このコードは、「画像をマップに変換する」という論文に基づいて、既存の画像から BEV への深層学習モデルに基づいて構築されました。このコードは Python 3.7 を使用して作成されました。 nuScenes データセットでトレーニングされました。インストールする依存関係とデータセットについては、リポジトリの ReadMe を参照してください。
最初のステップは、「translation-images-into-maps-main」という名前のフォルダーを作成し、そこにすべてのファイルをダウンロードすることです。ファイル サイズが大きいため、トレーニングの最新のチェックポイントと検証に使用されたミニ nuScenes データセットは、この Google ドライブからダウンロードできます。これらのフォルダーは、「translation-images-into-maps-main」ディレクトリに直接追加する必要があります。
以下は、このリポジトリに必要なライブラリのリストです。
opencv
numpy
pyquaternion
shapely
lmdb
nuscenes-devkit
pillow
matplotlib
torchvision
descartes
scipy
tensorboard
scikit-image
cv2
このリポジトリの機能を使用するには、次のコマンド ライン引数を変更する必要がある場合があります。
--name: name of the experiment
--video-name: name of the video file within the video root and without extension
--savedir: directory to save experiments to
--val-interval: number of epochs between validation runs
--root: directory of the repository
--video-root: absolute directory to the video input
--nusc-version: nuscenes version (either “v1.0-mini” or “v1.0-trainval” for the full US dataset)
--train-split: training split (either “train_mini" or “train_roddick” for the full US dataset)
--val-split: validation split (either “val_mini" or “val_roddick” for the full US dataset)
--data-size: percentage of dataset to train on
--epochs: number of epochs to train for
--batch-size: batch size
