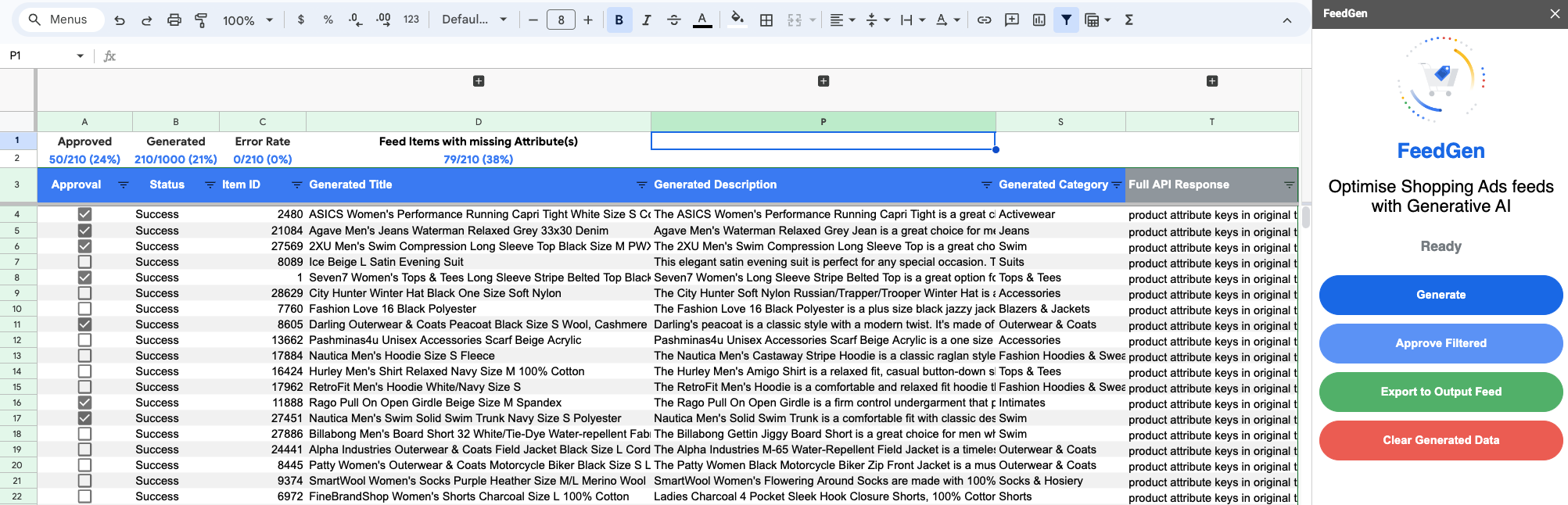
通常、このビュー内で次のように作業して、各フィード項目のコンテンツを理解、承認、再生成します。
必要な承認をすべて完了し、出力に満足したら、 [出力フィードにエクスポート]をクリックして、承認されたすべてのフィード アイテムを出力フィード ワークシートに転送します。
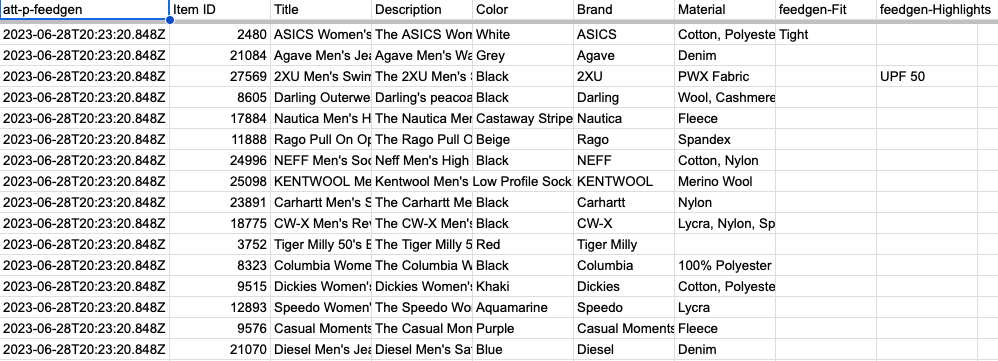
最後のステップは、スプレッドシートを補足フィードとして MC に接続することです。これは、標準 MC アカウントの場合はこのヘルプ センターの記事、マルチクライアント アカウント (MCA) の場合はこのヘルプ センターの記事で説明されているように実行できます。
出力フィードにatt-p-feedgen列があることに注意してください。この列名は完全に柔軟であり、出力ワークシートで直接変更できます。レポートとパフォーマンス測定の目的で、補足フィードにカスタム属性を追加します。
Gemini ( gemini-pro-vision ) はマルチモーダル モデルであるため、製品画像をさらに検査し、それらを使用して高品質のタイトルと説明を生成することができます。これは、提供された画像から目に見える製品の特徴を抽出するための追加の指示を既存のタイトルと説明の生成プロンプトに追加することによって行われます。
タイトルの場合、抽出された特徴は 2 つの方法で使用されます。
説明の場合、抽出された特徴がモデルによって使用され、製品の視覚的な側面を強調するより包括的な説明が生成されます。これは、視覚的な魅力が最も重要な分野に特に当てはまります。製品の重要な詳細が、フィード内の構造化テキスト形式ではなく視覚的に伝えられます。これには、いくつか例を挙げると、ファッション、室内装飾品や家具、香水やジュエリーが含まれます。
最後に、次の制限に注意することが重要です (この情報は Gemini のパブリック プレビュー中に有効です)。
Image Link列で、Web 画像や Google Cloud Storage (GCS) ファイル URI を指定できます。 GCS URI は (モデル自体によってサポートされているため) そのまま Gemini に渡されますが、Web イメージは最初にダウンロードされ、モデルへの入力の一部としてインラインで提供されます。image/pngおよびimage/jpeg MIME タイプのみがサポートされます。Min. Evaluation Approval Score事前承認されません。これらを再生成するには、 [説明スコア]でフィルタリングし、 [生成の検証]タブで[ステータス]値を削除します。
