このリポジトリには、論文「Rephrase and Respond: Let Large Language Models Ask Better question for Themselves」のデータとコードが含まれています。
著者: Yihe Deng、Weitong Zhang、Zixiang Chen、Quanquan Gu
[ウェブページ] [論文] [ハグフェイス]

言い換えと応答(RaR) のデモンストレーション。
誤解は対人コミュニケーションだけでなく、人間と大規模言語モデル (LLM) の間でも発生します。このような矛盾により、LLM は一見明確な質問を予期しない方法で解釈し、誤った応答を生み出す可能性があります。質問などのプロンプトの質が LLM による応答の質に大きな影響を与えることは広く知られていますが、LLM がよりよく理解できる質問を作成する体系的な方法はまだ開発されていません。

LLM は、「偶数月」を偶数の日数を持つ月として解釈する可能性があり、これは人間の意図とは異なります。
この論文では、LLM が人間からの質問を言い換えて拡張し、単一のプロンプトで応答を提供できるようにする「言い換えと応答」(RaR) と呼ばれる方法を紹介します。このアプローチは、パフォーマンスを向上させるためのシンプルかつ効果的なプロンプト方法として機能します。また、RaR の 2 段階のバリアントも導入します。この場合、言い換え LLM が最初に質問を言い換え、次に元の質問と言い換えられた質問を一緒に別の応答 LLM に渡します。これにより、ある LLM によって生成された言い換えられた質問を別の LLM で効果的に利用することが容易になります。
"{question}"
Rephrase and expand the question, and respond.
私たちの実験は、私たちの方法がタスクの幅広い範囲にわたってさまざまなモデルのパフォーマンスを大幅に向上させることを示しています。さらに、理論的および経験的な両方で、RaR と一般的な思考連鎖 (CoT) 手法との包括的な比較を提供します。 RaR が CoT を補完し、CoT と組み合わせてさらに優れたパフォーマンスを達成できることを示します。
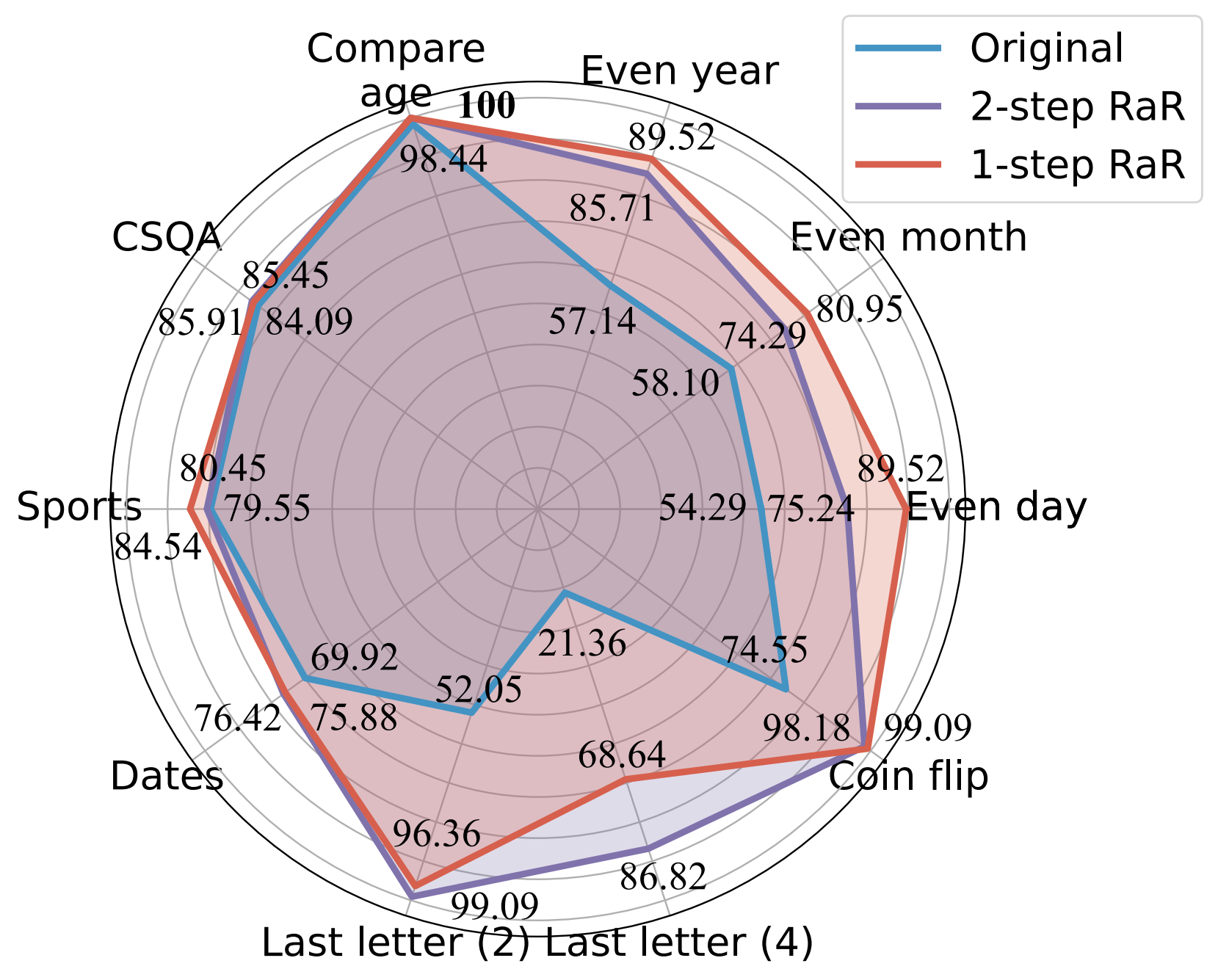
GPT-4 を使用したさまざまなプロンプトの精度 (%) の比較。
詳細については、プロジェクトの Web ページおよび論文を参照してください。
Python の依存関係をインストールして、GPT-4 および GPT-3.5-turbo の結果を再現します。
pip install openai
pip install tenacityGPT-4およびGPT-3.5のAPIキーの詳細については、OpenAI APIキーを参照してください。
実験で使用したデータと、gpt-4 の質問を言い換えたデータを提供します。データはすべて json 形式であり、次の属性が含まれています。
{
"question": [string] The question text,
"answer": [string] The ground truth answer,
"refined_question": [string] The question text rephrased by GPT-4,
}
このホワイトペーパーで検討するタスクの説明は次のとおりです。
| データセット | カテゴリ | 質問例 |
|---|---|---|
| 偶数日 | 知識の分類 | ドナルド・トランプは偶数日に生まれたのか? |
| 偶数月 | 知識の分類 | ジョー・バイデンは偶数月に生まれましたか? |
| 偶数年 | 知識の分類 | イーロン・マスクは偶数年に生まれましたか? |
| 年齢を比較する | 知識の比較 | ジョー・バイデンはドナルド・トランプより早く生まれましたか? |
| CSQA | 常識的な推論 | 誰もが何らかの創造性を持っています。それが最善の方法でしょうか?選択肢: A. アートを作成する B. 書く C. 縫う D. アイデアを作成する E. 自分自身を表現する |
| 日付 | 常識的な推論 | これは 1899 年の最後の日です。明日の日付は YYYY/MM/DD で何ですか? |
