このリポジトリには、LLM の設定から派生した報酬関数を使用して NetHack 上で AI エージェントをトレーニングする、Motif 用の PyTorch コードが含まれています。
モチーフ: 人工知能のフィードバックによる内発的動機付け
Martin Klissarov* & Pierluca D'Oro*、シャグン・ソダーニ、ロベルタ・ライレヌ、ピエール=リュック・ベーコン、パスカル・ヴィンセント、エイミー・チャン、ミカエル・ヘナフ著
Motif は、NetHack 上で収集されたインタラクションのデータセットから、キャプション付きの観察のペアに関する大規模言語モデル (LLM) の好みを引き出します。自動的に、LLM の常識が、強化学習でエージェントをトレーニングするために使用される報酬関数に抽出されます。
比較を容易にするために、タスクをキーとして持つ辞書を含むトレーニング カーブを pickle ファイルmotif_results.pklに提供します。タスクごとに、複数のシードのタイムステップと、モチーフとベースラインの平均収益のリストを提供します。
次の図に示すように、Motif には 3 つのフェーズがあります。
論文内の実験を再現するために必要なデータセット、コマンド、生の結果を提供することで、各フェーズを詳しく説明します。
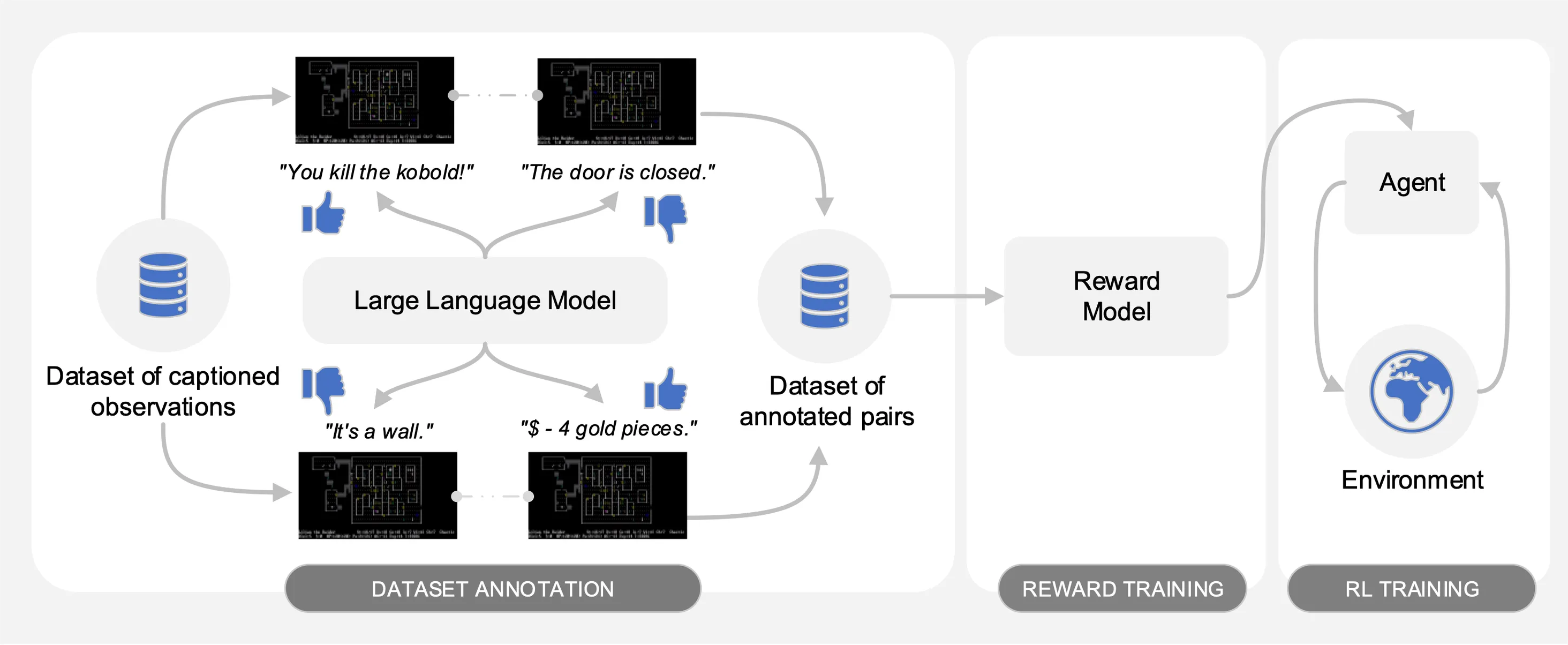
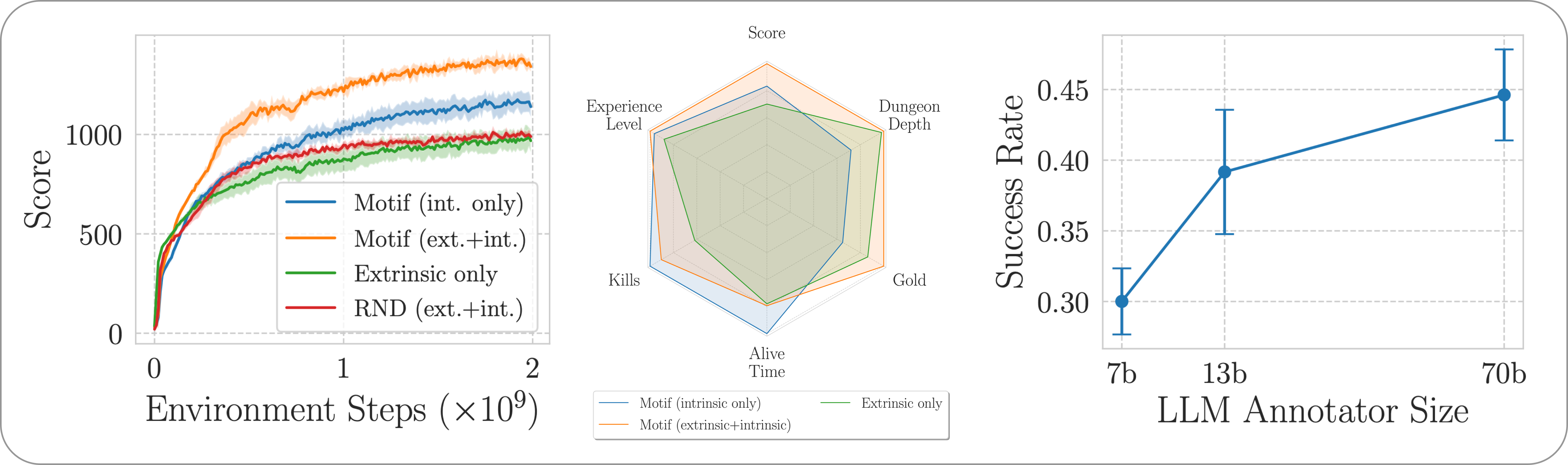
私たちは、NetHack 学習環境を通じて、やりがいのある、オープンエンドで手続き的に生成された NetHack ゲームにおける Motif のパフォーマンスを評価します。私たちは、Motif が人間に合わせた直観的な動作を主にどのように生成するのかを調査します。この動作は、プロンプトの変更によって簡単に操作できます。また、そのスケーリング特性も調査します。

パイプライン全体に必要な依存関係をインストールするには、 pip install -r requirements.txt実行するだけです。
