EasyOCR
v1.7.2
サポートされている 80 を超える言語と、ラテン語、中国語、アラビア語、デヴァナーガリー文字、キリル文字などを含むすべての一般的な筆記体を備えたすぐに使える OCR。
弊社ウェブサイトでデモをお試しください
ハギングフェイススペースに統合?グラディオを使って。 Web デモを試してください。
2024 年 9 月 24 日 - バージョン 1.7.2
リリースノートをすべて読む



pip使用してインストールする
最新の安定リリースの場合:
pip install easyocr最新の開発リリースの場合:
pip install git+https://github.com/JaidedAI/EasyOCR.git注 1: Windows の場合は、https://pytorch.org の公式手順に従って、まず torch と torchvision をインストールしてください。 pytorch Web サイトで、必ず適切な CUDA バージョンを選択してください。 CPU モードのみで実行する場合は、 CUDA = Noneを選択します。
注 2: ここでは Dockerfile も提供します。
import easyocr
reader = easyocr . Reader ([ 'ch_sim' , 'en' ]) # this needs to run only once to load the model into memory
result = reader . readtext ( 'chinese.jpg' )出力はリスト形式で、各項目は境界ボックス、検出されたテキスト、信頼レベルをそれぞれ表します。
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路' , 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西' , 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东' , 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], ' 315 ' , 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], ' 309 ' , 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], ' Yuyuan Rd. ' , 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], ' W ' , 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], ' E ' , 0.8405593633651733)]注 1: ['ch_sim','en']読み取りたい言語のリストです。一度に複数の言語を渡すことができますが、すべての言語を一緒に使用できるわけではありません。英語はあらゆる言語と互換性があり、共通の文字を共有する言語は通常、相互に互換性があります。
注 2: ファイルパスchinese.jpgの代わりに、OpenCV 画像オブジェクト (numpy 配列) または画像ファイルをバイトとして渡すこともできます。 RAW 画像への URL も使用できます。
注 3: 行reader = easyocr.Reader(['ch_sim','en'])モデルをメモリにロードするためのものです。多少時間がかかりますが、実行するのは 1 回だけです。
出力を単純化するために、 detail=0を設定することもできます。
reader . readtext ( 'chinese.jpg' , detail = 0 )結果:
[ '愚园路' , '西' , '东' , ' 315 ' , ' 309 ' , ' Yuyuan Rd. ' , ' W ' , ' E ' ]選択した言語のモデルの重みは自動的にダウンロードされます。または、モデル ハブから手動でダウンロードして「~/.EasyOCR/model」フォルダーに置くこともできます。
GPU がない場合、または GPU のメモリが少ない場合は、 gpu=False追加することでモデルを CPU 専用モードで実行できます。
reader = easyocr . Reader ([ 'ch_sim' , 'en' ], gpu = False )詳細については、チュートリアルと API ドキュメントを参照してください。
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=True認識モデルについては、こちらをお読みください。
検出モデル(CRAFT)についてはこちらをお読みください。
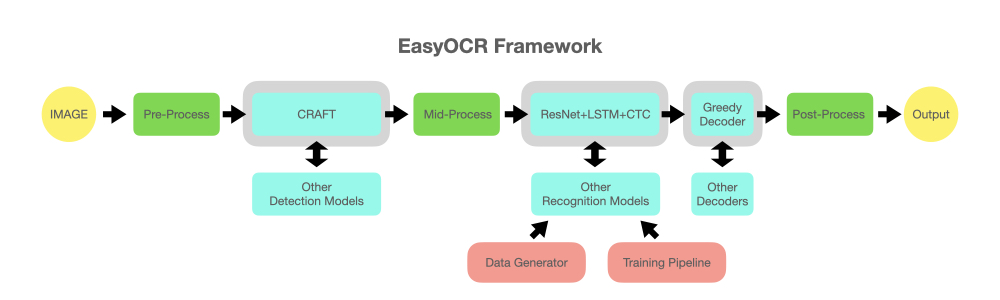
reader = easyocr . Reader ([ 'en' ], detection = 'DB' , recognition = 'Transformer' )アイデアは、あらゆる最先端のモデルを EasyOCR に接続できるようにすることです。より良い検出/認識モデルを作成しようとしている天才はたくさんいますが、私たちはここで天才になろうとしているわけではありません。私たちはただ、彼らの作品を無料ですぐに一般に公開したいと考えています。 (そうですね、ほとんどの天才は自分の仕事ができるだけ早く/大きなプラスの影響を生み出すことを望んでいると思います) パイプラインは以下の図のようになるはずです。灰色のスロットは、変更可能な水色のモジュールのプレースホルダーです。
このプロジェクトは、いくつかの論文とオープンソース リポジトリからの調査とコードに基づいています。
すべての深層学習の実行は Pytorch に基づいています。 ❤️
検出の実行には、この公式リポジトリとその論文の CRAFT アルゴリズムが使用されます (@clovaai の @YoungminBaek に感謝します)。また、事前トレーニングされたモデルも使用します。トレーニング スクリプトは @gmuffiness によって提供されます。
認識モデルはCRNN(論文)です。これは、特徴抽出 (現在 Resnet を使用しています) と VGG、シーケンス ラベリング (LSTM)、およびデコード (CTC) の 3 つの主要コンポーネントで構成されています。認識実行用のトレーニング パイプラインは、ディープテキスト認識ベンチマーク フレームワークの修正バージョンです。 (@clovaai の @ku21fan に感謝) このリポジトリは、もっと評価されるべき逸品です。
Beam 検索コードは、このリポジトリと彼のブログに基づいています。 (@githubharald に感謝)
データ合成は TextRecognitionDataGenerator に基づいています。 (@Belval に感謝)
ここの distill.pub から CTC についてよく読んでください。
AI を誰もが利用できるようにすることで、一緒に人類を進歩させましょう!
貢献するには 3 つの方法:
コード作成者:小さなバグや改善については PR を送信してください。より大きな問題については、まず問題を開いてご相談ください。 「PR WELCOME」のタグが付いた、考えられるバグ/改善の問題のリストがあります。
ユーザー: EasyOCR があなた/あなたの組織にさらなる開発を促す上でどのようなメリットがあるかを教えてください。また、問題セクションに失敗例を投稿して、将来のモデルの改善に役立ててください。
技術リーダー/第一人者:このライブラリが役立つと思われた場合は、ぜひ広めてください。 (EasyOCR に関する Yann Lecun の投稿を参照してください)
新しい言語をリクエストするには、次の 2 つのファイルを含む PR を送信する必要があります。
あなたの言語に独自の要素がある場合 (1. アラビア語: 文字は互いに結合すると形が変わる + 右から左に書く 2. タイ語: 一部の文字は線の上に、一部の文字は下にある必要がある)あなたの能力を評価したり、役立つリンクを提供したりします。本当に機能するシステムを実現するには、細部にまで気を配ることが重要です。
最後に、人気のある言語、または相互に文字の大部分を共有する言語セットを優先する必要があることをご理解ください (あなたの言語がこれに該当するかどうかもお知らせください)。新しいモデルの開発には少なくとも1週間かかりますので、新しいモデルのリリースまでしばらくお待ちいただく場合があります。
開発中の言語のリストを参照
リソースが限られているため、6 か月以上経過した問題は自動的にクローズされます。重要な場合は、もう一度問題を開いてください。
エンタープライズ サポートの場合、Jaided AI はカスタム OCR/AI システムの実装、トレーニング/微調整、導入に至るまでのフル サービスを提供します。お問い合わせはここをクリックしてください。


