marqo ecommerce embeddings
1.0.0
この作業では、e コマース製品用の 2 つの最先端の埋め込みモデル、Marqo-Ecommerce-B と Marqo-Ecommerce-L を紹介します。
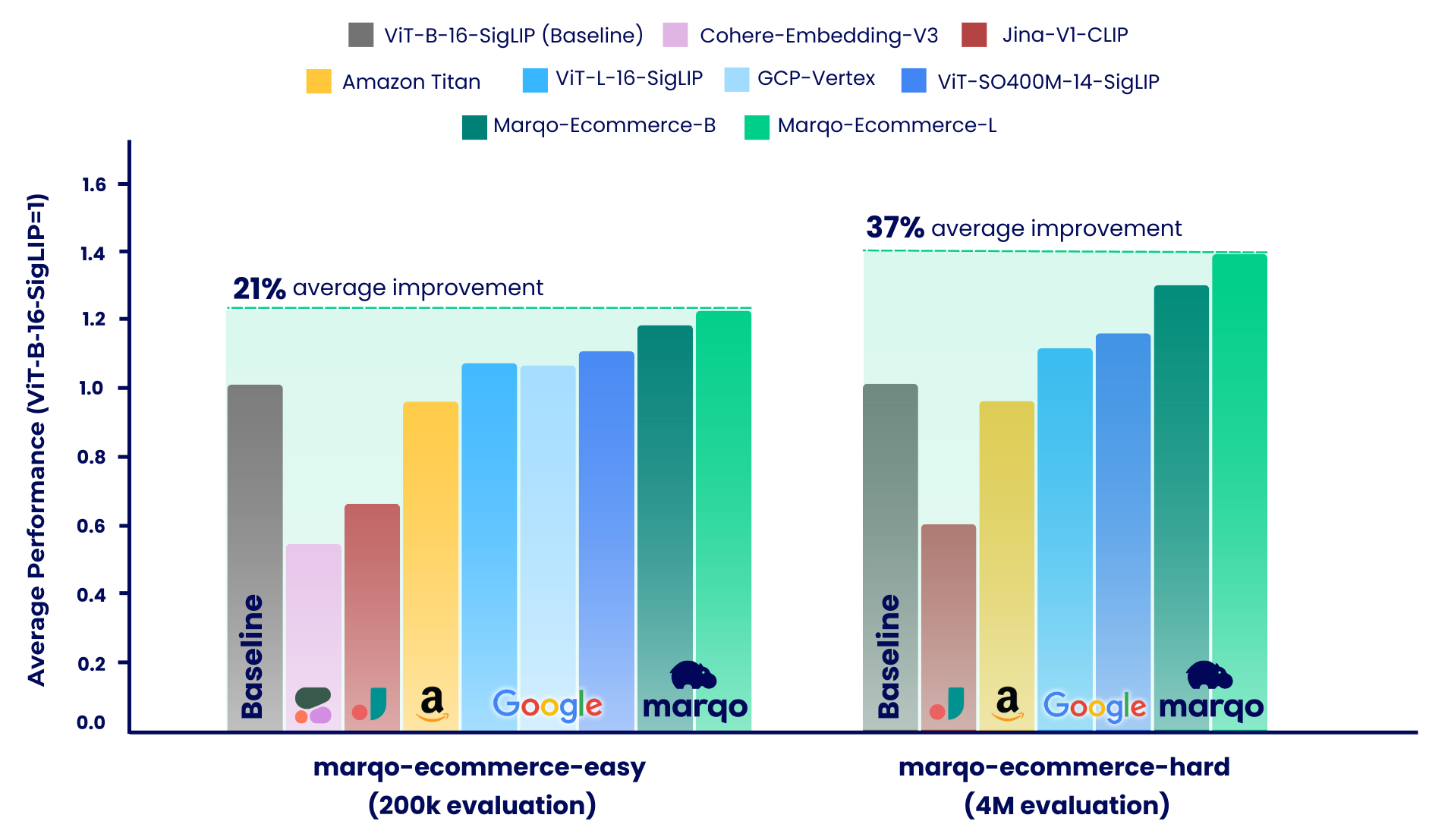
ベンチマークの結果は、Marqo-Ecommerce モデルがさまざまな指標において他のすべてのモデルよりも一貫して優れていることを示しています。具体的には、 marqo-ecommerce-L marqo-ecommerce-hardの 3 つのタスクすべてにおいて、現在最高のオープンソース モデルであるViT-SO400M-14-SigLIPと比較して、 MRR で 17.6% 、 nDCG@10 で20.5% の平均改善を達成しました。 marqo-ecommerce-hardデータセット。最高のプライベート モデルであるAmazon-Titan-Multimodalと比較すると、3 つのタスクすべてでMRR が 38.9% 、 nDCG@10 で 45.1%の平均改善が見られ、Text-to-Image タスク全体で再現率が 35.9%向上しました。 marqo-ecommerce-hardデータセット。
その他のベンチマーク結果は以下でご覧いただけます。
公開内容:
| 埋め込みモデル | #Params (メートル) | 寸法 | ハグ顔 | .pt をダウンロード | 単一バッチのテキスト推論 (A10g) | 単一バッチ画像推論 (A10g) |
|---|---|---|---|---|---|---|
| Marqo-Ecommerce-B | 203 | 768 | Marqo/marqo-ecommerce-embeddings-B | リンク | 5.1ミリ秒 | 5.7ミリ秒 |
| マルコ-eコマース-L | 652 | 1024 | マルコ/marqo-ecommerce-embeddings-L | リンク | 10.3ミリ秒 | 11.0ミリ秒 |
OpenCLIP にモデルをロードするには、以下を参照してください。モデルは Hugging Face でホストされ、OpenCLIP を使用してロードされます。このコードはrun_models.py内にもあります。
pip install open_clip_torch
from PIL import Image
import open_clip
import requests
import torch
# Specify model from Hugging Face Hub
model_name = 'hf-hub:Marqo/marqo-ecommerce-embeddings-L'
model , preprocess_train , preprocess_val = open_clip . create_model_and_transforms ( model_name )
tokenizer = open_clip . get_tokenizer ( model_name )
# Preprocess the image and tokenize text inputs
# Load an example image from a URL
img = Image . open ( requests . get ( 'https://raw.githubusercontent.com/marqo-ai/marqo-ecommerce-embeddings/refs/heads/main/images/dining-chairs.png' , stream = True ). raw )
image = preprocess_val ( img ). unsqueeze ( 0 )
text = tokenizer ([ "dining chairs" , "a laptop" , "toothbrushes" ])
# Perform inference
with torch . no_grad (), torch . cuda . amp . autocast ():
image_features = model . encode_image ( image , normalize = True )
text_features = model . encode_text ( text , normalize = True )
# Calculate similarity probabilities
text_probs = ( 100.0 * image_features @ text_features . T ). softmax ( dim = - 1 )
# Display the label probabilities
print ( "Label probs:" , text_probs )
