bedrock agents infer models
1.0.0
このプロジェクトは、開発者が Amazon Bedrock エージェントを使用してさまざまな大規模言語モデル (LLM) にユースケースを拡張するためのベースラインとして機能します。目標は、Bedrock 上の複数のモデルを活用して、多様なシナリオに適応する連鎖応答を作成する可能性を示すことです。このアプリは、テキストベースの出力の生成に加えて、画像生成とテキストから画像へのモデルを使用した画像の作成と検査もサポートします。この拡張された機能によりアプリケーションの多用途性が向上し、より創造的で視覚的なユースケースに適したものになります。
Infrastructure-as-Code (IaC) アプローチを好む人のために、Amazon Bedrock エージェント、S3 バケット、Lambda 関数などのコアコンポーネントを設定する AWS CloudFormation テンプレートも提供します。 AWS CloudFormation 経由でこのプロジェクトをデプロイする場合は、こちらのワークショップ ガイドを参照してください。
あるいは、この README では、AWS コンソールから Amazon Bedrock エージェントを手動でセットアップおよび構成するためのステップバイステップのプロセスを説明しており、最新モデルを柔軟に試して、Bedrock エージェントの可能性を最大限に引き出すことができます。
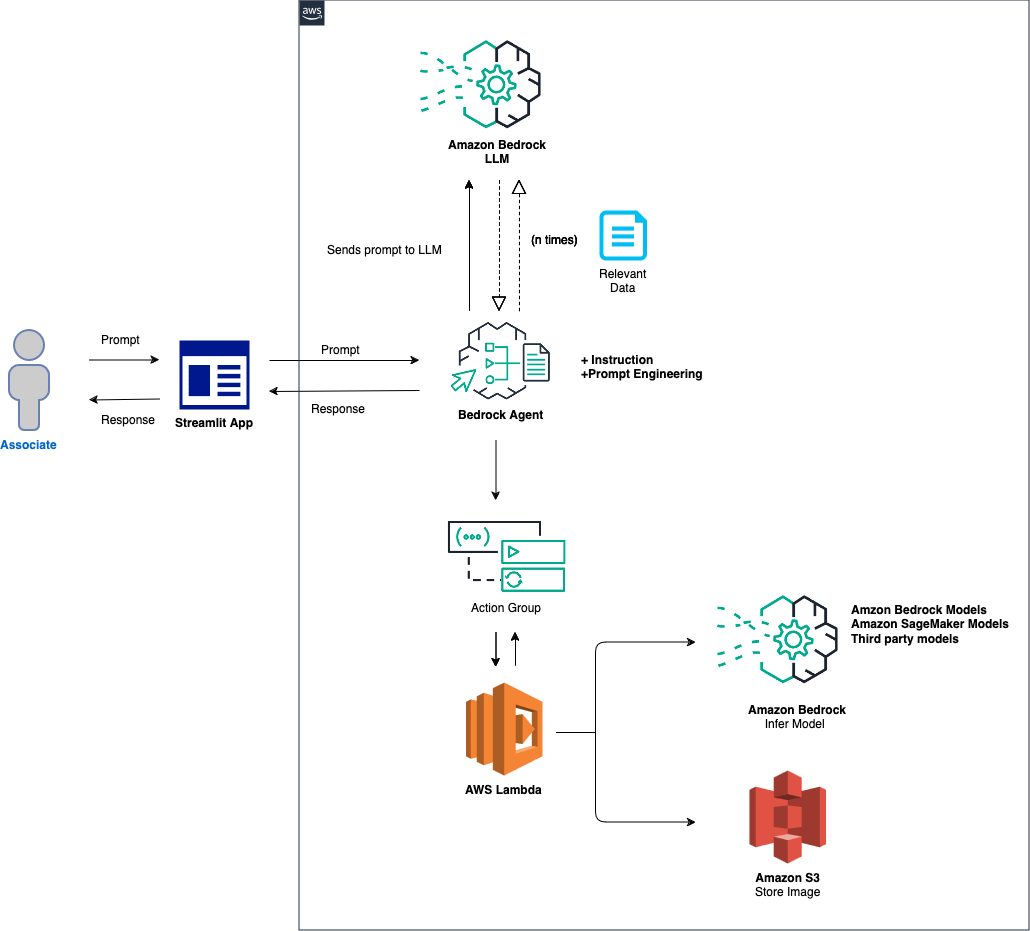
ソリューションの概要は次のとおりです。
エージェントと環境のセットアップ: このソリューションは、Amazon Bedrock エージェント、AWS Lambda 関数、および Amazon S3 バケットを構成することから始まります。このステップでは、モデルの対話とデータ処理の基礎を確立し、フロントエンド アプリケーションからのプロンプトを受信して処理するシステムを準備します。