QuillGPT
1.0.0

QuillGPT は、Vaswani らの論文「Attending is All You Need」のアーキテクチャに基づく GPT デコーダ ブロックの実装です。アル。 PyTorchで実装されています。さらに、このリポジトリには、2 つの事前トレーニング済みモデル (Shakespearean GPT と Harpoon GPT) がトレーニング済みの重みとともに含まれています。実験とデプロイを容易にするために、これらのモデルをインタラクティブに探索できる Streamlit Playground と、スケーラブルなデプロイメントを実現する Docker コンテナ化で実装された FastAPI マイクロサービスが提供されています。新しい GPT モデルをトレーニングして推論を実行するための Python スクリプトや、トレーニングされたモデルを紹介するノートブックもあります。テキストのエンコードとデコードを容易にするために、単純なトークナイザーが実装されています。 QuillGPT を調べてこれらのツールを活用し、自然言語処理プロジェクトを強化してください。
このリポジトリには、2 つの事前トレーニングされたモデルと重みが含まれています。
| 特徴 | シェイクスピアの GPT | ハープーン GPT |
|---|---|---|
| パラメータ | 10.7メートル | 226M |
| 重み | 重み | 重み |
| モデル構成 | 構成 | 構成 |
| トレーニングデータ | シェイクスピア劇のテキスト (input.txt) | 本からのランダムなテキスト (corpus.txt) |
