LVBench
1.0.0
[プロジェクトページ] [arXiv Paper] [データセット][?リーダーボード][?ハグフェイス リーダーボード]
LVBench は、最長 2 時間の長いビデオから情報を理解して抽出するマルチモーダル モデルの機能を評価および強化するように設計されたベンチマークです。
2024.08.2 Huggingface Spaces に LVBench Leaderboard を設置しました。リーダーボードをチェックしてください。
2024.06.11長時間動画理解のための新しいベンチマーク LVBench をリリースしました!
LVBench は、長いビデオを理解する際のモデルの機能を評価するために設計されたベンチマークです。私たちは公開ソースから広範な長いビデオ データを収集し、手作業とモデル支援を組み合わせて注釈を付けました。当社のベンチマークは、拡張された時間的コンテキストでモデルをテストするための堅牢な基盤を提供し、細心の注意を払った人間によるアノテーションと多段階の品質管理を通じて高品質の評価を保証します。
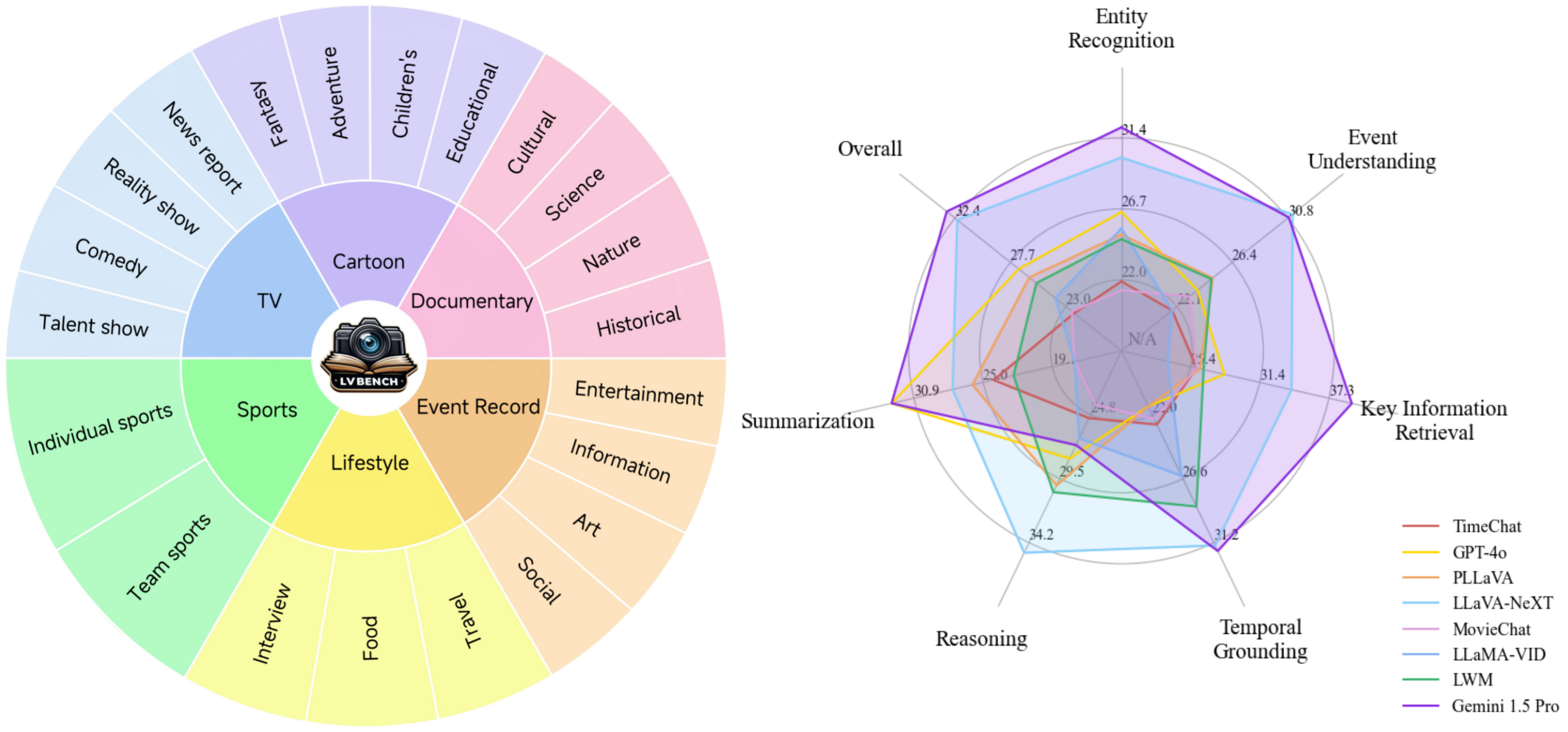
コア機能: 長いビデオを理解するための 6 つのコア機能により、包括的なモデル評価のための複雑で挑戦的な質問の作成が可能になります。
多様なデータ: 既存の最長データセットの平均 5 倍の長さを誇る多様な長いビデオ データで、さまざまなカテゴリをカバーしています。
高品質のアノテーション: 綿密な人間によるアノテーションと多段階の品質管理プロセスによる信頼性の高いベンチマーク。

私たちのデータセットは CC-BY-NC-SA-4.0 ライセンスの下にあります。
LVBench は学術研究のみに使用されます。いかなる形式であっても商用利用は禁止されています。当社は生のビデオファイルの著作権を所有しません。
LVBench に侵害がある場合は、[email protected] にご連絡いただくか、直接問題を提起してください。すぐに削除します。
最初に video2dataset をインストールします。
pip インストール video2dataset pip アンインストール トランス エンジン