プロンプト処理とモデル推論: フロントエンド アプリケーションからプロンプトを受信すると、Bedrock エージェントはそのプロンプトを評価し、指定されたモデル ID とともにアクション グループ メカニズムを使用して Lambda 関数にディスパッチします。このステップでは、アクション グループの API スキーマを利用して正確なパラメーターを処理し、入力プロンプトに基づいた効果的なモデル推論を促進します。データ処理と応答生成: 画像からテキストへ、またはテキストから画像への変換を伴うタスクの場合、Lambda 関数は S3 バケットと対話して、画像に対して必要な読み取りまたは書き込み操作を実行します。このステップにより、マルチメディア コンテンツの動的な処理が保証され、最終的に最初のプロンプトによって指示された応答または変換が生成されます。
次のセクションでは、次の手順について説明します。
AWS SAM (サーバーレス アプリケーション モデル) は、AWS でサーバーレス アプリケーションを構築するのに役立つオープンソース フレームワークです。 AWS Lambda、Amazon API Gateway、Amazon DynamoDB などのサーバーレス リソースのデプロイ、管理、監視が簡素化されます。ここでは、AWS SAM を設定して使用する方法に関する包括的なガイドを示します。
このフレームワークは、クラウド インフラストラクチャの複雑さを抽象化することで、サーバーレス アプリケーションの作成、展開、管理のプロセスを簡素化します。構成ファイルと一連のコマンドを使用して、サーバーレス リソースを定義および管理するための統合された方法を提供します。
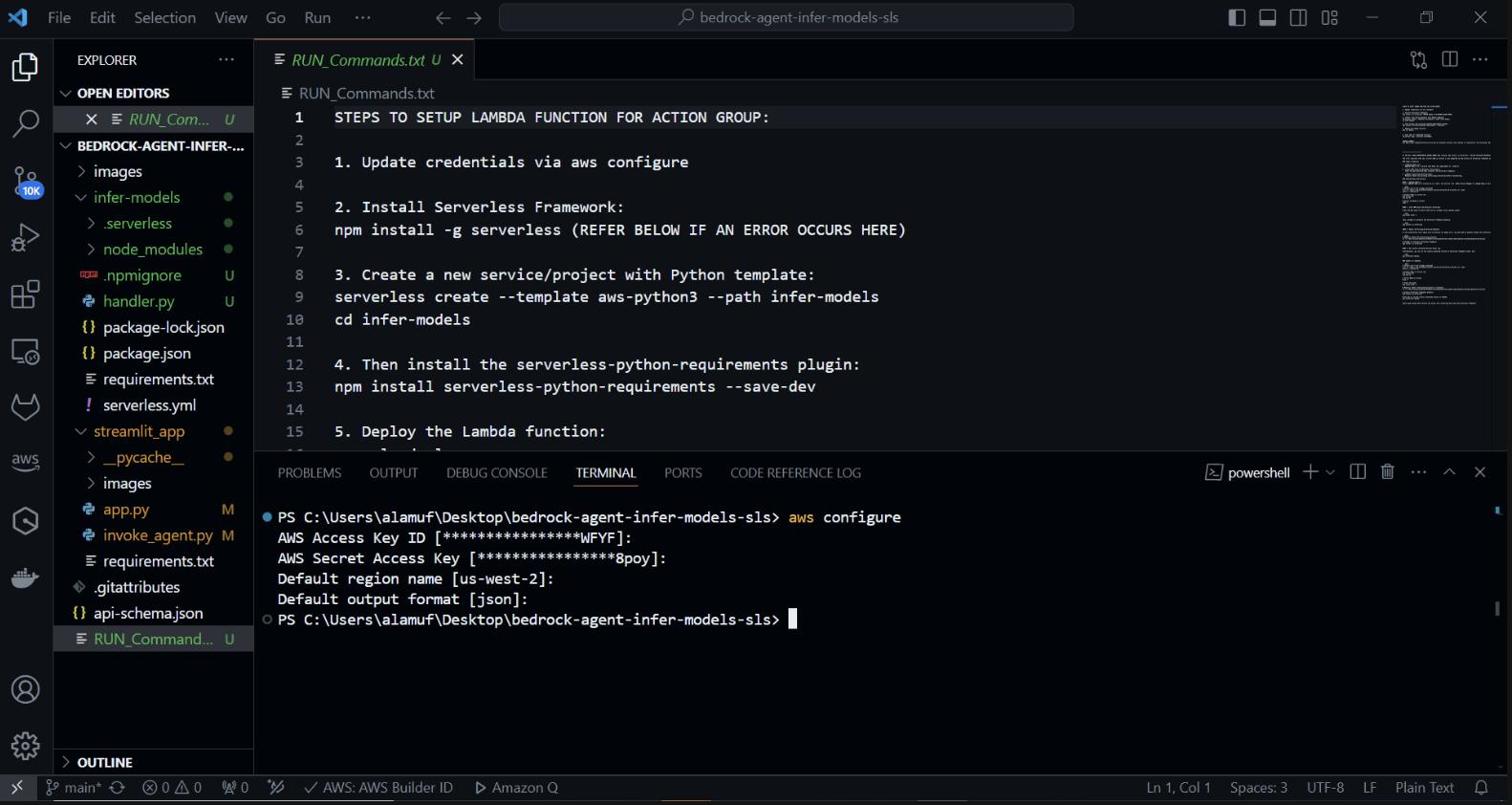