| 埋め込みタイプ | 文字の埋め込み | 文字の埋め込み |
| トレーニングノート | ノート | ノート |
| ハードウェア | NVIDIA T4 | NVIDIA A100 |
| トレーニングと検証の損失 | 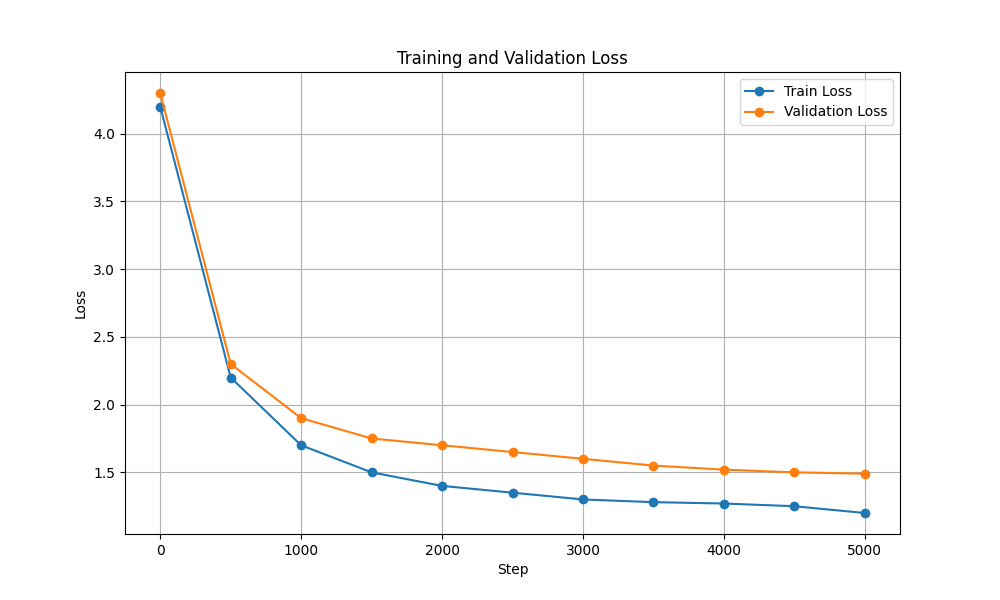 | 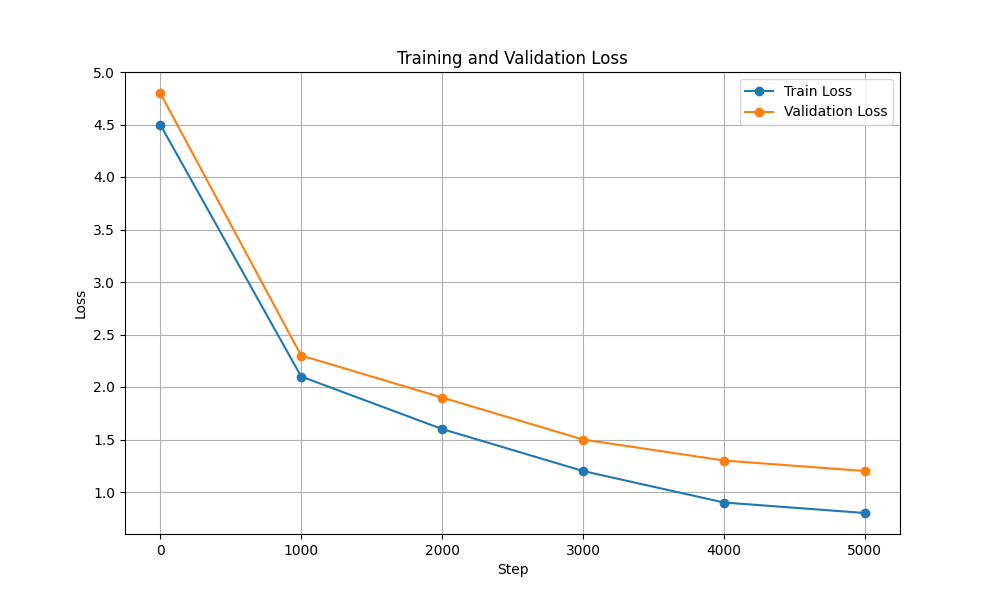 |
トレーニングおよび推論スクリプトを実行するには、次の手順に従います。
git clone https://github.com/NotShrirang/GPT-From-Scratch.git
cd GPT-From-Scratchpip install -r requirements.txt続行する前に、必ずここから Harpoon GPT のウェイトをダウンロードしてください。
Streamlit Cloud Service でホストされています。こちらのリンクからアクセスできます。
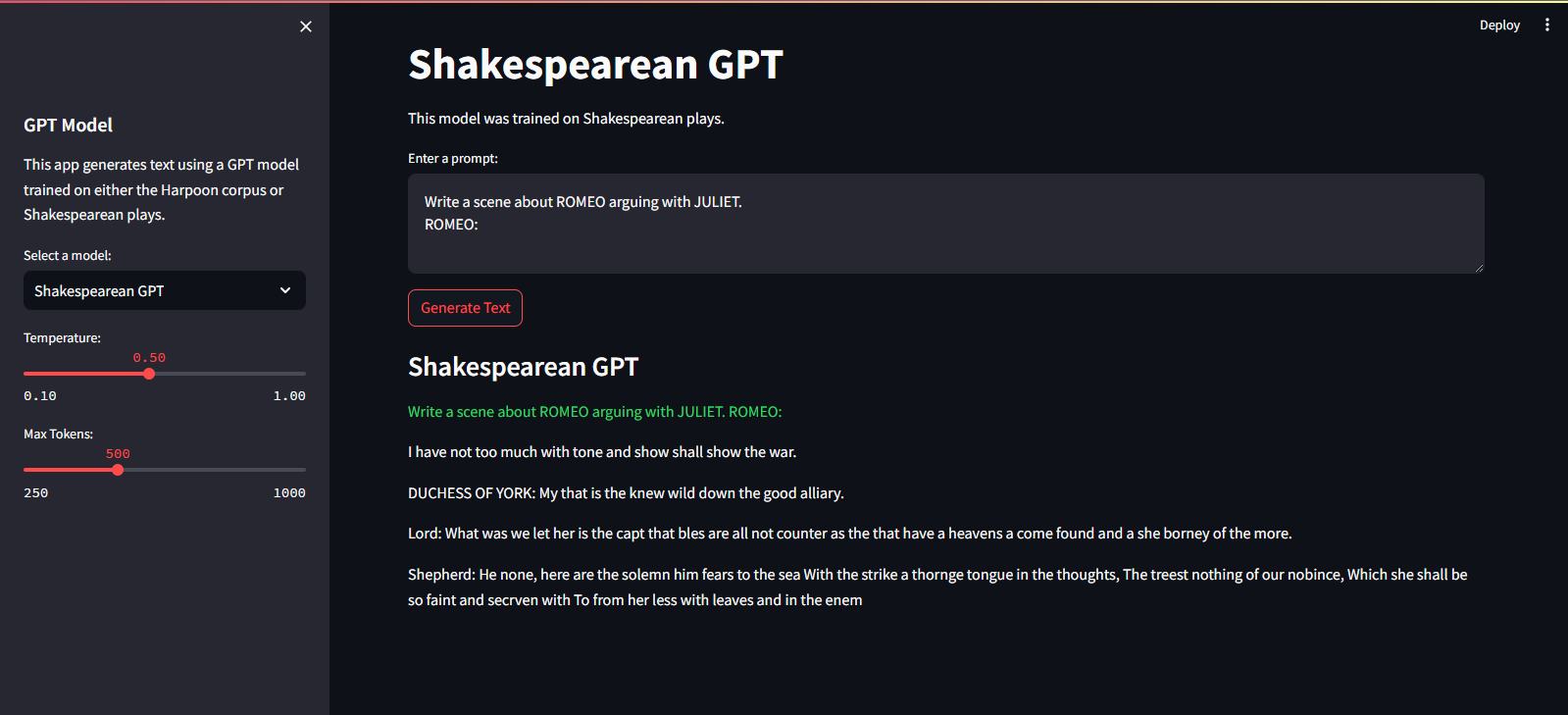
streamlit run app.pypython main.py./run.sh start-dev./run.sh stop-devGPT モデルをトレーニングするには、次の手順に従います。
データを準備します。テキスト データ全体を 1 つの .txt ファイルに入れて保存します。
トランスフォーマーの構成を書き込み、ファイルを保存します。