# [1.0000e+00, 8.3131e-12, 5.2173e-12]Transformers にモデルをロードするには、以下を参照してください。モデルは Hugging Face でホストされ、Transformers を使用してロードされます。
from transformers import AutoModel , AutoProcessor
import torch
from PIL import Image
import requests
model_name = 'Marqo/marqo-ecommerce-embeddings-L'
# model_name = 'Marqo/marqo-ecommerce-embeddings-B'
model = AutoModel . from_pretrained ( model_name , trust_remote_code = True )
processor = AutoProcessor . from_pretrained ( model_name , trust_remote_code = True )
img = Image . open ( requests . get ( 'https://raw.githubusercontent.com/marqo-ai/marqo-ecommerce-embeddings/refs/heads/main/images/dining-chairs.png' , stream = True ). raw ). convert ( "RGB" )
image = [ img ]
text = [ "dining chairs" , "a laptop" , "toothbrushes" ]
processed = processor ( text = text , images = image , padding = 'max_length' , return_tensors = "pt" )
processor . image_processor . do_rescale = False
with torch . no_grad ():
image_features = model . get_image_features ( processed [ 'pixel_values' ], normalize = True )
text_features = model . get_text_features ( processed [ 'input_ids' ], normalize = True )
text_probs = ( 100 * image_features @ text_features . T ). softmax ( dim = - 1 )
print ( text_probs )
# [1.0000e+00, 8.3131e-12, 5.2173e-12]評価には一般化比較学習 (GCL) が使用されます。次のコードはscripts内にもあります。
git clone https://github.com/marqo-ai/GCL
GCL に必要なパッケージをインストールします。
1. GoogleShopping-Text2Image の取得。
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/gs-title2image
mkdir -p $outdir
hfdataset=Marqo/google-shopping-general-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['title']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
2. GoogleShopping-Category2画像の取得。
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/gs-cat2image
mkdir -p $outdir
hfdataset=Marqo/google-shopping-general-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['query']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
3. AmazonProducts-Category2 の画像の取得。
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/ap-title2image
mkdir -p $outdir