Python テンプレートを使用して新しいサーバーレス プロジェクトを作成します。ターミナルで、 cd infer-models を実行してから、 serverless を実行します。 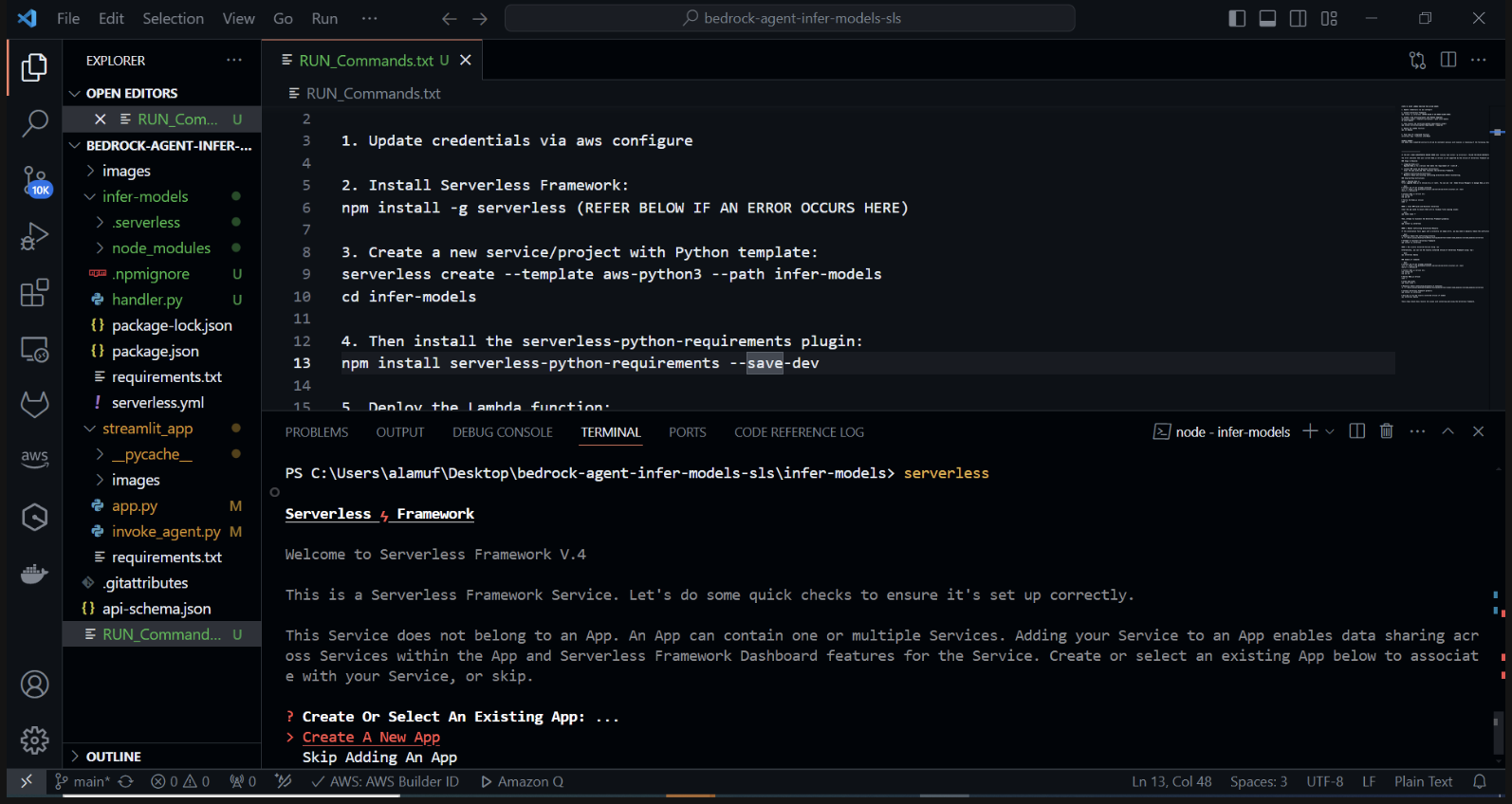
これにより、サーバーレス フレームワークの対話型プロジェクト作成プロセスが開始されます。いくつかのオプションが表示されます。 [新しいサーバーレス アプリの作成] を選択します。 「aws-python3」テンプレートを選択し、プロジェクトの名前として「infer-models」を指定します。
これにより、基本的なサーバーレス プロジェクト構造と Python テンプレートを含むinfer-modelsという新しいディレクトリが作成されます。
ログイン/登録を求められる場合もあります。 「ログイン/登録」オプションを選択します。これにより、ブラウザ ウィンドウが開き、新しいアカウントを作成するか、すでにアカウントをお持ちの場合はログインできます。ログインするかアカウントを作成した後、無料で使用できる「フレームワーク オープンソース」オプションを選択します。
スタックのデプロイに失敗した場合は、 serverless.yml ファイルの 2 行目をコメントアウトしてください。
サーバーレス コマンドを実行し、プロンプトに従うと、プロジェクト名 (例: infer-models) の新しいディレクトリが作成され、サーバーレス プロジェクトのボイラープレート構造と構成ファイルが含まれます。
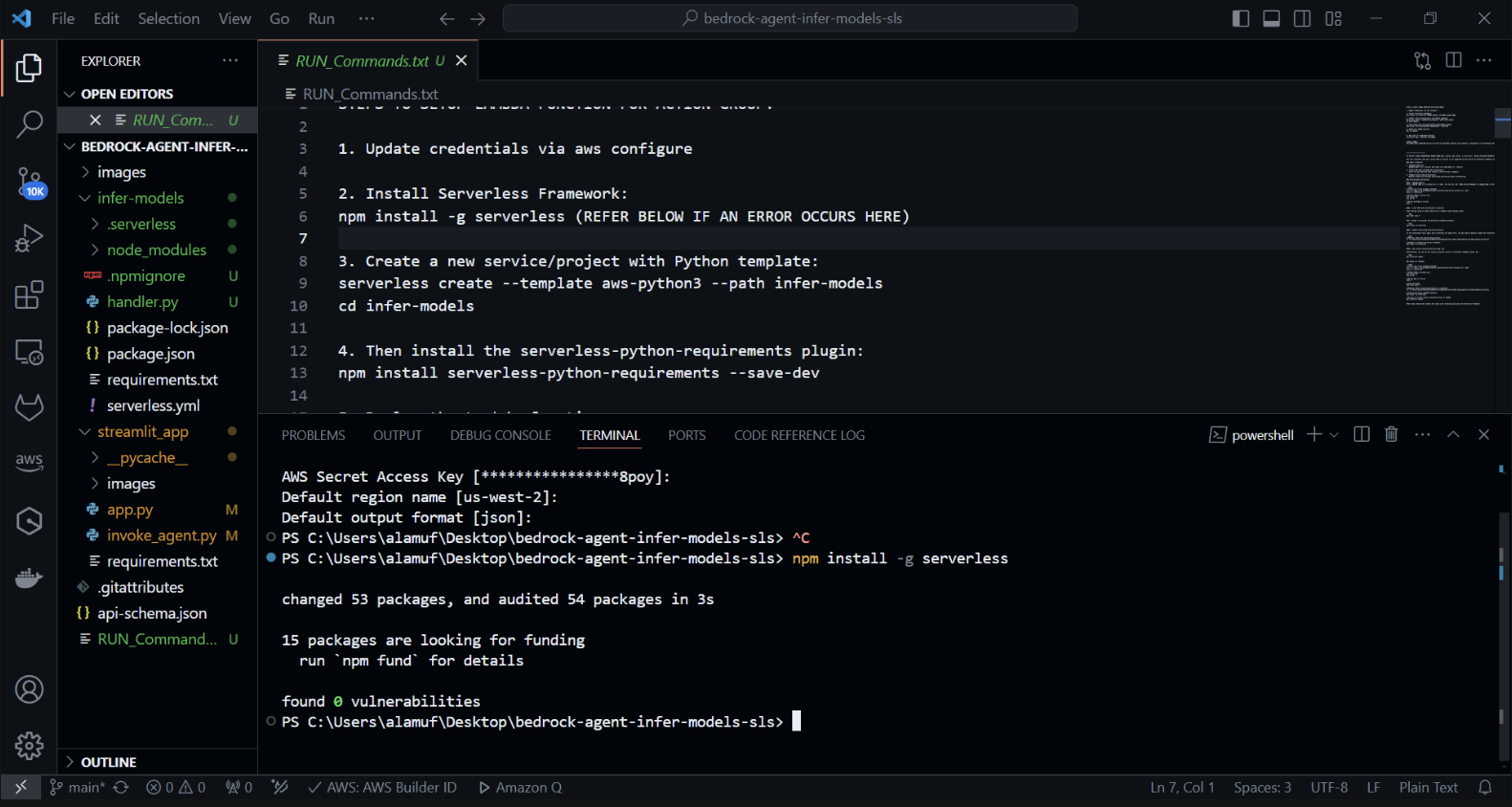
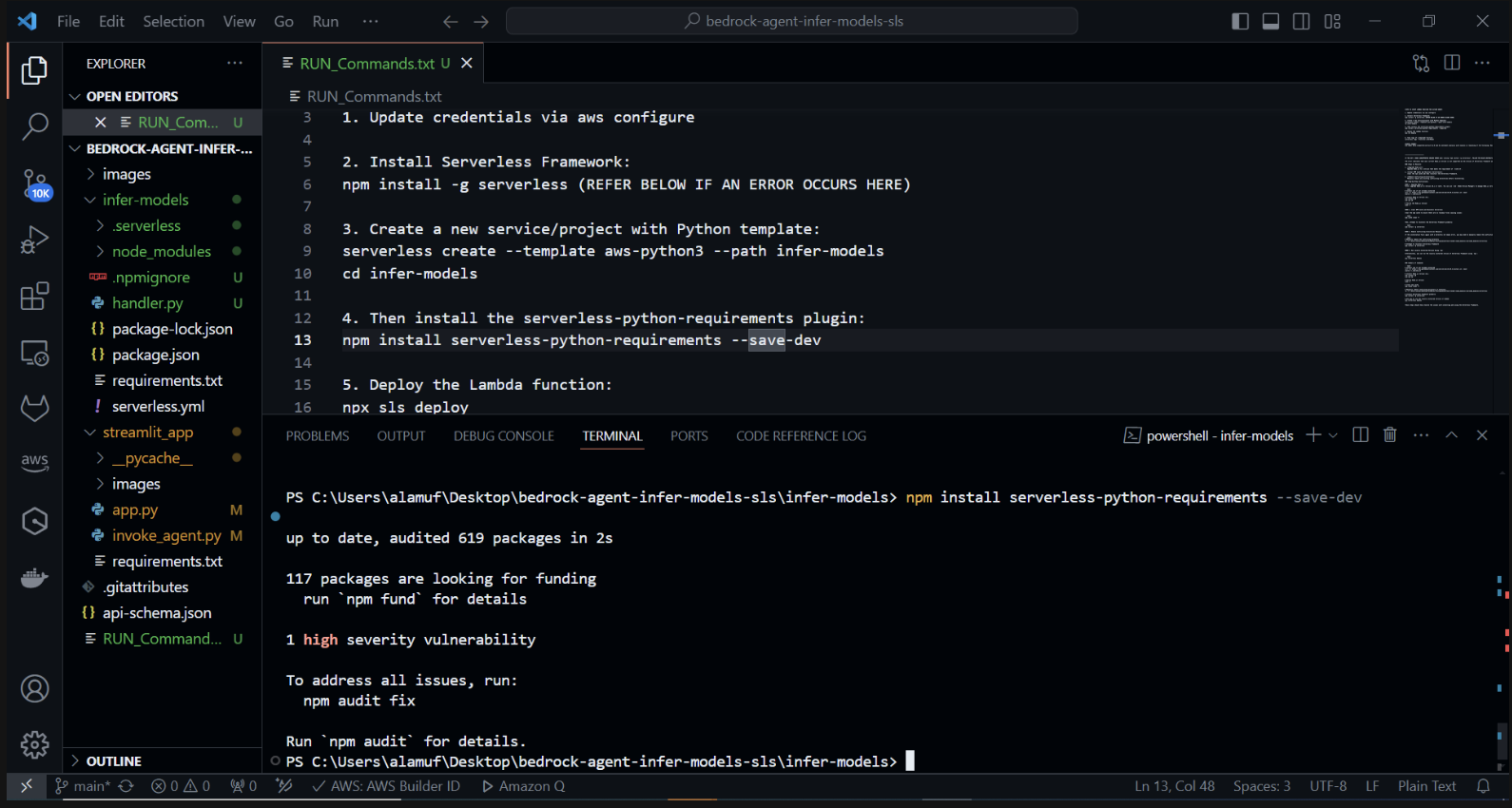
次に、serverless-python-requirements プラグインをインストールします。serverless-python-requirements プラグインは、サーバーレス プロジェクトの Python 依存関係を管理するのに役立ちます。以下を実行してインストールします。