例: json { "data_path": "data/corpus.txt", "vocab_size": 135, "batch_size": 32, "block_size": 256, "max_iters": 3000, "eval_interval": 300, "learning_rate": 3e-5, "eval_iters": 50, "n_embd": 1024, "n_head": 12, "n_layer": 18, "dropout": 0.3, }
スクリプトscripts/train_gpt.py使用してモデルをトレーニングする
python scripts/train_gpt.py
--config_path config/config.json
--data_path data/corpus.txt
--output_dir trained_models (要件に応じてconfig_path 、 data_path 、およびoutput_dir変更できます。)
output_dirに保存されます。トレーニング後、トレーニングされた GPT モデルをテキスト生成に使用できます。トレーニングされたモデルを推論に使用する例を次に示します。
python scripts/inference_gpt.py
--config_path config/shakespearean_config.json
--weights_path weights/GPT_model_char.pt
--max_length 500
--prompt " Once upon a time " 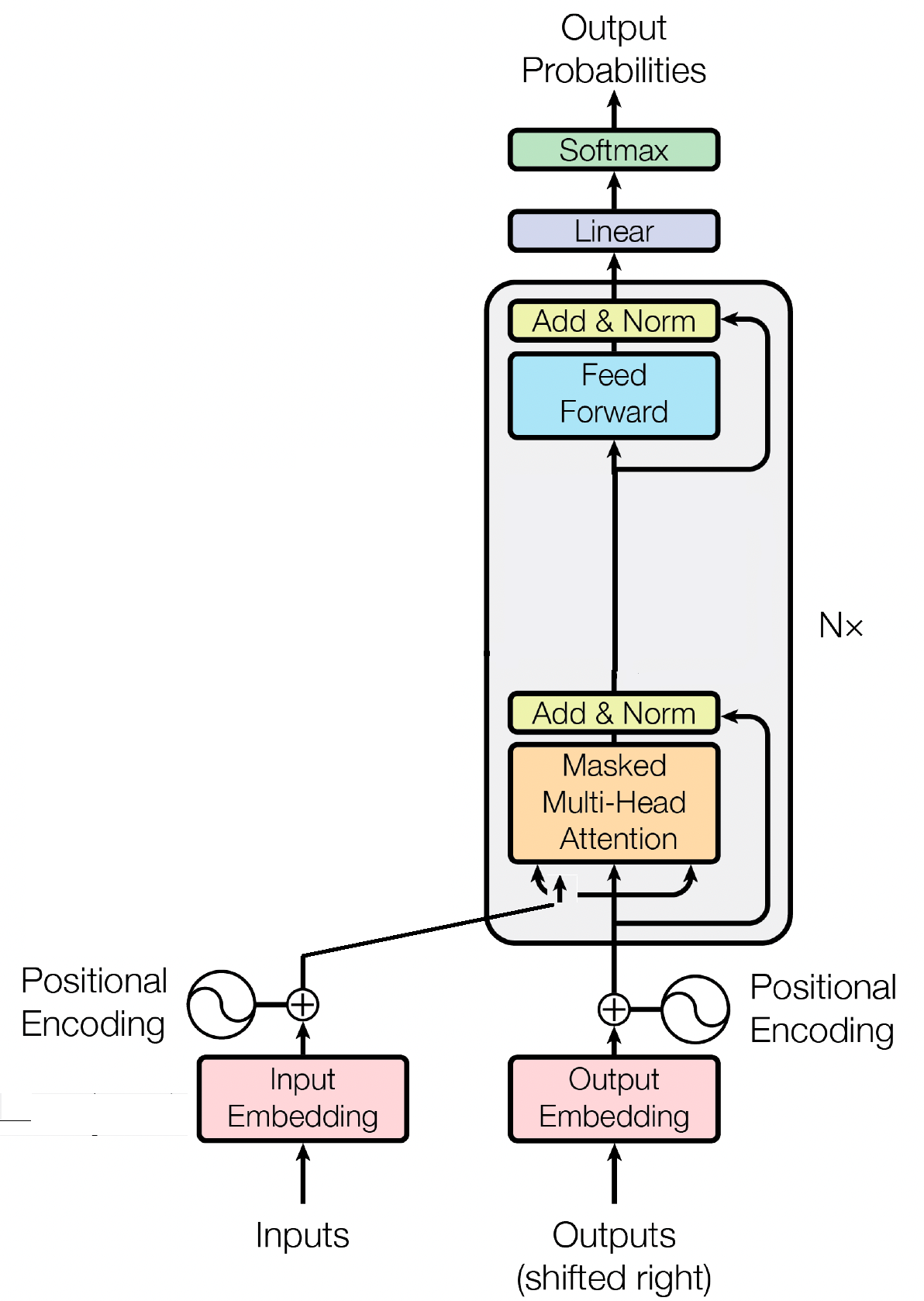