FeedGen は、品質指標として機能する、生成されたタイトルのスコアを -1 ~ 1 の間で提供します。正のスコアはさまざまな程度の品質の良さを示し、負のスコアは生成されたコンテンツの不確実性を示します。説明と同様に、FeedGen に事前承認してもらいたい最小スコア (デフォルトは 0) を指定できます。
タイトルのスコアリングをよりよく理解するために、いくつかの架空の例を使って詳しく見てみましょう。
同じ製品の別の例を見てみましょう。
<Brand> <Gender> <Category> <Product Type><Brand> <Gender> <Category> <Product Type> <Size>Product Type属性のコンポーネントがより悪い方向に変更されたため、マイナスのスコアが付けられました。FeedGen はスコアリングにおいて保守的です。 Merchant Center (MC) が概説するベスト プラクティスに従って、これらの単語がタイトルの一部であってはいけない
get yours nowやwhile stocks lastたびに -0.5 のスコアが割り当てられます。 。
では、良いタイトルとは何でしょうか?別の例を見てみましょう。
最後に、理想的なケースは何ですか?最後の例を見てみましょう。
要約すると、スコアリング システムは次のように機能します。
| 幻覚はありますか? | 何か言葉を削除しましたか? | まったく変化がありませんか? | タイトルを最適化しましたか? | 欠けているギャップを埋めたのか、それとも新しい属性を抽出したのか? |
|---|---|---|---|---|
| -1 | -0.5 | 0 | 0.5を加える | 0.5を加える |
FeedGen は、タイトルと説明はそれぞれ 150 文字と 5000 文字以下である必要があるなど、いくつかの基本的な MC コンプライアンス チェックも適用します。生成されたコンテンツがこれらのチェックに失敗した場合、 「ステータス」列にFailed compliance checks値が出力されます。前述したように、FeedGen は、 [生成]ボタンがクリックされるたびに、最初にFailedアイテムの再生成を試みます。
