nmt
1.0.0
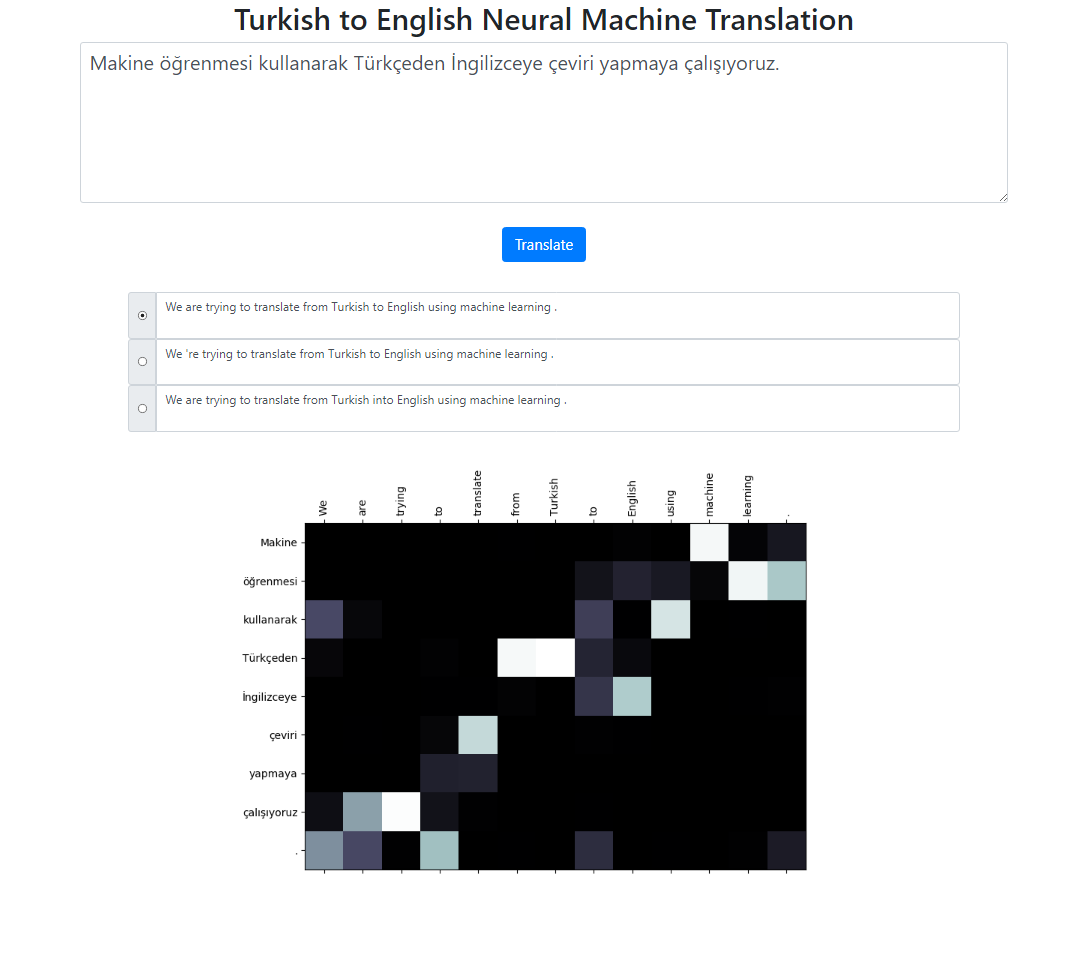
このリポジトリは、Seq2Seq + Global Attend モデルを使用してトルコ語から英語へのニューラル機械翻訳システムを実装します。ローカルで実行できる Flask アプリケーションもあります。テキストを入力し、翻訳し、結果と注意の視覚化を検査することができます。バックグラウンドでビーム サイズ 3 でビーム検索を実行し、相対スコアによってソートされた最も可能性の高いシーケンスを返します。
このプロジェクトのデータセットはここから取得されています。私はタトエバコーパスを使用しました。データ内で見つかった重複の一部を削除しました。データセットも事前にトークン化しました。最終バージョンはデータフォルダーにあります。
トルコ語の文をトークン化するために、nltk の RegexpTokenizer を使用しました。
puncts_Except_apostrophe = '!"#$%&()*+,-./:;<=>?@[]^_`{|}~'TOKENIZE_PATTERN = fr"[{puncts_例外_アポストロフィ}]|w+|['w ]+"regex_tokenizer = RegexpTokenizer(pattern=TOKENIZE_PATTERN)text = "タイタニック15 Nisan pazartesi saat 02:20'de buttı."tokenized_text = regex_tokenizer.tokenize(text)print(" ".join(tokenized_text))# 出力: Titanic 15 Nisan pazartesi saat 02 : 20 'de buttı .# この分割プロパティは「02:20」は英語とは異なりますtokenizer.# これらの状況には対処できますが、単純にして、 # これらの単語に対する注意の分布が英語のトークンと一致するかどうかを確認したいと思いました。# この例のように、主に日付にも同様のケースがあります。 /2019英語の文章のトークン化には、spacy の英語モデルを使用しました。
en_nlp = spacy.load('en_core_web_sm')text = "タイタニック号は 4 月 15 日月曜日の 02:20 に沈没しました。"tokenized_text = en_nlp.tokenizer(text)print(" ".join([tok.text for tok in tokenized_text ]))# 出力: タイタニック号は 4 月 15 日月曜日の 02:20 に沈没しました。トルコ語と英語の文章は 2 つの異なるファイルに含まれることが予想されます。
file: train.tr tr_sent_1 tr_sent_2 tr_sent_3 ... file: train.en en_sent_1 en_sent_2 en_sent_3 ...
引数の完全なリストを表示するには、 python train.py -h実行してください。
Sample usage: python train.py --train_data train.tr train.en --valid_data valid.tr valid.en --n_epochs 30 --batch_size 32 --embedding_dim 256 --hidden_size 256 --num_layers 2 --bidirectional --dropout_p 0.3 --device cuda
コーパスレベルのブルースコアを計算します。
usage: test.py [-h] --model_file MODEL_FILE --valid_data VALID_DATA [VALID_DATA ...] Neural Machine Translation Testing optional arguments: -h, --help show this help message and exit --model_file MODEL_FILE Model File --valid_data VALID_DATA [VALID_DATA ...] Validation_data Sample Usage: python test.py --model_file model.bin --validation_data valid.tr valid.en
アプリケーションをローカルで実行するには、次を実行します。
python app.py
config.pyファイル内のモデル パスが正しく定義されていることを確認してください。
モデルファイル
語彙ファイル
サブワード単位の使用 (トルコ語と英語の両方)
さまざまな注意メカニズム (注意のためのさまざまなパラメータを学習)
このプロジェクトのスケルトン コードは、スタンフォード大学の NLP コース: CS224n から取得されています。


