bertsearch
1.0.0
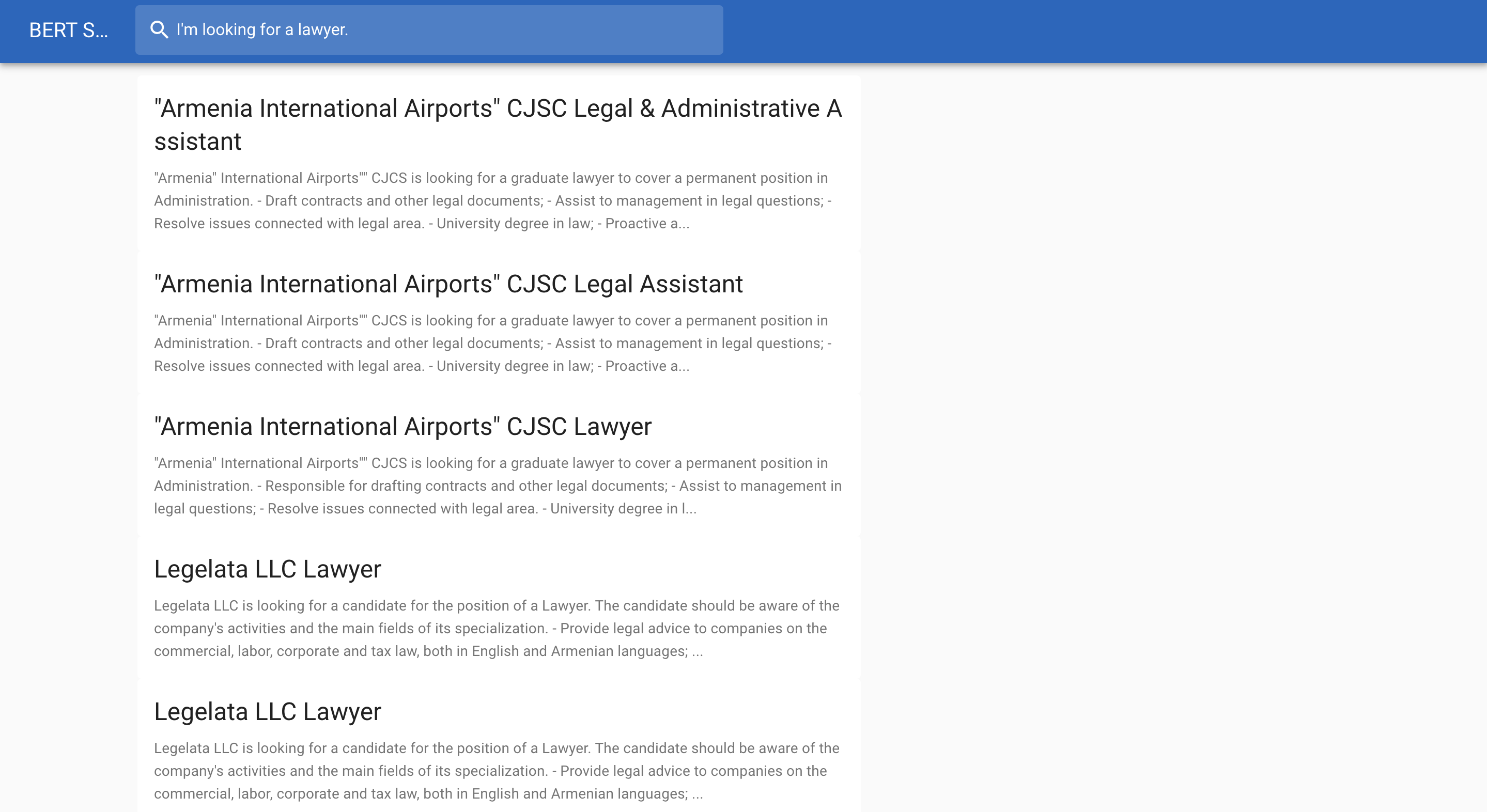
以下は求人検索の例です。
| BERT ベース、ケースなし | 12 レイヤー、768 隠し、12 ヘッド、110M パラメーター |
| BERT-Large、ケースなし | 24 レイヤー、1024 隠し、16 ヘッド、340M パラメータ |
| BERTベース、ケース入り | 12層、768個の隠し、12ヘッド、110Mパラメータ |
| BERT-Large、ケース入り | 24 レイヤー、1024 隠し、16 ヘッド、340M パラメーター |
| BERT ベース、大文字と小文字を区別した多言語 (新規) | 104 言語、12 レイヤー、768 隠し、12 ヘッド、1 億 1000 万パラメータ |
| BERT ベース、大文字と小文字を区別した多言語 (古い) | 102 言語、12 レイヤー、768 隠し、12 ヘッド、1 億 1000 万パラメータ |
| BERTベース、中国語 | 中国語簡体字および繁体字、12 層、768 隠し、12 ヘッド、110M パラメータ |
$ wget https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip
$ unzip cased_L-12_H-768_A-12.zip事前トレーニングされた BERT モデルと Elasticsearch のインデックス名を環境変数として設定する必要があります。
$ export PATH_MODEL=./cased_L-12_H-768_A-12
$ export INDEX_NAME=jobsearch$ docker-compose up注意: BERTコンテナには大量のメモリが必要となるため、可能であればDockerのメモリ構成に高いメモリ( 8GB以上)を割り当ててください。
インデックス作成 API を使用して、Elasticsearch クラスターに新しいインデックスを追加できます。インデックスを作成するときは、次を指定できます。
たとえば、 title 、 text 、 text_vectorフィールドを含むjobsearchインデックスを作成する場合は、次のコマンドでインデックスを作成できます。
$ python example/create_index.py --index_file=example/index.json --index_name=jobsearch
# index.json
{
" settings " : {
" number_of_shards " : 2,
" number_of_replicas " : 1
},
" mappings " : {
" dynamic " : " true " ,
