ヤン・ゾウ、ジョンホン・チョン、ラサ・ペムラ、ドンチン・チャン、オンカー・ダビール。
このリポジトリには、ECCV-2022 論文「異常検出とセグメンテーションのための SPot-the-Difference Self-Supervised Pre-training」のリソースが含まれています。現在、Visual Anomaly (VisA) データセットをリリースしています。
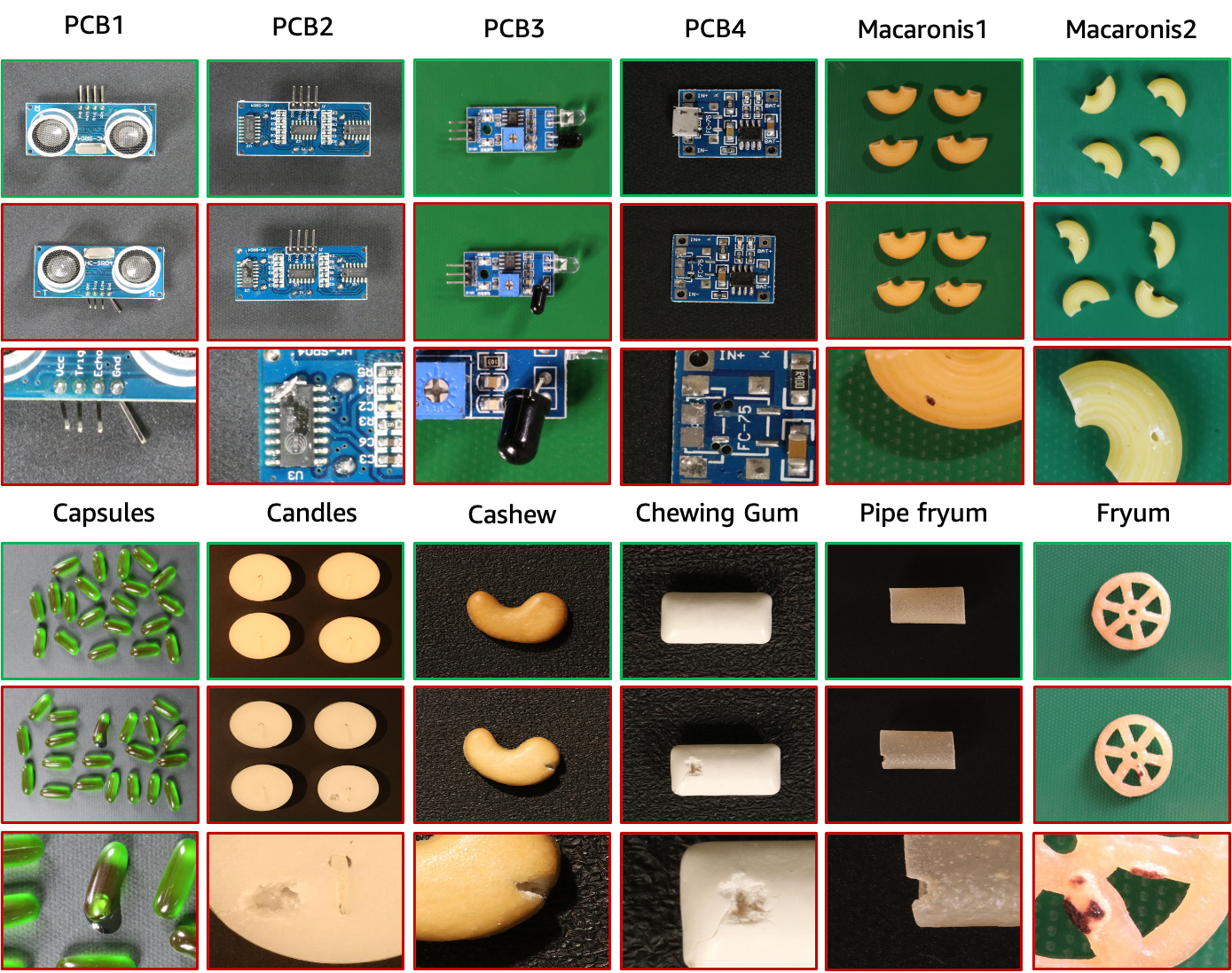
上の図に示すように、VisA データセットには、12 の異なるオブジェクトに対応する 12 のサブセットが含まれています。 9,621 個の正常サンプルと 1,200 個の異常サンプルを含む 10,821 個の画像があります。 4 つのサブセットは、トランジスタ、コンデンサ、チップなどを含む比較的複雑な構造を持つ、異なるタイプのプリント基板 (PCB) です。ビュー内に複数のインスタンスがある場合、カプセル、キャンドル、マカロニ 1 およびマカロニ 2 の 4 つのサブセットを収集します。 Capsules と Macaroni2 のインスタンスは、位置とポーズが大きく異なります。さらに、オブジェクトが大まかに配置されている、カシュー、チューインガム、フライム、パイプフライムを含む 4 つのサブセットを収集します。異常な画像には、傷、へこみ、色の斑点、亀裂などの表面欠陥や、部品の置き間違いや欠落などの構造的欠陥など、さまざまな欠陥が含まれています。
| 物体 | # 個の通常サンプル | # 個の異常サンプル | # 個の異常クラス | オブジェクトタイプ |
|---|---|---|---|---|
| プリント基板1 | 1,004 | 100 | 4 | 複雑な構造 |
| プリント基板2 | 1,001 | 100 | 4 | 複雑な構造 |
| プリント基板3 | 1,006 | 100 | 4 | 複雑な構造 |
| PCB4 | 1,005 | 100 | 7 | 複雑な構造 |
| カプセル | 602 | 100 | 5 | 複数のインスタンス |
| キャンドル | 1,000 | 100 | 8 | 複数のインスタンス |
| マカロニス1 | 1,000 | 100 | 7 | 複数のインスタンス |
| マカロニス2 | 1,000 | 100 | 7 | 複数のインスタンス |
| カシュー | 500 | 100 | 9 | 単一インスタンス |
| チューインガム | 503 | 100 | 6 | 単一インスタンス |
| フライム | 500 | 100 | 8 | 単一インスタンス |
| パイプフラム | 500 | 100 | 9 | 単一インスタンス |
VisA データセットは AWS S3 でホストされており、この URL でダウンロードできます。
ダウンロードしたデータのデータツリーは以下の通りです。
VisA
| -- candle
| ----- | --- Data
| ----- | ----- | ----- Images
| ----- | ----- | -------- | ------ Anomaly
| ----- | ----- | -------- | ------ Normal
| ----- | ----- | ----- Masks
| ----- | ----- | -------- | ------ Anomaly
| ----- | --- image_anno.csv