npm install サーバーレス-Python-requirements —save-dev
3.) npx sls deploy
(上記のコマンドを実行する前に、Docker エンジンをインストールして実行する必要があります。詳細については、ここを参照してください。)
(これにより、AWS Lambda 関数がパッケージ化され、デプロイされます) 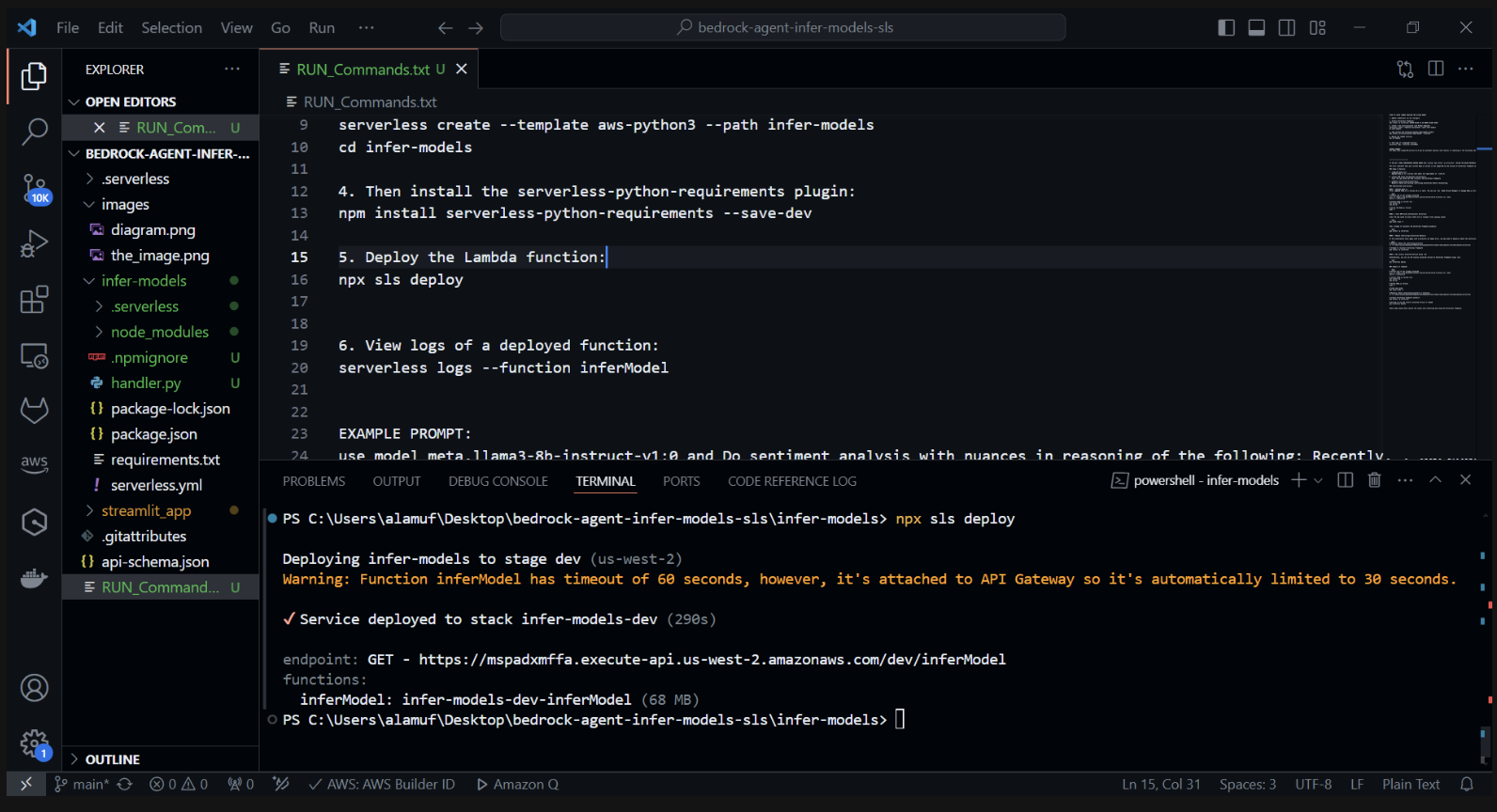
AWS コンソールで CloudFormation 内のデプロイメントを検査する
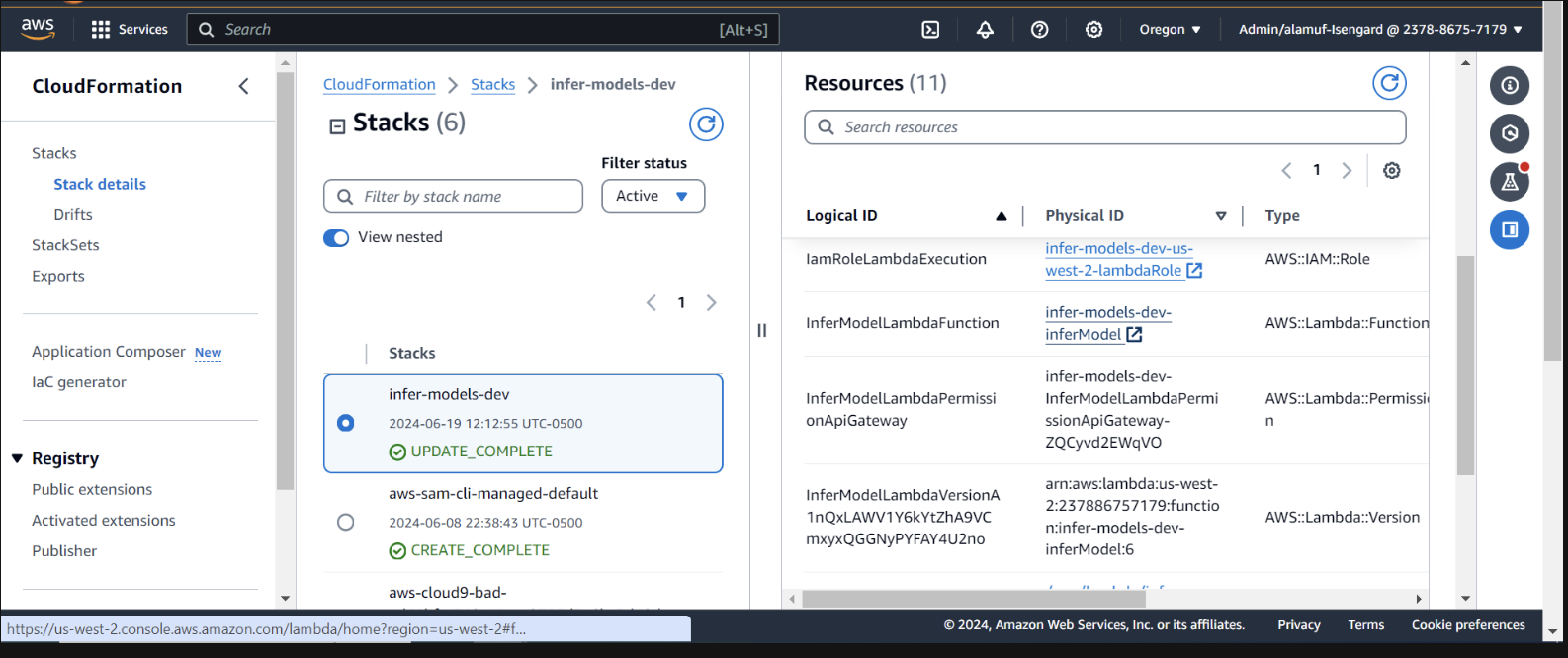
ラムダ関数を呼び出すための許可を Bedrock Agent に提供する必要があります。 lambda 関数を開き、下にスクロールして[構成]タブを選択します。左側で[アクセス許可]を選択します。 「リソースベースのポリシー ステートメント」まで下にスクロールし、「アクセス許可の追加」を選択します。
ポリシーステートメントの中央にあるAWS サービスを選択します。サービスとして「Other」を選択し、StatementID として「allow-agent」を入力します。プリンシパルには、 bedrock.amazonaws.comを入力します。
arn:aws:bedrock:us-west-2:{aws-account-id}:agent/*と入力します。 AWS では、許可されたエージェントのみがこの Lambda 関数を呼び出せるように、最小限の権限を推奨していることに注意してください。 ARN の末尾にある * により、アカウント内のエージェントにこの Lambda を呼び出すためのアクセスが許可されます。理想的には、実稼働環境ではこれを使用しません。最後に、アクションとしてlambda:InvokeFunction を選択し、保存します。 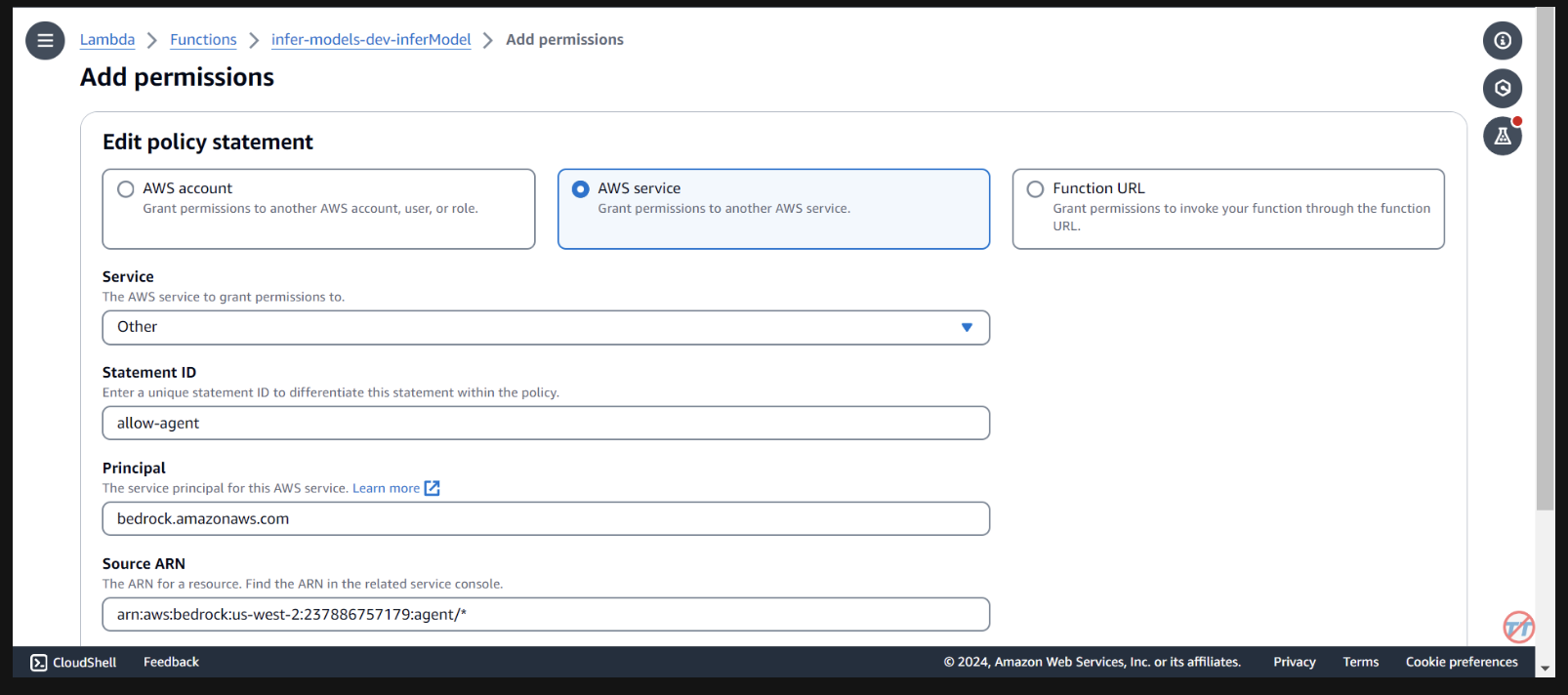
