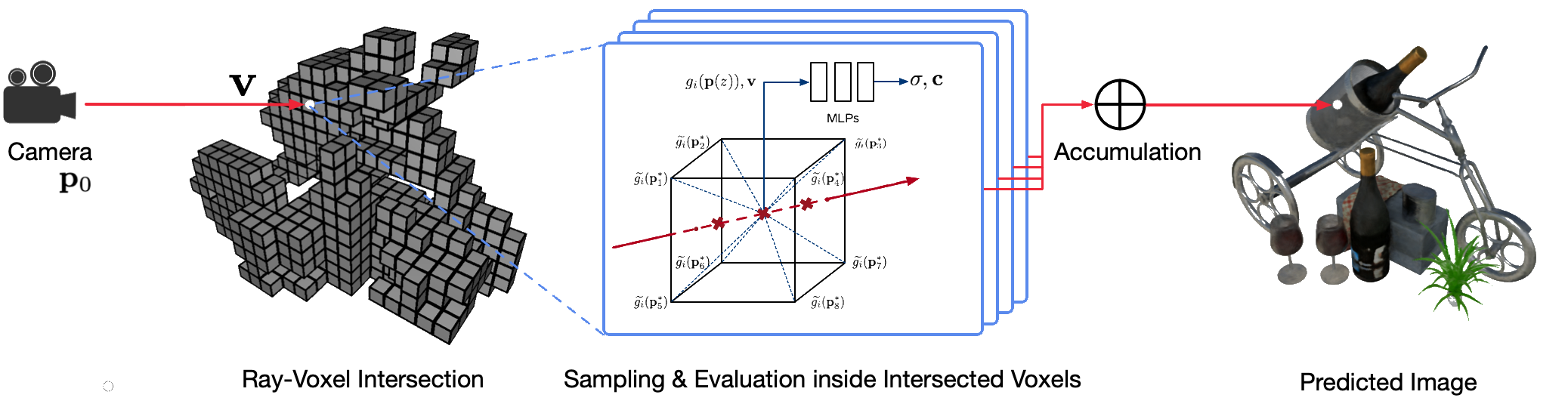
古典的なコンピュータ グラフィックス技術を使用した現実世界のシーンのフォトリアリスティックな自由視点レンダリングは、詳細な外観と形状モデルをキャプチャするという困難な手順を必要とするため、困難な問題です。ニューラル レンダリングは、ディープ ニューラル ネットワークを使用して、粗いジオメトリの有無にかかわらず 2D 観察からジオメトリと外観の両方をカプセル化するシーン表現を暗黙的に学習する新興分野です。ただし、この分野の既存のアプローチでは、レンダリングがぼやけたり、レンダリング プロセスが遅くなったりすることがよくあります。私たちは、高速かつ高品質な自由視点レンダリングのための新しいニューラル シーン表現である Neural Sparse Voxel Fields (NSVF) を提案します。
この論文の公式リポジトリは次のとおりです。
また、次の非公式実装も提供しています。
このコードは、fairseq フレームワークを使用して PyTorch に実装されています。
コードは次のシステムでテストされています。
GPU での学習とレンダリングのみがサポートされます。
インストールするには、まずこのリポジトリのクローンを作成し、すべての依存関係をインストールします。
pip install -r requirements.txtそれから、走ってください
pip install --editable ./または、コードをローカルにインストールする場合は、次を実行します。
python setup.py build_ext --inplace私たちの論文で使用されている前処理された合成データセットと実際のデータセットをダウンロードできます。著作物に原論文を使用する場合は、原論文も引用してください。
| データセット | ダウンロードリンク | データセットの分割に関する注意事項 |
|---|---|---|
| 合成NSVF | ダウンロード (.zip) | 0_* (トレーニング) 1_* (検証) 2_* (テスト) |
| 合成 NeRF | ダウンロード (.zip) | 0_* (トレーニング) 1_* (検証) 2_* (テスト) |
| BlendedMVS | ダウンロード (.zip) | 0_* (トレーニング) 1_* (テスト) |
| 戦車と寺院 | ダウンロード (.zip) | 0_* (トレーニング) 1_* (テスト) |
トレーニングとテスト用に単一シーンの新しいデータセットを準備するには、次のデータ構造に従ってください。
< dataset_name >
| -- bbox.txt # bounding-box file
| -- intrinsics.txt # 4x4 camera intrinsics
| -- rgb
| -- 0.png # target image for each view
| -- 1.png
...
| -- pose
| -- 0.txt # camera pose for each view (4x4 matrices)
| -- 1.txt
...