| -- capsules
| ----- | ----- ...image_annot.csv は、各画像の画像レベルのラベルとピクセルレベルの注釈マスクを提供します。マルチクラス マスクの id2class マップ関数は ./utils/id2class.py にあります。ここでは、スペースを節約するために通常のイメージのマスクは保存されません。
元の論文で説明されている 1 クラス、2 クラス ハイショット、2 クラス フューショットのセットアップを準備するには、./utils/prepare_data.py を使用して、「./split_csv/」内のデータ分割ファイルに従ってデータを再編成します。 。 1 クラスのセットアップを準備するためのサンプル コマンド ラインを次のように示します。
python ./utils/prepare_data.py --split-type 1cls --data-folder ./VisA --save-folder ./VisA_pytorch --split-file ./split_csv/1cls.csv
再編成された1クラス設定のデータツリーは以下のとおりです。
VisA_pytorch
| -- 1cls
| ----- | --- candle
| ----- | ----- | ----- ground_truth
| ----- | ----- | ----- test
| ----- | ----- | ------- | ------- good
| ----- | ----- | ------- | ------- bad
| ----- | ----- | ----- train
| ----- | ----- | ------- | ------- good
| ----- | --- capsules
| ----- | --- ...具体的には、1クラス設定用に再構成されたデータはMVTec-ADのデータツリーに従います。オブジェクトごとに、データには 3 つのフォルダーがあります。
元のデータセット内のマルチクラスのグラウンド トゥルース セグメンテーション マスクは、バイナリ マスクに再インデックス付けされます。0 は正常を示し、255 は異常を示します。
なお、2クラス設定もprepare_data.pyの引数を変更することで同様に準備できます。
分類およびセグメンテーションのメトリクスを計算するには、./utils/metrics.py を参照してください。ローカリゼーションメトリクスを計算する際には、正規サンプルが考慮されることに注意してください。これは、ローカリゼーションにおいて通常のサンプルを無視する他の作品とは異なります。
このデータセットがあなたのプロジェクトに役立つ場合は、次の論文を引用してください。
@article { zou2022spot ,
title = { SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation } ,
author = { Zou, Yang and Jeong, Jongheon and Pemula, Latha and Zhang, Dongqing and Dabeer, Onkar } ,
journal = { arXiv preprint arXiv:2207.14315 } ,
year = { 2022 }
}データは CC BY 4.0 ライセンスに基づいて公開されています。