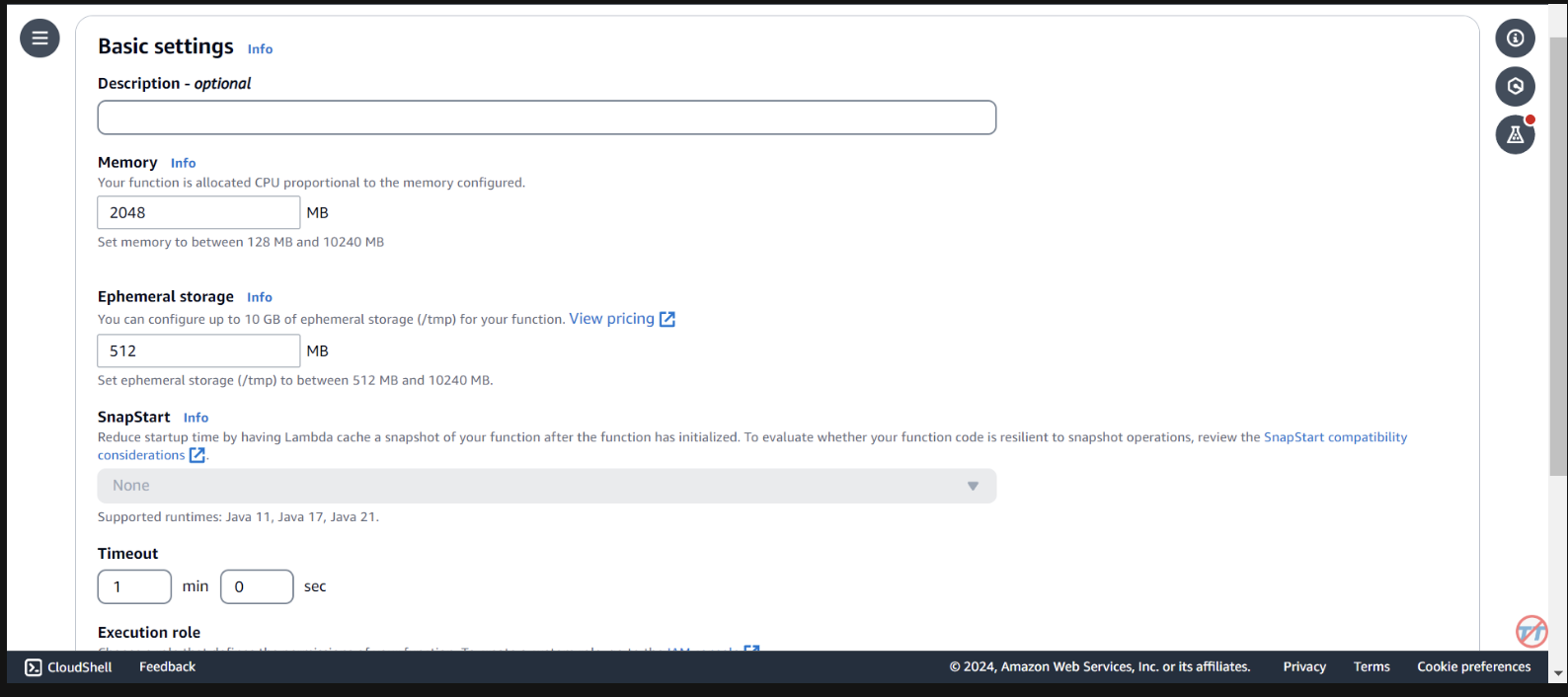
推論を容易にするために、Lambda 関数の CPU/メモリを増やします。また、関数が呼び出しを完了するのに十分な時間を確保できるように、タイムアウトを増やします。左側で「一般構成」を選択し、右側で「編集」を選択します。
メモリを2048 MBに変更し、タイムアウトを1 分に変更します。下にスクロールして、「保存」を選択します。
Agents選択します。 multi-model-agentなどのエージェント名を指定して、エージェントを作成します。 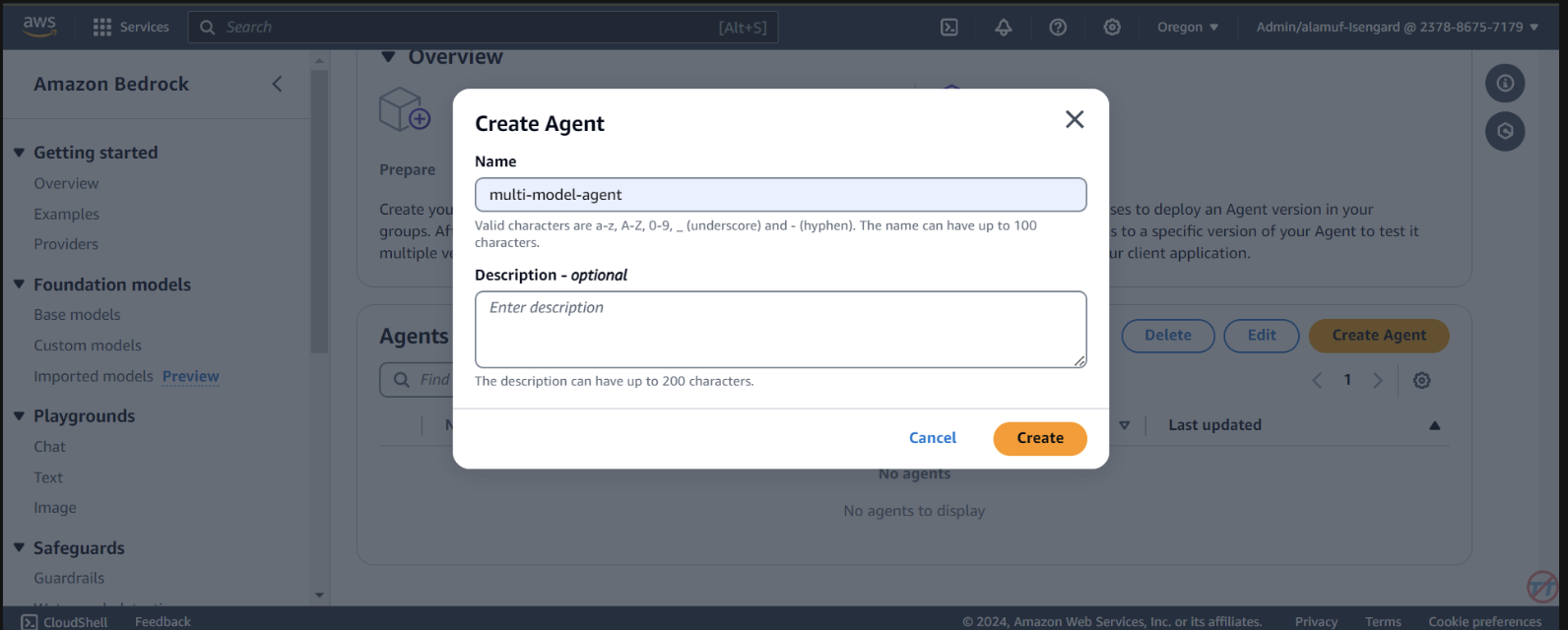
You are a research agent that interacts with various large language models. You pass the model ID and prompt from requests to large language models to create and store images. Then, the LLM will return a presigned URL to the image similar to the URL example provided. You also call LLMS for text and code generation, summarization, problem solving, text-to-sql, response comparisons and ratings. Remeber. you use other large language models for inference. Do not decide when to provide your own response, unless asked.