--cuda-available: environment used (0 for cpu, 1 for cuda)
--iou: iou metric used (0 for iou, 1 for diou)
モデルのトレーニングに関しては、次のコマンド ライン引数を変更できます。
--optimizer: optimizer for gradient descent to run during training. Default: adam
--lr: learning rate. Default: 5e-5
--momentum: momentum for Stochastic gradient descent. Default: 0.9
--weight-decay: weight decay. Default: 1e-4
--lr-decay: learning rate decay. Default: 0.99
NuScenes Mini および Full データセットは次の場所にあります。
NuScene ミニ:
NuScenes フル米国:
NuScene ミニ データセットとフル データセットは同じ画像入力形式 (lmdb または png) を持たないため、どちらかを使用するにはコードにいくつかの変更を適用する必要があります。
mini引数を false に変更して、 mini データセットのほか、 train.py 、 validation.py 、 inference.pyファイル内の引数パスと分割を使用します。 data = nuScenesMaps (
root = args . root ,
split = args . val_split ,
grid_size = args . grid_size ,
grid_res = args . grid_res ,
classes = args . load_classes_nusc ,
dataset_size = args . data_size ,
desired_image_size = args . desired_image_size ,
mini = True ,
gt_out_size = ( 200 , 200 ),
)
loader = DataLoader (
data ,
batch_size = args . batch_size ,
shuffle = False ,
num_workers = 0 ,
collate_fn = src . data . collate_funcs . collate_nusc_s ,
drop_last = True ,
pin_memory = True
)data_loader.py関数の 151 ~ 153 行目または 146 ~ 149 行目をコメント化/コメント解除します。 # if mini:
image_input_key = pickle . dumps ( id , protocol = 3 )
with self . images_db . begin () as txn :
value = txn . get ( key = image_input_key )