次に、Huggingface からvideo_info.meta.jsonlをダウンロードし、 dataディレクトリに配置する必要があります。
video_info.meta.jsonlファイルの各エントリには、YouTube ビデオの ID に対応するキー フィールドがあります。ユーザーはこの ID を使用して、対応するビデオをダウンロードできます。あるいは、ユーザーは、当社が提供するダウンロード スクリプト download.sh を使用してダウンロードすることもできます。
CD スクリプト bash ダウンロード.sh
実行後、ビデオ ファイルはscript/videosディレクトリに保存されます。
pip install -e 。
(注: 評価をすぐに試したい場合は、 scripts/construct_random_answers.py使用してランダムな応答ファイルを準備できます。)
CD スクリプト Python test_acc.py
実行後、評価結果ファイルresult.jsonがscriptsディレクトリに取得されます。結果をリーダーボードに送信できます。
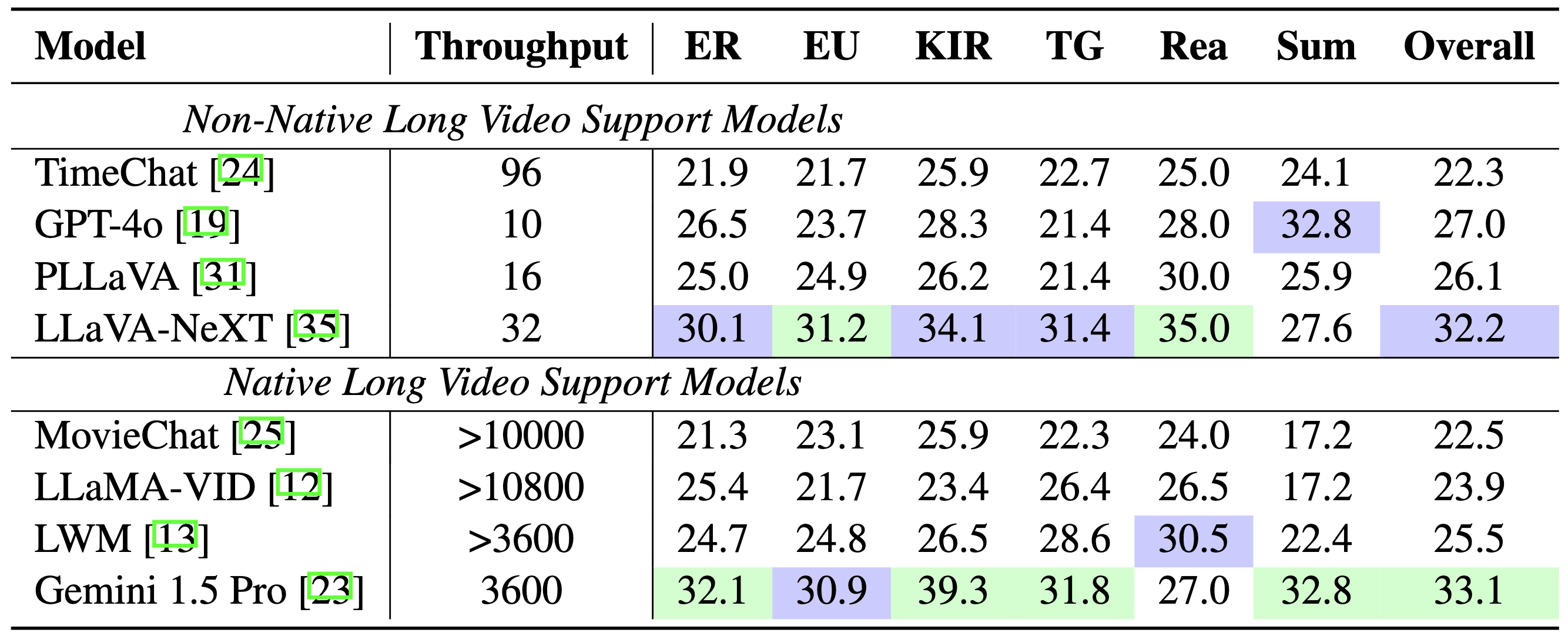
モデルの比較:
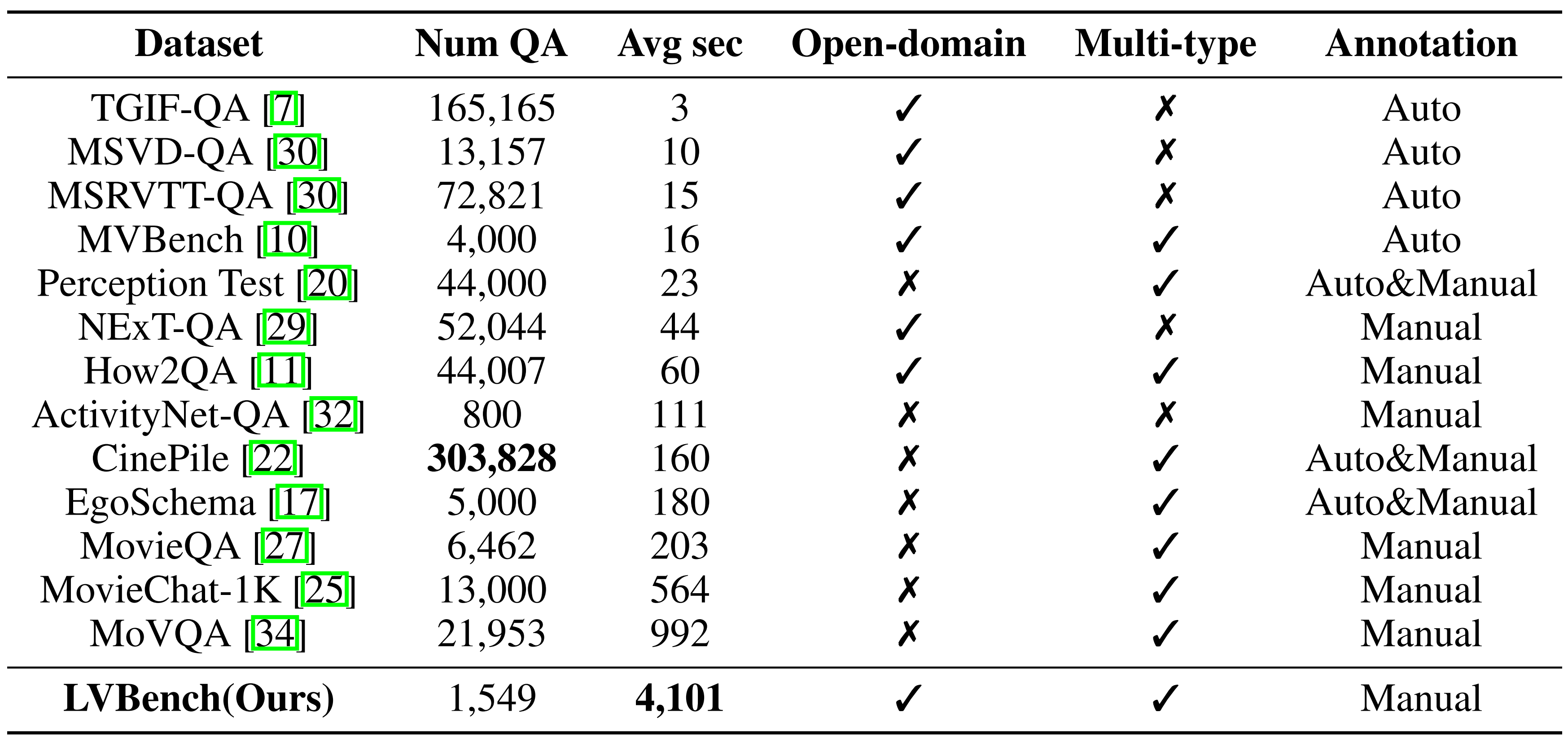
ベンチマークの比較:
モデル vs 人間:

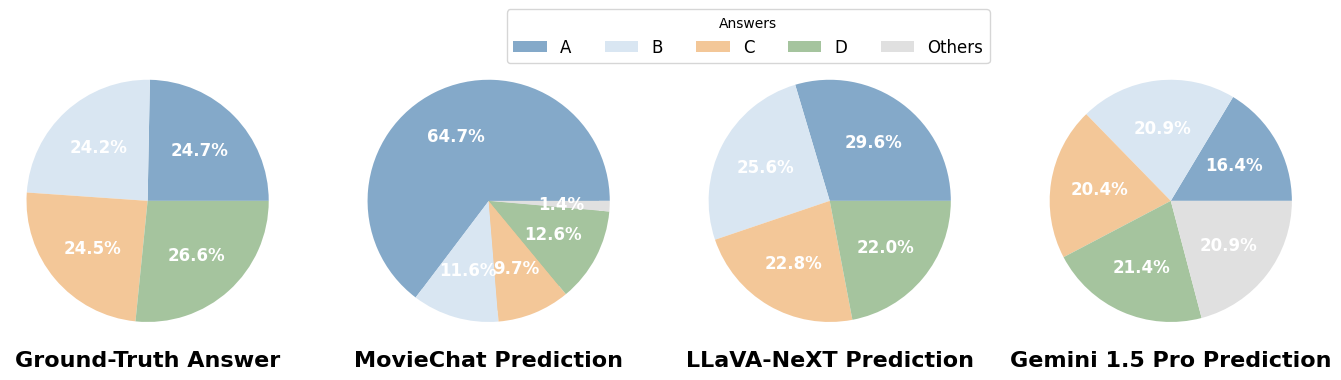
回答の配布:
私たちの研究があなたの研究に役立つと思われる場合は、私たちの研究を引用することを検討してください。
@misc{wang2024lvbench, title={LVBench: 非常に長いビデオを理解するためのベンチマーク},
author={ウェイハン・ワン、ゼハイ・ヘ、ウェンイー・ホン、イェン・チェン、シャオハン・チャン、ジー・チー、シーユー・ファン、ビン・シュウ、ユーシャオ・ドン、ミン・ディン、ジエ・タン}、年={2024}、eprint={2406.08035}、archivePrefix ={arXiv}、primaryClass={cs.CV}} 