その後、次のステップに進む前に、必ず一番上までスクロールして[保存]ボタンを選択してください。
次に、アクショングループを追加します。 Action groupsまで下にスクロールし、 [追加]を選択します。アクション グループcall-modelを呼び出します。
[アクション グループ タイプ] で、 [API スキーマを使用して定義]を選択します。
次のセクションでは、既存の Lambda 関数infer-models-dev-inferModel を選択します。
API スキーマについては、 Define with in-line OpenAPI schema editorを選択します。以下のスキーマをコピーしてインライン OpenAPI スキーマエディターに貼り付け、 [追加]を選択します。 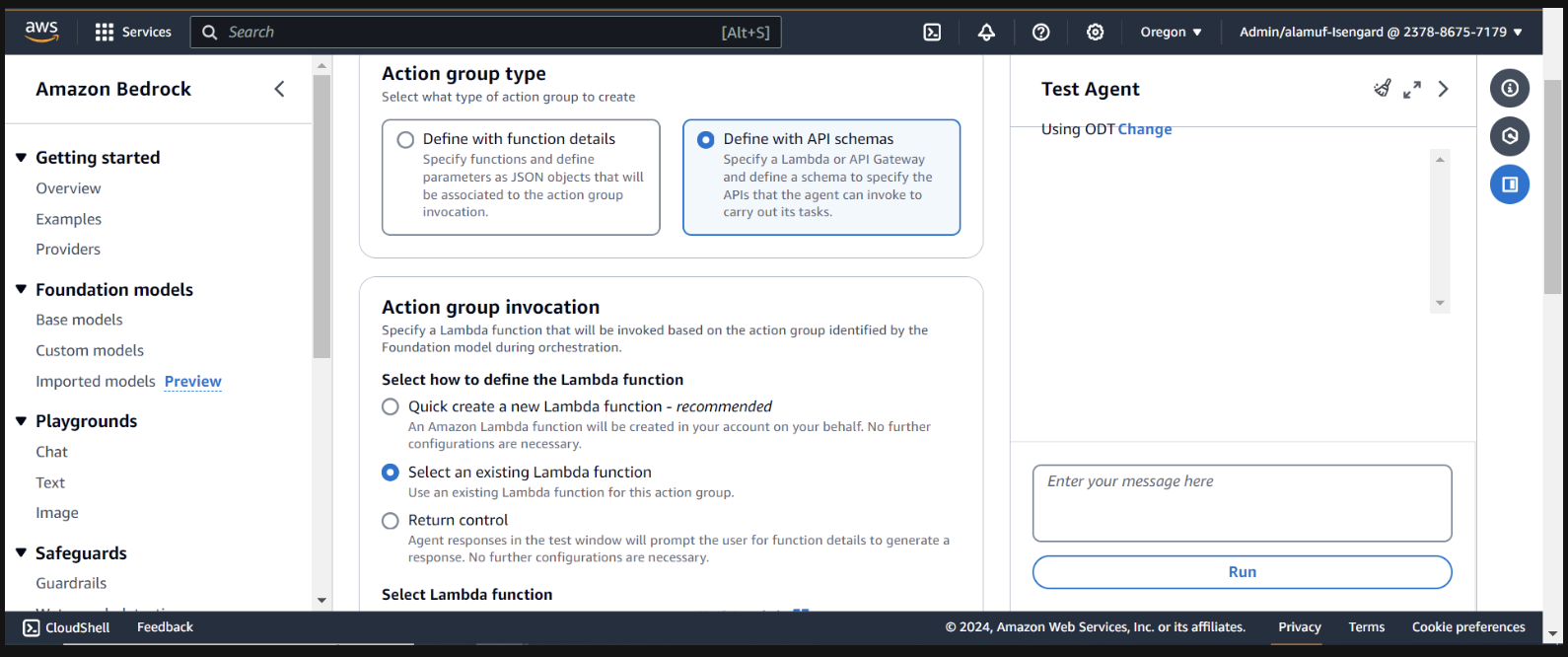
(This API schema is needed so that the bedrock agent knows the format structure and parameters required for the action group to interact with the Lambda function.)
{
"openapi": "3.0.0",
"info": {
"title": "Model Inference API",
"description": "API for inferring a model with a prompt, and model ID.",
"version": "1.0.0"
},
"paths": {
"/callModel": {
"post": {
"description": "Call a model with a prompt, model ID, and an optional image",
"parameters": [
{
"name": "modelId",
"in": "query",
"description": "The ID of the model to call",
"required": true,
"schema": {
"type": "string"
}
},
{
"name": "prompt",
"in": "query",
"description": "The prompt to provide to the model",
"required": true,
"schema": {
"type": "string"
}
}
],
"requestBody": {
"required": true,
"content": {
"multipart/form-data": {
"schema": {
"type": "object",
"properties": {
"modelId": {
"type": "string",
"description": "The ID of the model to call"
},
"prompt": {
"type": "string",
"description": "The prompt to provide to the model"
},
"image": {
"type": "string",
"format": "binary",
"description": "An optional image to provide to the model"
}
},
"required": ["modelId", "prompt"]
}
}
}
},
"responses": {
"200": {
"description": "Successful response",
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"result": {
"type": "string",