image = Image . open ( io . BytesIO ( value )). convert ( mode = 'RGB' )
# else:
# original_nusenes_dir = "/work/scitas-share/datasets/Vita/civil-459/NuScenes_full/US/samples/CAM_FRONT"
# new_cam_path = os.path.join(original_nusenes_dir, Path(cam_path).name)
# image = Image.open(new_cam_path).convert(mode='RGB')事前トレーニングされたチェックポイントは次の場所にあります。
チェックポイントは、このリポジトリのルート ディレクトリから/pretrained_models/27_04_23_11_08内に保持する必要があります。別のディレクトリからロードしたい場合は、次の引数を変更してください。
- - savedir = "pretrained_models" # Careful, this path is relative in validation.py but global in train.py
- - name = "27_04_23_11_08"scitas でトレーニングするには、ルート ディレクトリから次のスクリプトを起動する必要があります。
sbatch job.script.sh
CPU でローカルにトレーニングするには:
python3 train.py
必ずコマンド ライン引数を使用してスクリプトを調整してください。
scitas でモデルのパフォーマンスを検証するには:
sbatch job.validate.sh
CPU でローカルにトレーニングするには:
python3 validate.py
必ずコマンド ライン引数を使用してスクリプトを調整してください。
scitas のビデオを推測するには:
sbatch job.evaluate.sh
CPU でローカルにトレーニングするには:
python3 inference.py
特に次のように、コマンド ライン引数を使用してスクリプトを調整してください。
--batch-size // 1 for the test videos
--video-name
--video-root
このプロジェクトは、EPFL の Alexandre Alahi 教授が指導する自動運転車のための深層学習コース CIVIL-459 のコンテキストで作成されました。博士課程学生のYuejiang Liu氏に監修していただきました。このコースのプロジェクトの主な目標は、Tesla 自動操縦システムで使用できる深層学習モデルを開発することです。私たちのグループでは、単眼カメラの映像から鳥瞰図への変換を検討してきました。これは、セマンティック セグメンテーションを使用して、車、歩道、歩行者、地平線などの要素を分類することで実行できます。