hfdataset=Marqo/amazon-products-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['title']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
私たちのベンチマーク プロセスは、marqo-ecommerce-hard と marqo-ecommerce-easy という、e コマース商品リストの異なるデータセットを使用する 2 つの異なるレジームに分割されました。どちらのデータセットにも商品画像とテキストが含まれており、サイズのみが異なります。 「簡単な」データセットは約 10 ~ 30 倍小さく (200k 対 4M 製品)、レート制限モデル、特に Cohere-Embeddings-v3 と GCP-Vertex (それぞれ 0.66 rps と 2 rps の制限) に対応するように設計されています。 「ハード」データセットは、400 万件の e コマース商品リストを含み、現実世界の e コマース検索シナリオをよりよく表しているため、真の課題を表しています。
これらの両方のシナリオ内で、モデルは 3 つの異なるタスクに対してベンチマークが行われました。
Marqo-Ecommerce-Hard は、400 万のデータセット全体を使用して実施された包括的な評価を調査し、現実世界のコンテキストにおけるモデルの堅牢なパフォーマンスを強調しています。
GoogleShopping-Text2Image の取得。
| 埋め込みモデル | 地図 | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| マルコ-eコマース-L | 0.682 | 0.878 | 0.683 | 0.726 |
| Marqo-Ecommerce-B | 0.623 | 0.832 | 0.624 | 0.668 |
| ViT-SO400M-14-SigLip | 0.573 | 0.763 | 0.574 | 0.613 |
| ViT-L-16-シグリップ | 0.540 | 0.722 | 0.540 | 0.577 |
| ViT-B-16-シグリップ | 0.476 | 0.660 | 0.477 | 0.513 |
| Amazon-Titan-MultiModal | 0.475 | 0.648 | 0.475 | 0.509 |
| ジナ-V1-CLIP | 0.285 | 0.402 | 0.285 | 0.306 |
GoogleShopping-Category2画像の取得。
| 埋め込みモデル | 地図 | P@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| マルコ-eコマース-L | 0.463 | 0.652 | 0.822 | 0.666 |
| Marqo-Ecommerce-B | 0.423 | 0.629 | 0.810 | 0.644 |
| ViT-SO400M-14-SigLip | 0.352 | 0.516 | 0.707 | 0.529 |
| ViT-L-16-シグリップ | 0.324 | 0.497 | 0.687 | 0.509 |
| ViT-B-16-シグリップ | 0.277 | 0.458 | 0.660 | 0.473 |
| Amazon-Titan-MultiModal | 0.246 | 0.429 | 0.642 | 0.446 |
| ジナ-V1-CLIP | 0.123 | 0.275 | 0.504 | 0.294 |
AmazonProducts-Text2Image の取得。
| 埋め込みモデル | 地図 | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| マルコ-eコマース-L | 0.658 | 0.854 | 0.663 | 0.703 |
| Marqo-Ecommerce-B | 0.592 | 0.795 | 0.597 | 0.637 |
| ViT-SO400M-14-SigLip | 0.560 | 0.742 | 0.564 | 0.599 |
| ViT-L-16-シグリップ | 0.544 | 0.715 | 0.548 | 0.580 |
| ViT-B-16-シグリップ | 0.480 | 0.650 | 0.484 | 0.515 |
| Amazon-Titan-MultiModal | 0.456 | 0.627 | 0.457 | 0.491 |
| ジナ-V1-CLIP | 0.265 | 0.378 | 0.266 | 0.285 |