"description": "The result of calling the model with the provided prompt and optional image"
}
}
}
}
}
}
}
}
}
}
}
Orchestrationタブで、 Override orchestration template defaultsオプションを有効にします。 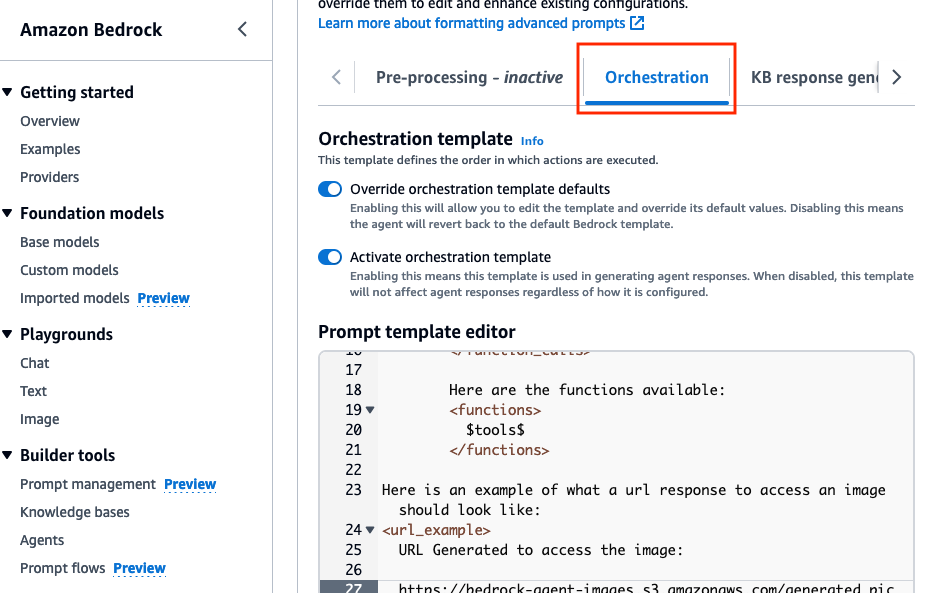
Here is an example of what a url response to access an image should look like:
<url_example>
URL Generated to access the image:
https://bedrock-agent-images.s3.amazonaws.com/generated_pic.png?AWSAccessKeyId=123xyz&Signature=rlF0gN%2BuaTHzuEDfELz8GOwJacA%3D&x-amz-security-token=IQoJb3JpZ2msqKr6cs7sTNRG145hKcxCUngJtRcQ%2FzsvDvt0QUSyl7xgp8yldZJu5Jg%3D%3D&Expires=1712628409
</url_example>
このプロンプトは、S3 バケットで画像が生成された後に署名付き URL の応答をフォーマットする際のサンプルをエージェントに提供するのに役立ちます。さらに、より詳細な書式設定のためにカスタム パーサー Lambda 関数を使用するオプションもあります。
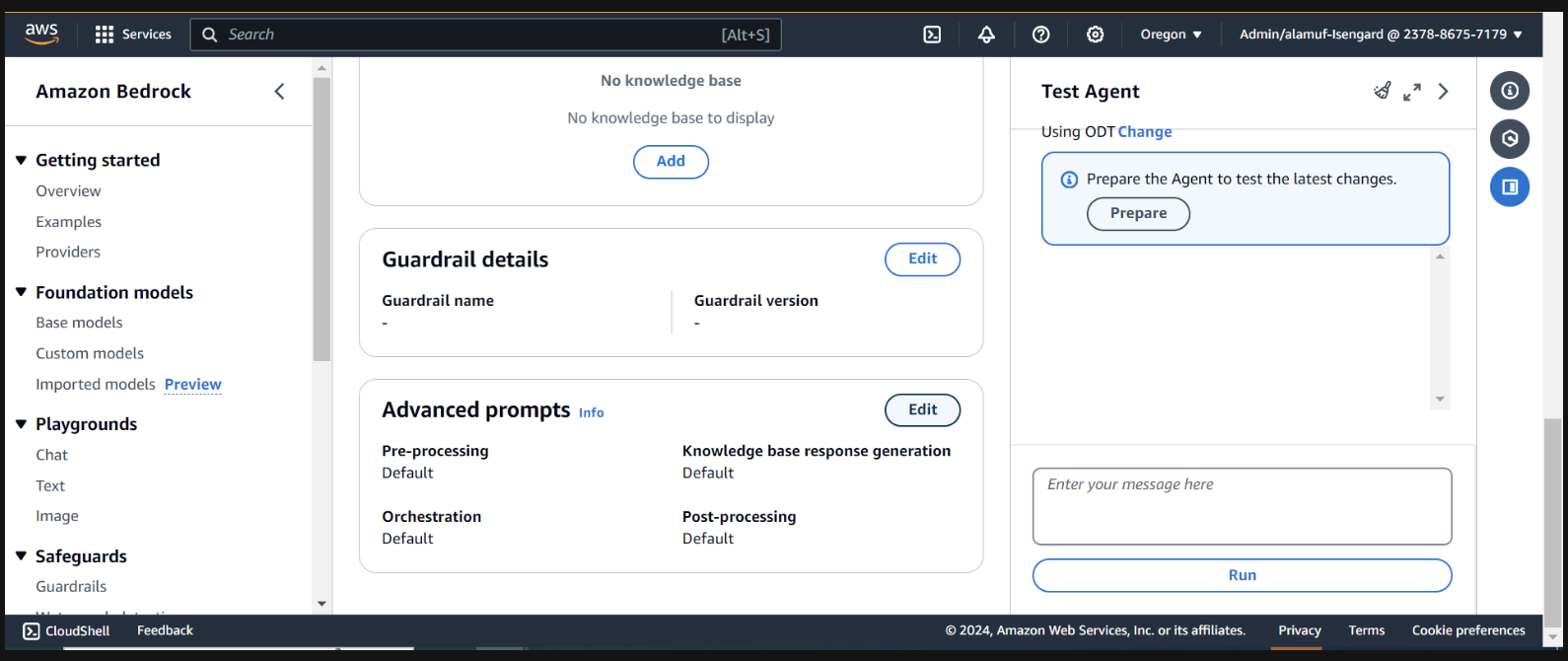
一番下までスクロールし、「 Save and exitボタンを選択します。
その後、必ず上部にあるSave and exitボタンをもう一度押してから、右側のテスト エージェント UI の上部にある[準備] ボタンを押してください。これにより、最新の変更をテストできるようになります。
(続行する前に、テストを予定しているすべてのモデルを Amazon Bedrock コンソール経由で有効にしてください。)
テストを開始するには、エージェント ビルダー ページで準備ボタンを見つけてエージェントを準備します。 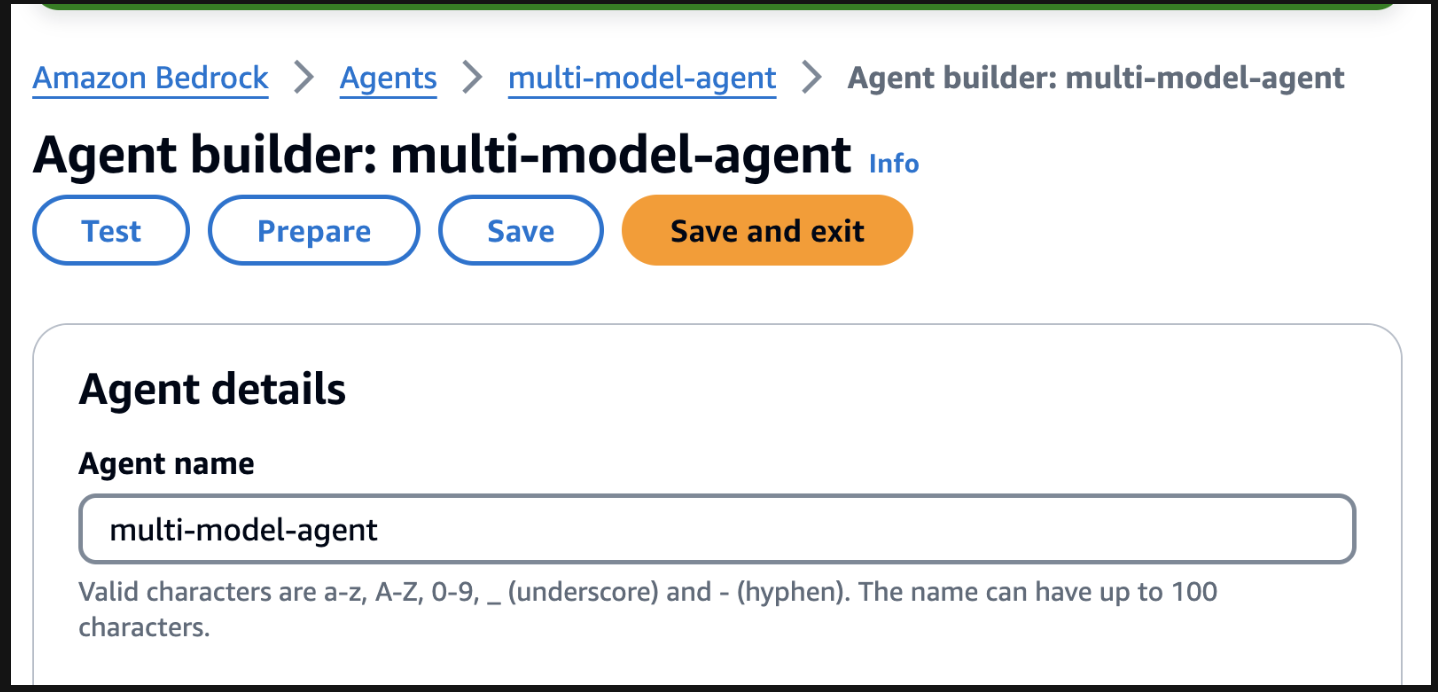
右側に、ユーザー入力フィールドを使用してエージェントをテストするオプションが表示されます。以下に、テストできるプロンプトをいくつか示します。ただし、創造力を発揮してプロンプトのバリエーションをテストすることをお勧めします。
テストする前に注意すべきことが 1 つあります。テキストから画像へ、または画像からテキストへの変換を行う場合、プロジェクト コードは同じ .png ファイルを静的に参照します。理想的な環境では、このステップをより動的に構成できます。
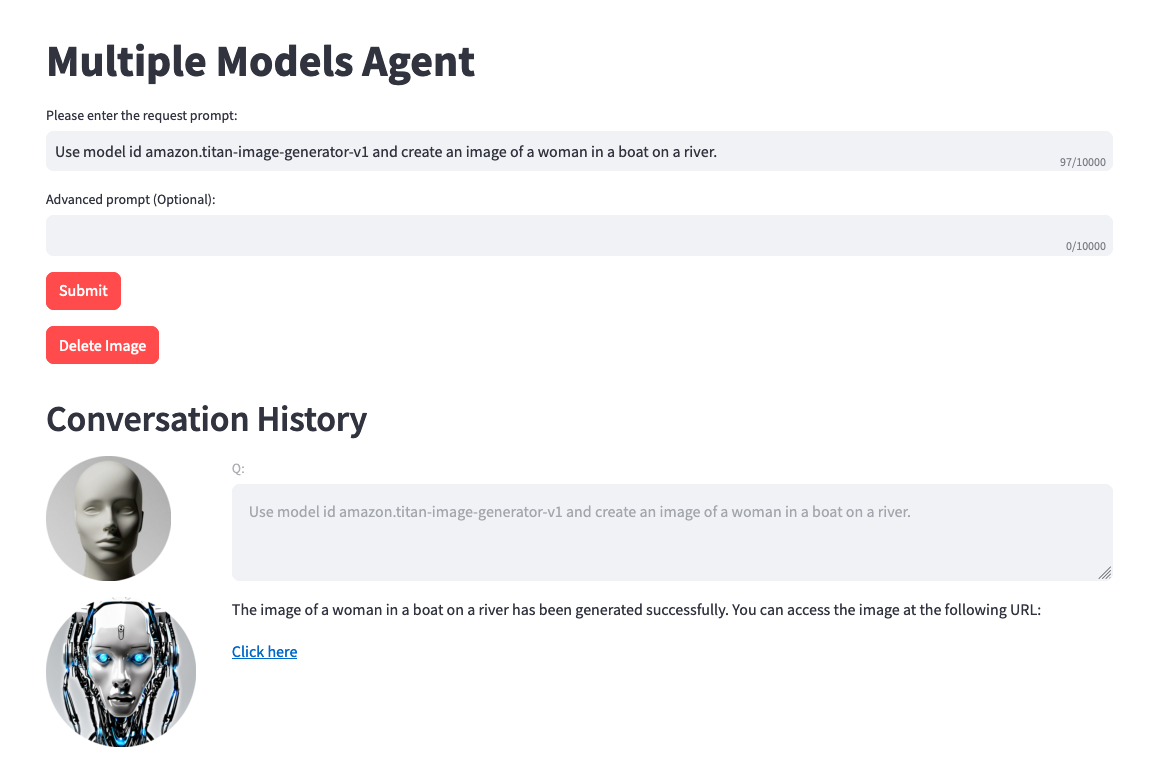
Use model amazon.titan-image-generator-v1 and create me an image of a woman in a boat on a river.
Use model anthropic.claude-3-haiku-20240307-v1:0 and describe to me the image that is uploaded. The model function will have the information needed to provide a response. So, dont ask about the image.
Use model stability.stable-diffusion-xl-v1. Create an image of an astronaut riding a horse in the desert.