BEV 深層学習モデルに対する単眼画像の研究中に、歩行者に関する情報がセグメンテーション中に失われ、その結果、分類が不十分になることに気づきました。以下の画像に見られるように、評価すると、選択したモデルは、nuScenes データセット上の 14 クラスのオブジェクトにわたって平均 25.7% の IoU (結合に対する交差) に達しました。運転可能な車両の予測精度は良好 (74.5%) ですが、自転車、バリア、トレーラーの予測精度は非常に低くなっています。しかし、歩行者の予測精度 (9.5%) は低すぎます。このように精度が低いと、誰かが横断歩道を渡らずに道路を横断した場合に事故が発生する可能性があります。

私たちの研究の詳細については、ドライブでご覧ください。
現在のトレーニング済みモデルでは歩行者の検出が不十分であることが最も差し迫った問題であると思われるため、より適切な損失関数を検討し、nuScenes データセットで新しいモデルをトレーニングすることで精度を向上させることを目指しました。
私たちが構築したモデルは、
別の問題
の
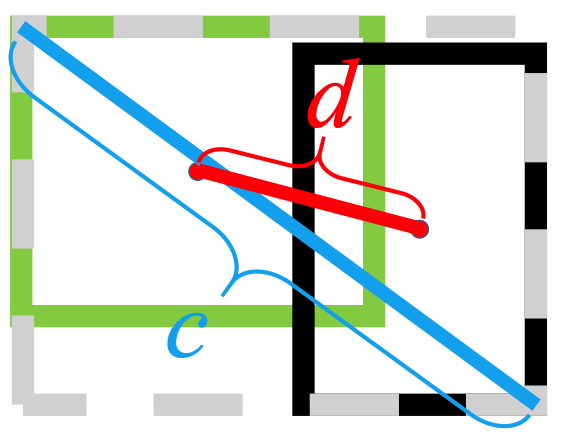
L2 ノルムを使用して予測ボックスとターゲット ボックス間の距離を最小限に抑え、より高速に収束します。

水平方向のストレッチ

垂直方向のストレッチ
さらに、DIoU 損失により、スムーズな収束を促進する正則化項が導入されます。
次の画像からわかるように、
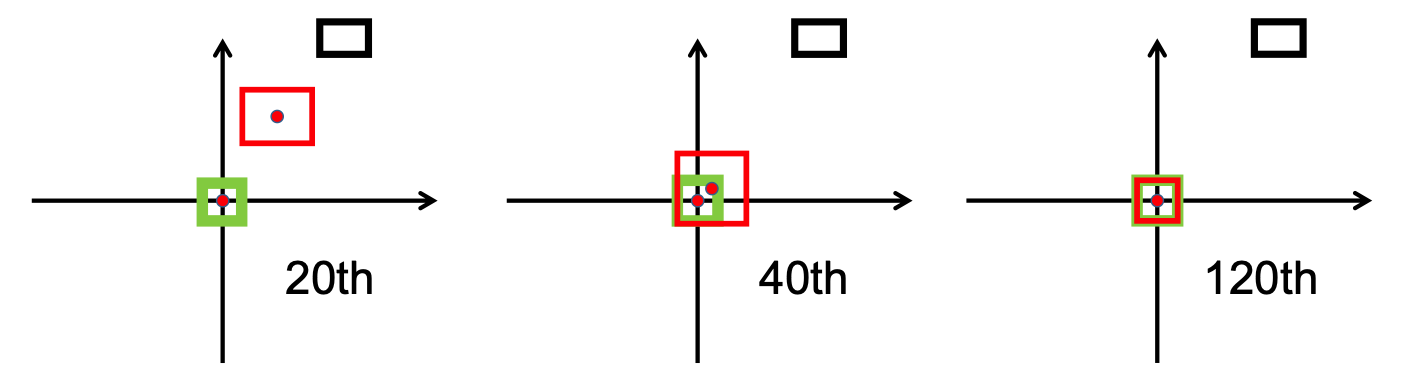
研究段階の後、私たちは以下を実装しました。 /src/utils.pyファイル内のbbox_overlaps_diou関数での損失。
この関数はマルチスケールを計算するために使用されます。 compute_multiscale_iou関数内。クラスごとに、 iou入力引数の関数で) バッチ サイズに基づいて計算されます。関数の出力は、マルチスケールを含む辞書iou_dictです。
次に、これらの値をtrain.pyで使用しました。 val-intervalエポックごとに 1 回の評価実行で使用されました。これらの値は、損失と損失を表示するために使用されたvalidation.pyでも使用されました。
NuScenes データセットでモデルをトレーニングしました。提供されたチェックポイントcheckpoint-008.pth.gzから始めて、
もう 1 つの貢献は、対応するすべてのラベルと IoU 値を使用してクラスをより適切に区別するための新しい視覚化形式です。これは、 visualization.pyファイルに実装されました。
最後に、 .mp4ビデオを入力として受け取り、それらを個々の画像フレームに分解するモードの実装に取り組みました。これらはモデルによって評価され、 inference.pyファイル内のセグメンテーション結果を視覚化できます。