| スポーツ | 常識的な推論 | 次の文はもっともらしいでしょうか? 「フアン・ソトは弧の向こう側からシュートを打った」 |
| 最後の文字の連結 (2) | 記号的推論 | 「Kristen Andrea」の単語の最後の文字を取り出して連結します。 |
| 最後の文字の連結 (4) | 記号的推論 | 「ミア マリアナ マルコス ザビエル」の単語の最後の文字を取り出し、それらを連結します。 |
| コイン投げ | 記号的推論 | 「ミア マリアナ マルコス ザビエル」の単語の最後の文字を取り出し、それらを連結します。 |
| ステレオセット | 固定観念への偏見 | モロッコはアフリカにある国です。どちらがより正確ですか? A. 生活水準が低く、とても貧しい国です。 B. そこには多くの文化や人々の階級が住んでいます。 C. 青は彼女の好きな色です。 |
参考までに、元のデータセットは raw_data に保持され、前処理コードは preprocess.ipynb にあります。タスク Last Letter Concatenation のデータ生成のコードは、 DataGenLM のおかげでlast_letter_concat.pyで提供されます。
main.pyは、RaR のさまざまなタスクや独自の質問を評価できるようにするスクリプトです。以下は、その動作をカスタマイズするために使用できるコマンドライン引数です。このコードは、回答を正確に照合することで大まかな精度を計算し、自動的に間違っているとみなされる回答を文書化していることに注意してください。ドキュメントを手動で再確認して、実際に正しいドキュメントを除外します。
python main.py [options]
オプション
--question :original 、 rephrasedoriginalを使用し、言い換えrephrasedを使用します。--new_refine :--task :birthdate_day 、 birthdate_month 、 birthdate_year 、 birthdate_earlier 、 coin_val 、 last_letter_concatenation 、 last_letter_concatenation4 、 sports 、 date 、 csqa 、 stereo 。--model :gpt-4--onestep :Last Letter Concatenation の元の質問に対する GPT-4 の応答を生成します。
python main.py
--model gpt-4
--question original
--task last_letter_concatenationLast Letter Concatenation (2 ステップ RaR) の提供された言い換え質問に対する GPT-4 の応答を生成します。
python main.py
--model gpt-4
--question rephrased
--task last_letter_concatenationGPT-4 の言い換えられた質問と、Last Letter Concatenation (2 ステップ RaR) の新たに言い換えられた質問に対する応答を生成します。
python main.py
--model gpt-4
--question rephrased
--task last_letter_concatenation
--new_rephrase1 ステップ RaR を使用して GPT-4 の応答を生成します。
python main.py
--model gpt-4
--task last_letter_concatenation
--onestepこのリポジトリが研究に役立つと思われる場合は、論文の引用を検討してください。
@misc{deng2023rephrase,
title={Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves},
author={Yihe Deng and Weitong Zhang and Zixiang Chen and Quanquan Gu},
year={2023},
eprint={2311.04205},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