Use model meta.llama3-70b-instruct-v1:0. You are a gifted copywriter, with special expertise in writing Google ads. You are tasked to write a persuasive and personalized Google ad based on a company name and a short description. You need to write the Headline and the content of the Ad itself. For example: Company: Upwork Description: Freelancer marketplace Headline: Upwork: Hire The Best - Trust Your Job To True Experts Ad: Connect your business to Expert professionals & agencies with specialized talent. Post a job today to access Upwork's talent pool of quality professionals & agencies. Grow your team fast. 90% of customers rehire. Trusted by 5M+ businesses. Secure payments. - Write a persuasive and personalized Google ad for the following company. Company: Click Description: SEO services
(このプロジェクトで UI をセットアップしたい場合は、ステップ 6 に進みます)
このステップでは、 agent IDとともにagent alias ID ID が必要です。 Bedrock 管理コンソールに移動し、マルチモデル エージェントを選択します。 Agent overviewセクションの右上からAgent IDコピーします。次に、 「Aliases」まで下にスクロールし、 「Create」を選択します。エイリアスにa1という名前を付けて、エージェントを作成します。エイリアス名ではなく、生成されたエイリアス ID を保存します。 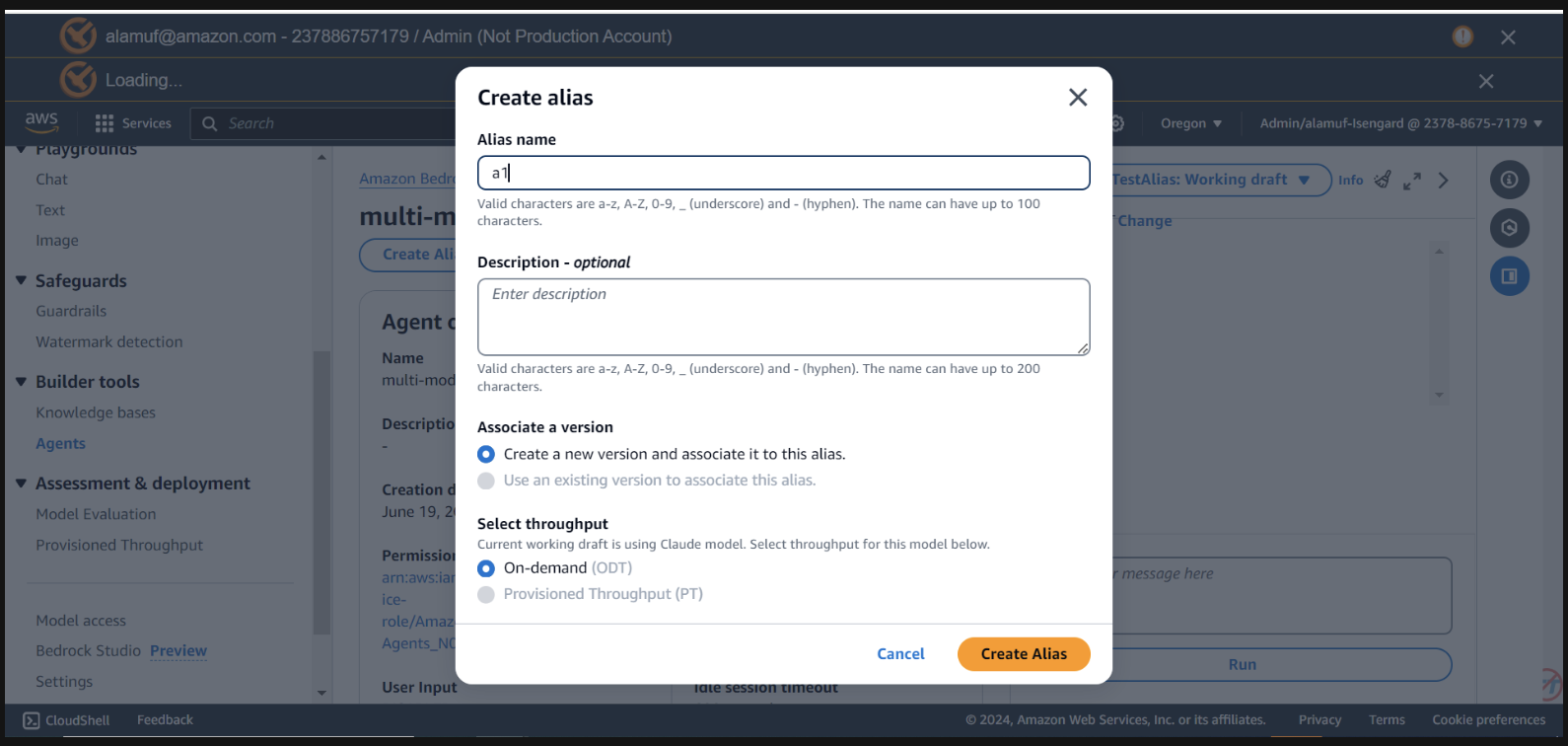
ここで、プロジェクトを開くために使用した IDE に戻ります。
streamlit_app ディレクトリに移動します。
構成の更新:
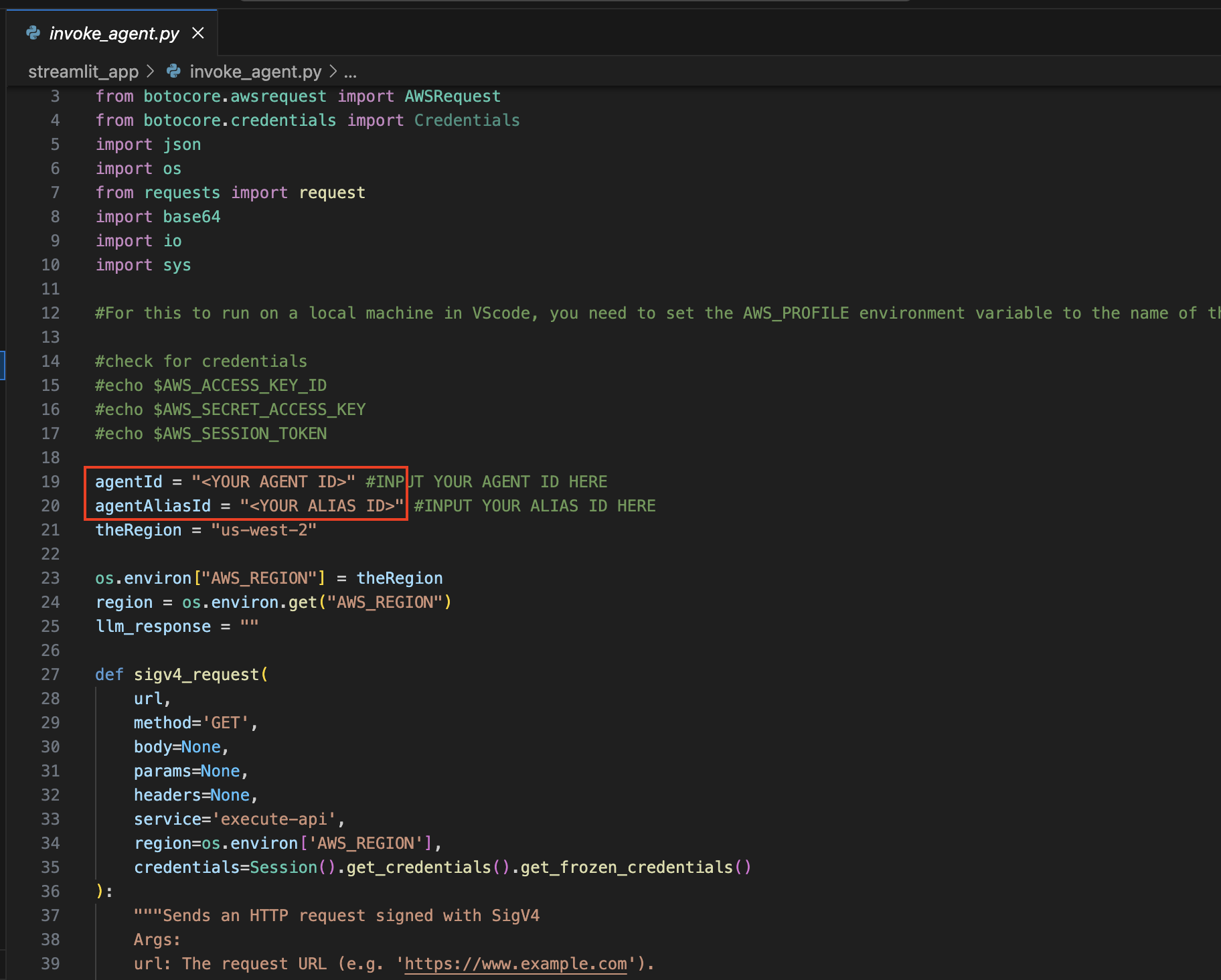
invoke_agent.pyファイルを開きます。
19 行目と 20 行目で、 agentId変数とagentAliasId変数を適切な値で更新し、保存します。
Streamlit をインストールします(まだインストールされていない場合)。
次のコマンドを実行して、必要な依存関係をすべてインストールします。
pip install streamlit boto3 pandasStreamlit アプリを実行します。
streamlit_appディレクトリ内で次のコマンドを実行します。 streamlit run app.py
Amazon Bedrock から入手可能な任意のモデルを使用でき、上記のリストに限定されないことに注意してください。モデル ID がリストされていない場合は、こちらの Amazon Bedrock ドキュメント ページで利用可能な最新のモデル (ID) を参照してください。
提供されたプロジェクトを活用して、独自のデータセットやユースケースに対してこのソリューションを微調整し、ベンチマークすることができます。さまざまなモデルの組み合わせを探索し、可能性の限界を押し広げ、進化し続ける生成 AI の状況でイノベーションを推進します。
詳細については、「貢献」を参照してください。
このライブラリは、MIT-0 ライセンスに基づいてライセンスされています。 LICENSE ファイルを参照してください。