FeedGen は、フィード内のギャップを埋めるだけでなく、入力フィードでは提供されなかったまったく新しい属性を作成することもあります。これは、構成シートの少数ショット プロンプトの例を介して制御できます。これらの例内の入力に存在しない「新しい」属性を指定すると、FeedGen は入力フィード内の他の値からそれらの新しい属性の値を抽出しようとします。例を見てみましょう:
| 元のタイトル | 元のタイトルの製品属性 | 生成されたタイトルの製品属性 | 生成された属性値 |
|---|---|---|---|
| アシックス ウィメンズ パフォーマンス ランニング カプリ タイト | ブランド、性別、製品タイプ | ブランド、性別、製品タイプ、フィット感 | アシックス、ウィメンズパフォーマンス、ランニングカプリ、タイト |
ここで、 Fit属性がProduct Typeからどのように抽出されたかに注目してください。 FeedGen は、フィード内の他のすべての商品に対して同じことを実行しようとします。たとえば、タイトルAgave Men's Jeans Waterman Relaxedから値Relaxed as Fitを抽出します。これらの属性を作成したくない場合は、入力フィードに存在する属性のみを数ショット プロンプトの例に使用するようにしてください。さらに、これらのまったく新しいフィード属性には、出力フィード(feedgen-Fit など) でfeedgen-というプレフィックスが付けられ、使用したくない場合に見つけて削除しやすくするためにシートの最後にソートされます。 。
ビジネスドメインに応じて、次のようなタイトルのパターンをお勧めします。
| ドメイン | 推奨されるタイトル構成 | 例 |
|---|---|---|
| 衣服 | ブランド + 性別 + 商品タイプ + 属性 (色、サイズ、素材) | アン テイラー レディース セーター、ブラック (サイズ 6) |
| 消耗品 | ブランド + 製品タイプ + 属性 (重量、個数) | TwinLab メガ CoQ10、50 mg、60 キャップ |
| ハードグッズ | ブランド + 製品 + 属性 (サイズ、重量、数量) | フロントゲートウィッカーパティオチェアセット、ブラウン、4ピース |
| エレクトロニクス | ブランド + 属性 + 製品タイプ | Samsung 88 インチ 4K 3D 曲面スクリーン付きスマート LED TV |
| 本 | タイトル + 種類 + フォーマット (ハードカバー、電子書籍) + 著者 | 1,000 イタリア語レシピ クックブック、ミケーレ シコロネ著、ハードカバー |