" _source " : {
" enabled " : " true "
},
" properties " : {
" title " : {
" type " : " text "
},
" text " : {
" type " : " text "
},
" text_vector " : {
" type " : " dense_vector " ,
" dims " : 768
}
}
}
}注意: text_vectorのdims値は、事前トレーニングされた BERT モデルの dims と一致する必要があります。
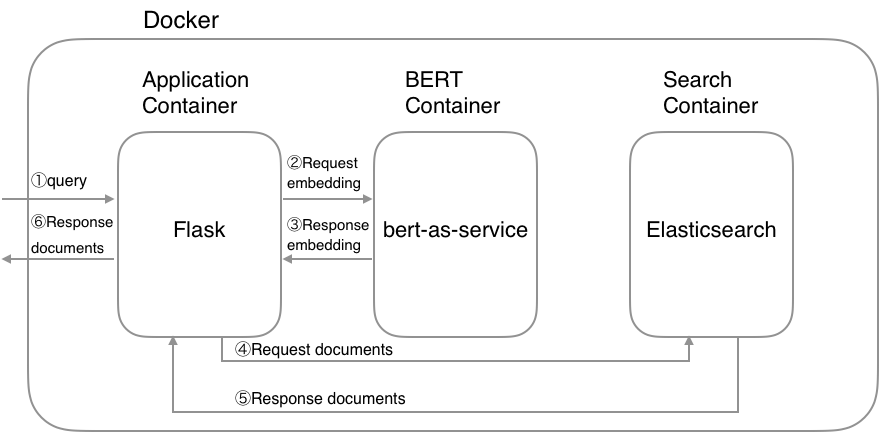
インデックスを作成したら、ドキュメントのインデックスを作成する準備が整います。ここでのポイントは、BERT を使用してドキュメントをベクトルに変換することです。結果のベクトルはtext_vectorフィールドに保存されます。データを JSON ドキュメントに変換しましょう。
$ python example/create_documents.py --data=example/example.csv --index_name=jobsearch
# example/example.csv
" Title " , " Description "
" Saleswoman " , " lorem ipsum "
" Software Developer " , " lorem ipsum "
" Chief Financial Officer " , " lorem ipsum "
" General Manager " , " lorem ipsum "
" Network Administrator " , " lorem ipsum "スクリプトが完了すると、次のような JSON ドキュメントを取得できます。
# documents.jsonl
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Saleswoman" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Software Developer" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Chief Financial Officer" , "text_vector" : [...]}
...データを JSON に変換した後、指定したインデックスに JSON ドキュメントを追加し、検索可能にすることができます。
$ python example/index_documents.pyhttp://127.0.0.1:5000 にアクセスします。