前述したように、ベンチマーク プロセスは、marqo-ecommerce-hard と marqo-ecommerce-easy の 2 つの異なるシナリオに分割されました。このセクションでは、コーパスが 10 ~ 30 倍小さく、レート制限モデルに対応するように設計された後者について説明します。 2 つのデータセットにわたる 200,000 個の製品全体を使用して実施された包括的な評価を検討します。上記ですでにベンチマークが行われているモデルに加えて、これらのベンチマークには Cohere-embedding-v3 と GCP-Vertex も含まれています。
GoogleShopping-Text2Image の取得。
| 埋め込みモデル | 地図 | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| マルコ-eコマース-L | 0.879 | 0.971 | 0.879 | 0.901 |
| Marqo-Ecommerce-B | 0.842 | 0.961 | 0.842 | 0.871 |
| ViT-SO400M-14-SigLip | 0.792 | 0.935 | 0.792 | 0.825 |
| GCP-頂点 | 0.740 | 0.910 | 0.740 | 0.779 |
| ViT-L-16-シグリップ | 0.754 | 0.907 | 0.754 | 0.789 |
| ViT-B-16-シグリップ | 0.701 | 0.870 | 0.701 | 0.739 |
| Amazon-Titan-MultiModal | 0.694 | 0.868 | 0.693 | 0.733 |
| ジナ-V1-CLIP | 0.480 | 0.638 | 0.480 | 0.511 |
| Cohere-embedding-v3 | 0.358 | 0.515 | 0.358 | 0.389 |
GoogleShopping-Category2画像の取得。
| 埋め込みモデル | 地図 | P@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| マルコ-eコマース-L | 0.515 | 0.358 | 0.764 | 0.590 |
| Marqo-Ecommerce-B | 0.479 | 0.336 | 0.744 | 0.558 |
| ViT-SO400M-14-SigLip | 0.423 | 0.302 | 0.644 | 0.487 |
| GCP-頂点 | 0.417 | 0.298 | 0.636 | 0.481 |
| ViT-L-16-シグリップ | 0.392 | 0.281 | 0.627 | 0.458 |
| ViT-B-16-シグリップ | 0.347 | 0.252 | 0.594 | 0.414 |
| Amazon-Titan-MultiModal | 0.308 | 0.231 | 0.558 | 0.377 |
| ジナ-V1-CLIP | 0.175 | 0.122 | 0.369 | 0.229 |
| Cohere-embedding-v3 | 0.136 | 0.110 | 0.315 | 0.178 |
AmazonProducts-Text2Image の取得。
| 埋め込みモデル | 地図 | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| マルコ-eコマース-L | 0.92 | 0.978 | 0.928 | 0.940 |
| Marqo-Ecommerce-B | 0.897 | 0.967 | 0.897 | 0.914 |
| ViT-SO400M-14-SigLip | 0.860 | 0.954 | 0.860 | 0.882 |
| ViT-L-16-シグリップ | 0.842 | 0.940 | 0.842 | 0.865 |
| GCP-頂点 | 0.808 | 0.933 | 0.808 | 0.837 |
| ViT-B-16-シグリップ | 0.797 | 0.917 | 0.797 | 0.825 |
| Amazon-Titan-MultiModal | 0.762 | 0.889 | 0.763 | 0.791 |
| ジナ-V1-CLIP | 0.530 | 0.699 | 0.530 | 0.565 |
| Cohere-embedding-v3 | 0.433 | 0.597 | 0.433 | 0.465 |
@software{zhu2024marqoecommembed_2024,
author = {Tianyu Zhu and and Jesse Clark},
month = oct,
title = {{Marqo Ecommerce Embeddings - Foundation Model for Product Embeddings}},
url = {https://github.com/marqo-ai/marqo-ecommerce-embeddings/},
version = {1.0.0},
year = {2024}
}