デコーダ ブロックは GPT (Generative Pre-trained Transformer) モデルの重要なコンポーネントであり、GPT が実際にテキストを生成する場所です。セルフアテンション メカニズムを利用して入力シーケンスを処理し、一貫した出力を生成します。各デコーダ ブロックは、セルフ アテンション レイヤー、フィードフォワード ニューラル ネットワーク、レイヤー正規化などの複数のレイヤーで構成されます。セルフ アテンション レイヤーを使用すると、モデルはシーケンス内のさまざまな単語の重要性を比較検討し、単語の位置に関係なくコンテキストと依存関係を把握できます。これにより、GPT モデルは文脈に関連したテキストを生成できるようになります。
入力エンベディングは、入力トークンを意味のある数値表現に変換することにより、GPT のようなトランスフォーマーベースのモデルで重要な役割を果たします。これらの埋め込みはモデルへの最初の入力として機能し、シーケンス内の単語に関する意味情報をキャプチャします。このプロセスには、入力シーケンス内の各トークンを高次元ベクトル空間にマッピングすることが含まれます。そこでは、同様のトークンが互いに近くに配置されます。これにより、モデルはさまざまな単語間の関係を理解し、入力データから効果的に学習できるようになります。入力エンベディングは、モデルの後続の層に供給されて、さらなる処理が行われます。
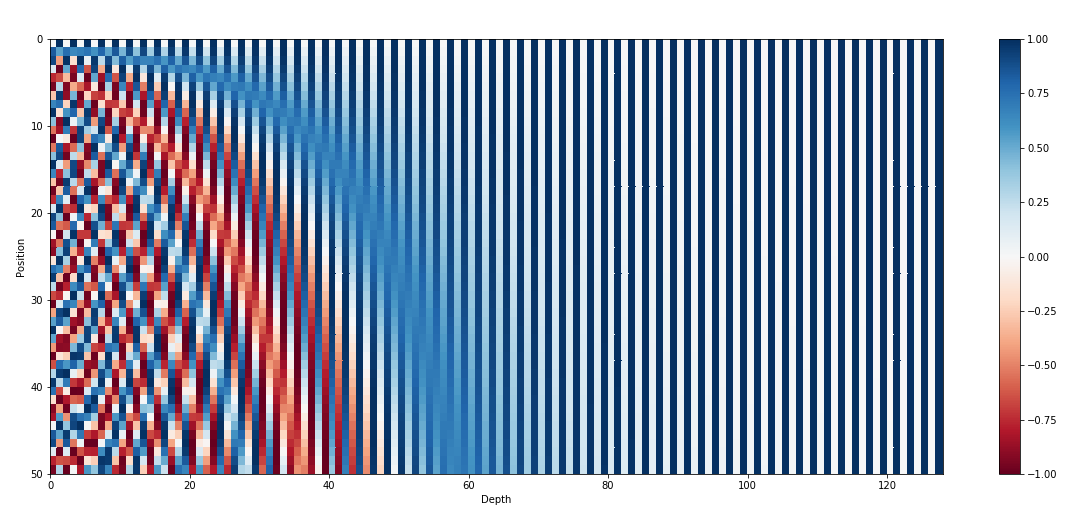