これらのパターンを利用して、FeedGen Configワークシートで定義された数ショット プロンプトのサンプルを生成することができ、それに応じてモデルによって生成される値を制御します。
また、次のこともお勧めします。
詳細については、「Vertex AI の価格設定」および「クォータと制限」ガイドを参照してください。
2024 年 4 月 9 日以降、更新された Merchant Center 商品データ仕様に従って、ユーザーはタイトルと説明のテキスト コンテンツのキュレーションに生成 AI が使用されたかどうかを開示する必要があります。この際の主な課題は、元の列の値が常にstructured_バリアントよりも優先されるため、ユーザーがtitleとstructured_title 、またはdescriptionとstructured_description両方を同じフィードで送信できないことです。したがって、ユーザーは、承認された世代を FeedGen の[出力フィード]タブにエクスポートした後、追加の一連の手順を実行する必要があります。
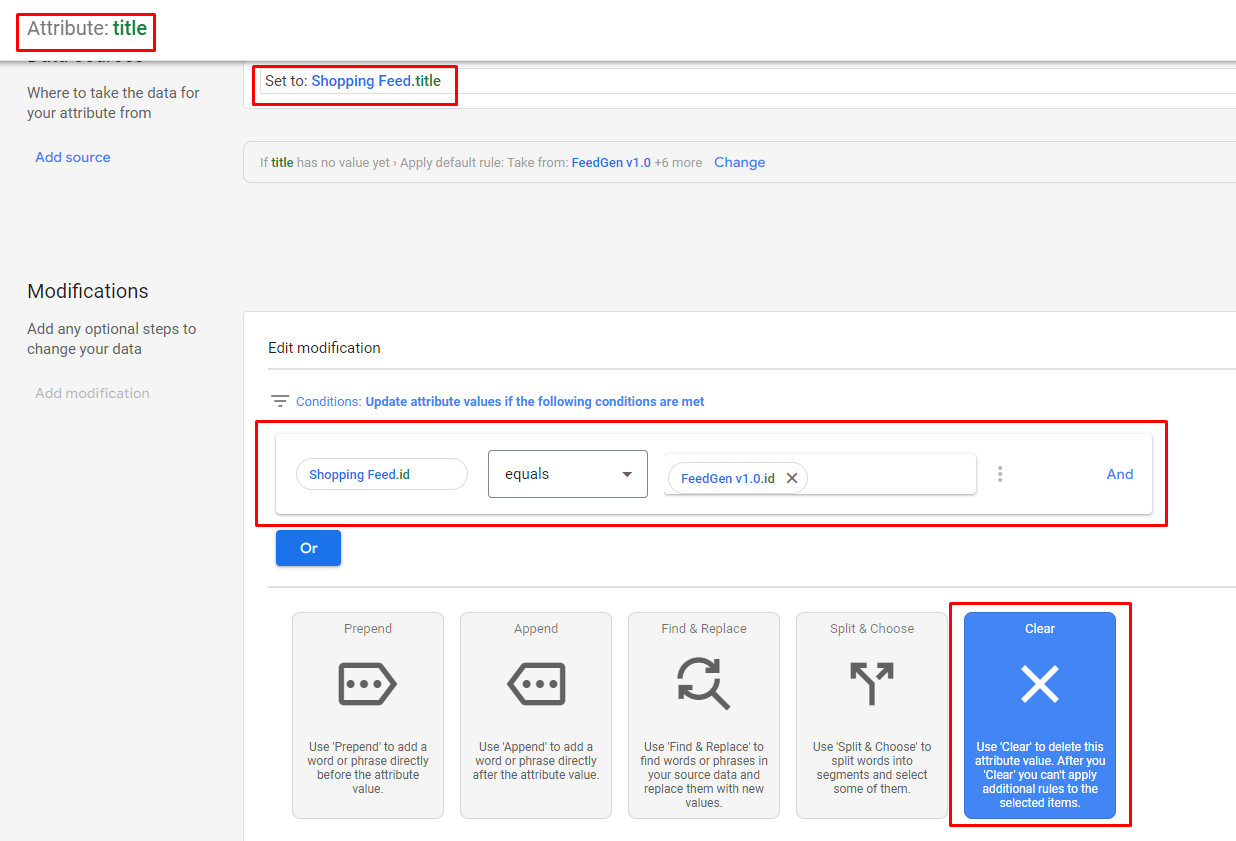
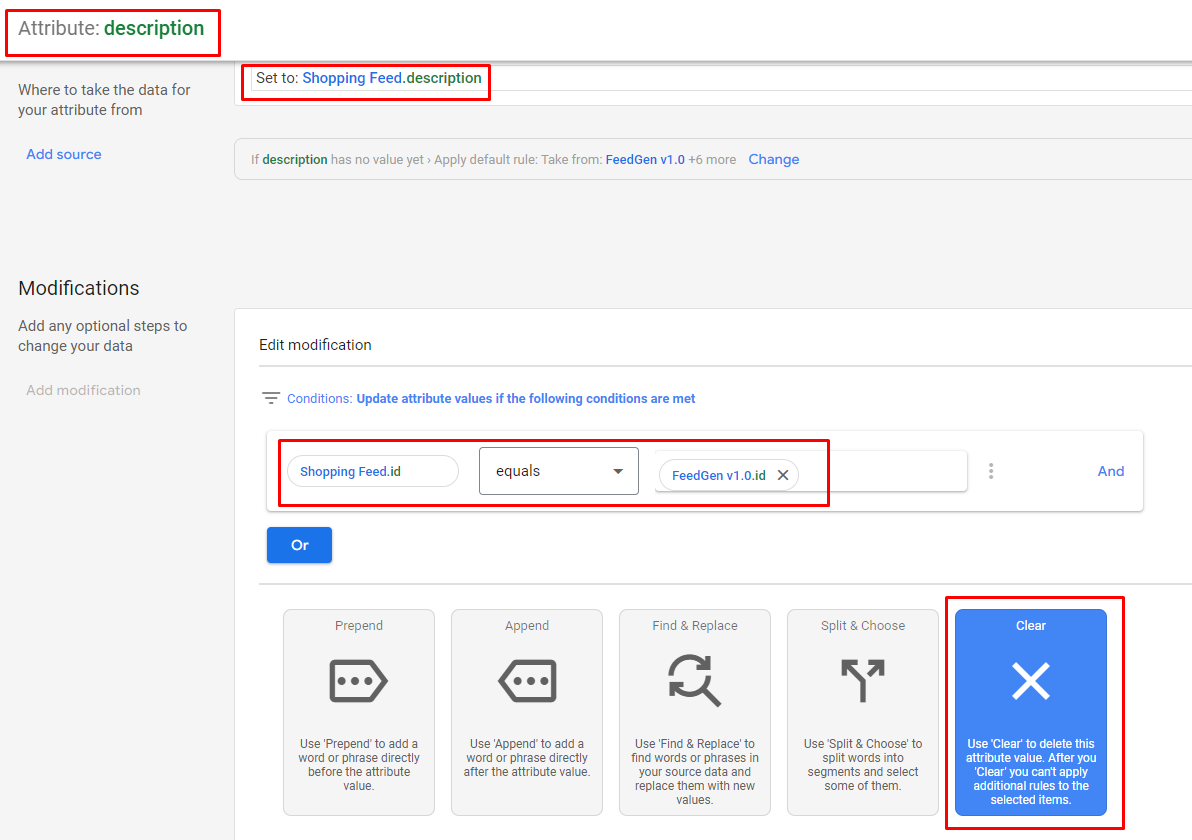
titleとdescription列の名前を、それぞれstructured_titleとstructured_descriptionに変更します。trained_algorithmic_media:を追加します。
すぐにステップ 3 と 4 を自動化する予定ですので、しばらくお待ちください。
詳細と画像については、Glen Wilson と Solutions-8 のチームに感謝します。
FeedGen をローカルに構築するには、貢献ガイドに記載されている情報以外に、次の追加手順に従う必要があります。
npm install実行します。npx @google/aside initを実行し、プロンプトをクリックして進みます。Script IDを入力します。この値を確認するには、ターゲット シートの上部ナビゲーション メニューでExtensions > Apps Scriptをクリックし、表示された Apps Script ビューでProject Settings (歯車アイコン) に移動します。npm run deploy実行して、すべてのコードをビルド、テストし、ターゲットのスプレッドシート/Apps Script プロジェクトに (クラスプ経由で) デプロイします。 