[optional]
| -- test_traj.txt # camera pose for free-view rendering demonstration (4N x 4)ここで、 bbox.txtファイルには、初期バウンディング ボックスとボクセル サイズを説明する行が含まれています。
x_min y_min z_min x_max y_max z_max initial_voxel_sizeターゲット画像のファイル名と、対応するカメラポーズファイルのファイル名は完全に同じである必要はないことに注意してください。ただし、これら 2 種類のファイル (文字列でソート) の順序は一致する必要があります。データセットはビュー インデックスを使用して分割されます。たとえば、「 train (0..100) 、 valid (100..200)およびtest (200..400) 」 は、トレーニングでは最初の 100 ビュー、検証では 100 ~ 199 番目のビュー、テストでは 200 ~ 399 番目のビューを意味します。 。
単一シーンのデータセット ( {DATASET} ) を考慮して、次のコマンドを使用して NSVF モデルをトレーニングし、GPU あたり4のイメージとイメージあたり2048レイのバッチ サイズで800x800ピクセルの新しいビューを合成します。デフォルトでは、コードは利用可能なすべての GPU を自動的に検出します。
次の例では、事前定義されたアーキテクチャnsvf_base特定の引数とともに使用します。
--no-sampling-at-readerを設定すると、モデルはトレーニングのためにスパース ボクセルの投影画像領域内のピクセルのみをサンプリングします。bbox.txtファイルに記述されているボクセル サイズの1/8 (0.125)の比率に設定します。--use-octreeオンにするかどうかはオプションです。特にボクセル数が10000より大きい場合、スパース ボクセル オクツリーを構築してレイとボクセルの交差を高速化します。--pruning-every-steps 2500に設定すると、モデルは2500ステップごとに自己枝刈りを実行します。--half-voxel-size-atと--reduce-step-size-atを5000,25000,75000に設定すると、ボクセル サイズとステップ サイズはそれぞれ5k 、 25k 、 75kで半分になります。上記のパラメータ設定は論文のほとんどの実験に使用されていますが、より良い品質を達成するためにこれらのパラメータを調整することも可能であることに注意してください。上記のパラメータ以外にも、他のパラメータもデフォルト設定を使用できます。
アーキテクチャnsvf_baseほかに、他のアーキテクチャを確認したり、ファイルfairnr/models/nsvf.pyで独自のアーキテクチャを定義したりできます。
python -u train.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--train-views " 0..100 " --view-resolution " 800x800 "
--max-sentences 1 --view-per-batch 4 --pixel-per-view 2048
--no-preload
--sampling-on-mask 1.0 --no-sampling-at-reader
--valid-views " 100..200 " --valid-view-resolution " 400x400 "
--valid-view-per-batch 1
--transparent-background " 1.0,1.0,1.0 " --background-stop-gradient
--arch nsvf_base
--initial-boundingbox ${DATASET} /bbox.txt
--use-octree
--raymarching-stepsize-ratio 0.125
--discrete-regularization
--color-weight 128.0 --alpha-weight 1.0
--optimizer " adam " --adam-betas " (0.9, 0.999) "
--lr 0.001 --lr-scheduler " polynomial_decay " --total-num-update 150000
--criterion " srn_loss " --clip-norm 0.0
--num-workers 0
--seed 2
--save-interval-updates 500 --max-update 150000
--virtual-epoch-steps 5000 --save-interval 1
--half-voxel-size-at " 5000,25000,75000 "
--reduce-step-size-at " 5000,25000,75000 "
--pruning-every-steps 2500
--keep-interval-updates 5 --keep-last-epochs 5
--log-format simple --log-interval 1
--save-dir ${SAVE}
--tensorboard-logdir ${SAVE} /tensorboard
| tee -a $SAVE /train.logチェックポイントは{SAVE}に保存されます。テンソルボードを起動してトレーニングの進行状況を確認できます。
tensorboard --logdir= ${SAVE} /tensorboard --port=10000例の下には、論文の結果を再現するためのトレーニング スクリプトの例がさらにあります。
モデルがトレーニングされたら、次のコマンドを使用して、 {MODEL_PATH}が指定されたテスト ビューのレンダリング品質を評価します。
python validate.py ${DATASET}
--user-dir fairnr
--valid-views " 200..400 "
--valid-view-resolution " 800x800 "
--no-preload
--task single_object_rendering
--max-sentences 1
--valid-view-per-batch 1
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01,"tensorboard_logdir":"","eval_lpips":True} ' レンダリング速度を上げるために早期終了を有効にするために、 raymarching_tolerance 0.01にオーバーライドすることに注意してください。
モデルがトレーニングされ、レンダリング軌跡が指定されると、自由視点レンダリングを実現できます。たとえば、次のコマンドは円軌道 (角速度 3 度/フレーム、GPU あたり 15 フレーム) でレンダリングするためのものです。これにより、ビューごとにレンダリングされたイメージが出力され、次のように${SAVE}/outputでイメージが.mp4ビデオにマージされます。

デフォルトでは、コードは利用可能なすべての GPU を検出できます。
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-beam 1 --render-angular-speed 3 --render-num-frames 15
--render-save-fps 24
--render-resolution " 800x800 "
--render-path-style " circle "
--render-path-args " {'radius': 3, 'h': 2, 'axis': 'z', 't0': -2, 'r':-1} "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple "私たちのコードは、特定のカメラポーズのレンダリングもサポートしています。たとえば、次のコマンドは、フォルダー${DATASET}/poseの 200 ~ 399 番目のファイルで定義されているカメラ ポーズでレンダリングするためのものです。
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-save-fps 24
--render-resolution " 800x800 "
--render-camera-poses ${DATASET} /pose
--render-views " 200..400 "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple "このコードは、 .txtファイルで定義されたカメラ ポーズを使用したレンダリングもサポートしています。この例を参照してください。
また、トレーニングされた NSVF モデルから等値面を三角形メッシュとして抽出し、 {SAVE}/{NAME}.plyとして保存するためのマーチング キューブの実行もサポートしています。
python extract.py
--user-dir fairnr
--path ${MODEL_PATH}
--output ${SAVE}
--name ${NAME}
--format ' mc_mesh '
--mc-threshold 0.5
--mc-num-samples-per-halfvoxel 5 --format 'voxel_mesh'を設定することで、学習されたスパース ボクセルをエクスポートすることもできます。出力された.plyファイルは、MeshLab などの 3D ビューアで開くことができます。

NSVF は MIT ライセンスを取得しています。ライセンスは事前トレーニングされたモデルにも適用されます。
として引用してください
@article { liu2020neural ,
title = { Neural Sparse Voxel Fields } ,
author = { Liu, Lingjie and Gu, Jiatao and Lin, Kyaw Zaw and Chua, Tat-Seng and Theobalt, Christian } ,
journal = { NeurIPS } ,
year = { 2020 }
}