入力エンベディングに加えて、位置エンベディングも GPT などのトランスフォーマー アーキテクチャの重要なコンポーネントです。トランスフォーマーにはシーケンス内のトークンの順序に関する固有の情報が欠けているため、モデルに位置情報を提供するために位置埋め込みが導入されます。これらの埋め込みはシーケンス内の各トークンの位置をエンコードし、モデルが位置に基づいてトークンを区別できるようにします。位置埋め込みを組み込むことにより、GPT のようなトランスフォーマーはデータの連続的な性質を効果的にキャプチャし、生成されたテキスト内の単語の正しい順序を維持する一貫した出力を生成できます。

GPT のようなトランスフォーマーベースのモデルの基本的なメカニズムである自己注意は、シーケンス内のさまざまな単語に重要度スコアを割り当てることによって機能します。このプロセスには 3 つの重要なステップが含まれます。つまり、注意スコアを計算し、ソフトマックスを適用して注意の重みを取得し、最後にこれらの重みを入力埋め込みと組み合わせて、コンテキストに基づいた表現を生成します。その中核となる自己注意により、モデルは重要性の低い単語を強調せずに、関連する単語にさらに集中できるようになり、入力データ内の文脈上の依存関係の効果的な学習が促進されます。このメカニズムは、長距離の依存関係や文脈上のニュアンスを捉える上で極めて重要であり、トランスフォーマー モデルが長いテキスト シーケンスを生成できるようになります。
MIT © シュリラン・マハジャン
お気軽にプル リクエストを送信したり、問題を作成したり、情報を広めたりしてください。
このリポジトリにスターを付けるだけで私をサポートしてください!


