暗号を探索しているときに、悪名高いシーザー暗号の欠陥に対する私の興味を最高に高めたカーン アカデミーのビデオを見つけました。
英語で長い手紙や電子メールを書くとき、意図せず指紋を残してしまいます。自分が書いたメッセージに目を通し、各文字の頻度を数えてみると、かなり一貫したパターンが見つかるでしょう。 「e」は、メッセージ全体で最も頻繁に出現する文字である可能性が高くなります。これをテストするためにインターネットからランダムな寓話を取り出したところ、期待どおりの結果が得られました。確かに「e」は最も人気のある文字でした。この事実は、十分な長さのメッセージに当てはまります。
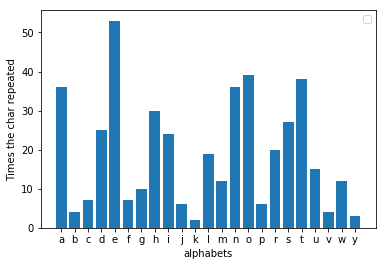
Al-kindi が発見した欠陥は、暗号化されたメッセージの頻度を分析すると、別の文字が最も頻繁に繰り返されるということでした。文字が 3 文字からどれだけずれているかを確認すると、メッセージに置換されている値がわかります。たとえば、「h」が暗号化されたメッセージ内で最も人気のある文字である場合、シフトは 3 である可能性があります。ここで、シフトを逆にすると、元のメッセージを簡単に取得できるようになります。 decoder.pyに暗号化されたファイルを与えると、メッセージが復号化されて出力されます。アルファベットを 3 文字ずらして同じ寓話を暗号化したところ、実際に「h」がここで最も人気のある文字であることがわかりました。
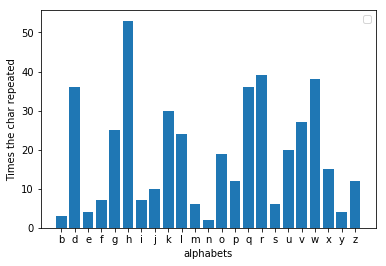
暗号の結果を再現し、他のメッセージでそれを探索するには、Python に加えて matplotlib がインストールされている必要があります。
pip install matplotlib使用してターミナルでこれを行うことができます覚えておいてください: デコーダは言語学と統計の原理に基づいて動作するため、メッセージが長くなるほど、結果がより正確になります。
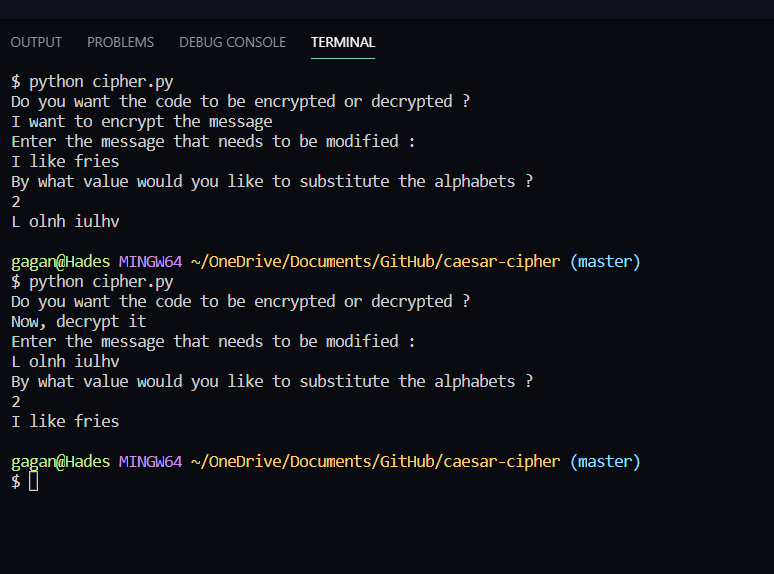
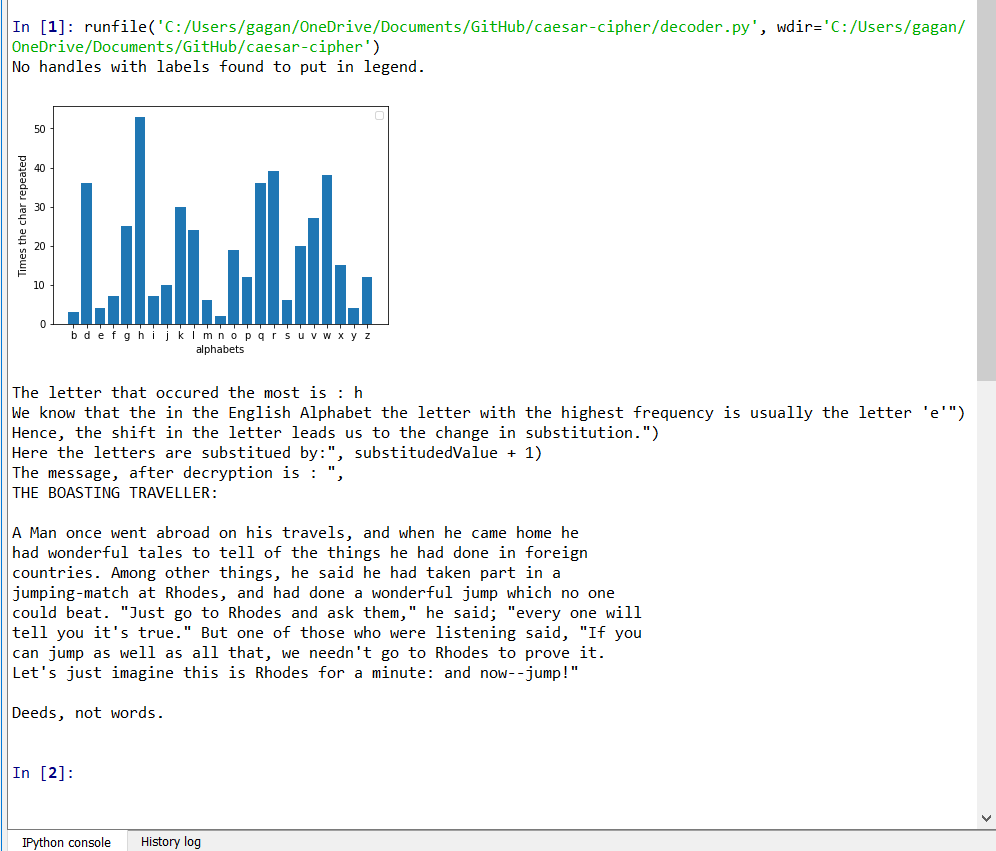
ガガン・デバギリ © MIT