このモデルのトレーニング戦略について予備的なアイデアを得るために、まず NuScenes ミニ データセットでモデルをトレーニングすることにしました。 checkpoint-008.pth.gzから開始して、使用される IoU メトリクスが異なる 2 つのモデル (1 つは IoU、もう 1 つは DIoU) をトレーニングできました。 10 エポックのトレーニング後に NuScenes ミニバッチで得られた結果を以下の表に示します。

これらの結果を確認したところ、私たちが仮説に基づいた歩行者クラスが決定的な結果をまったく示さないことがわかりました。したがって、ミニデータセットではニーズを満たしていないと結論付け、トレーニングを Scitas 上の完全なデータセットに移行することにしました。
8 つの新しいエポックに対して、 checkpoint-008.pth.gzから新しいモデル (DIoU または IoU を使用) をトレーニングした後、有望な結果が観察されました。これらの新しくトレーニングされたモデルのパフォーマンスを比較することを目的として、ミニ データセットに対して検証ステップを実行しました。このデータセットの画像の結果を視覚化したものを以下に示します。
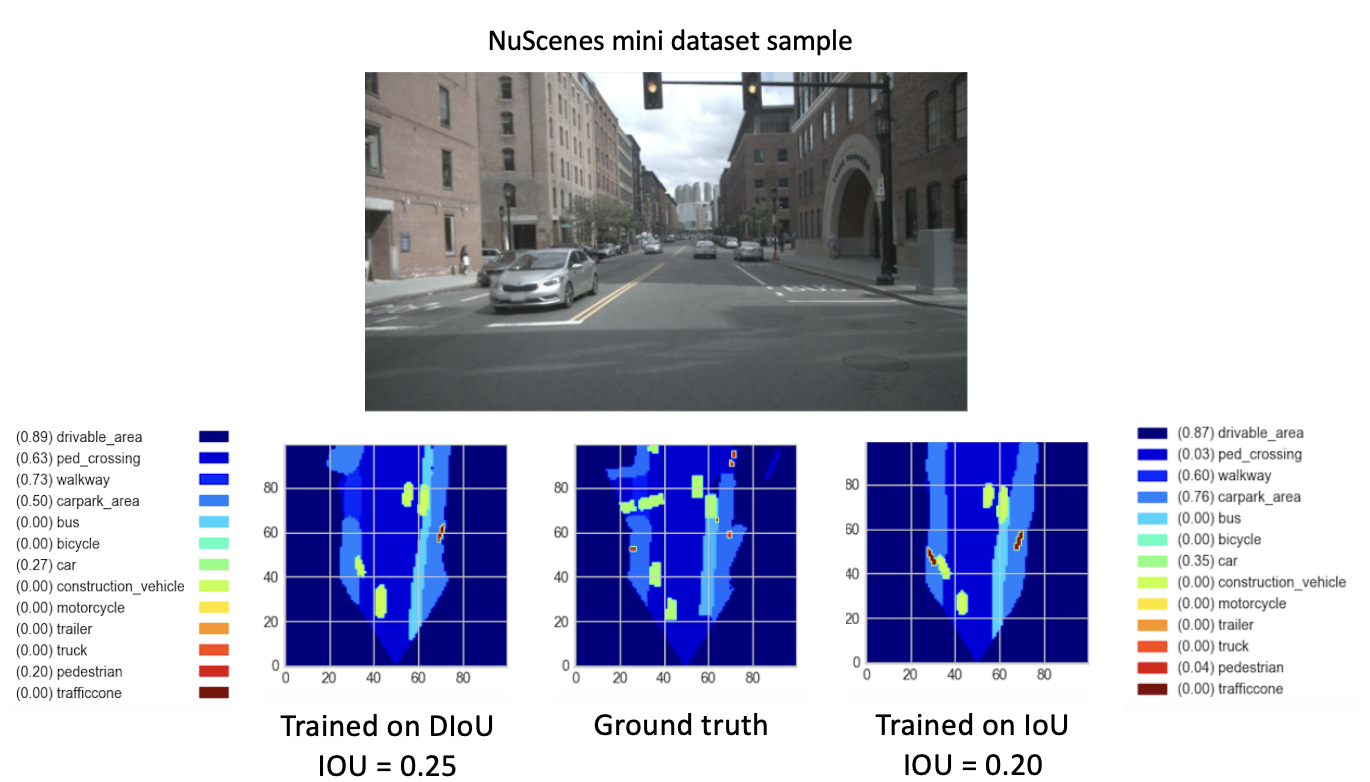
ここで、

これらの結果は最終的に、
トレーニングされたモデルが完成したので、それを使用して、入力画像またはビデオを使用して BEV を予測できます。私たちの目標は、コースの最終デモ内でメソッドを実装することでしたが、残念ながら、推論された鳥瞰図マップのパフォーマンスは十分ではありませんでした。以下の図は、提供されているテスト ビデオの 1 つでの推論結果を示しています (テスト ビデオを参照)。

この推論のパフォーマンスの欠如は、次のパラメータが原因であると考えられます。
からの一節ですが、
1 つのオプションは、実装することです
の
さらに、この論文 [2] によって行われた研究によると、CIoU の回帰誤差は他のものよりも早く劣化し、次のように収束します。
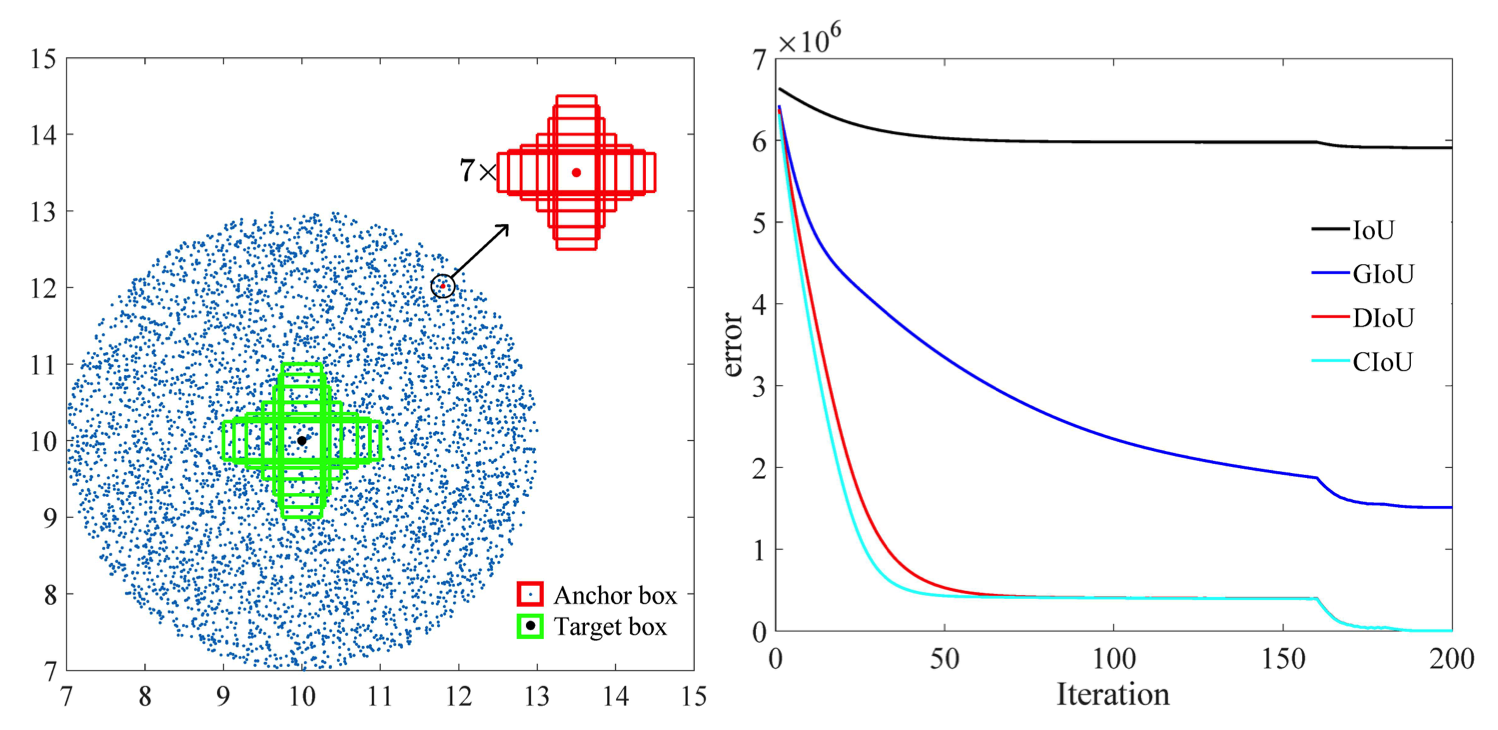
もう 1 つのオプションは、歩行者と自転車をより適切に表現するために、混雑した環境が豊富なデータセットでトレーニングすることです。
最後に、仮説を真に検証するために、NuScenes データセット全体で検証を実行し、2 つのモデルの歩行者 IoU を比較できます。
[1] Zhaohui Zheng、Ping Wang、Wei Liu、Jinze Li、Rongguang Ye、Dongwei Ren (2020)。距離 IoU 損失: 境界ボックス回帰のより高速かつ優れた学習 https://arxiv.org/pdf/1911.08287.pdf
[2] Zhaohui Zheng、Ping Wang、Dongwei Ren、Wei Liu、Rongguang Ye、Qinghua Hu、Wangmeng Zuo (2021)。オブジェクト検出とインスタンスのセグメンテーションのためのモデルの学習と推論における幾何学的要素の強化 https://arxiv.org/pdf/2005.03572.pdf