最初のフェーズでは、ゲーム スコアを最大化するために強化学習で訓練されたエージェントによって収集された、キャプション付きの観察のペア (つまり、ゲームからのメッセージ) のデータセットを使用します。このリポジトリでデータセットを提供します。さまざまな部分をmotif_dataset_zippedディレクトリに保存します。このディレクトリは、次のコマンドを使用して解凍できます。
cat motif_dataset_zipped/motif_dataset_part_* > motif_dataset.zip; unzip motif_dataset.zip; rm motif_dataset.zip
私たちが提供するデータセットは、論文で説明されているさまざまなプロンプトを使用して、 preference/ディレクトリに含まれる Llama 2 モデルによって与えられる一連の設定を特徴としています。注釈を含む.npyファイルの名前は、テンプレートllama{size}b_msg_{instruction}_{version}に従います。ここで、 sizeはセット{7,13,70}からの LLM サイズで、 instructionは、セット{defaultgoal, zeroknowledge, combat, gold, stairs}から LLM に与えられるプロンプト。 versionセット{default, reworded} .ここでは、利用可能なアノテーションの概要を示します。
| 注釈 | 論文からのユースケース |
|---|---|
llama70b_msg_defaultgoal_default | 主な実験 |
llama70b_msg_combat_default | モンスタースレイヤーの行動への舵取り |
llama70b_msg_gold_default | ゴールドコレクターの行動への舵取り |
llama70b_msg_stairs_default | ディセンダーの動作に向けたステアリング |
llama7b_msg_defaultgoal_default | スケーリング実験 |
llama13b_msg_defaultgoal_default | スケーリング実験 |
llama70b_msg_zeroknowledge_default | ゼロ知識プロンプト実験 |
llama70b_msg_defaultgoal_reworded | 即時言い換え実験 |
注釈を作成するには、vLLM と Llama 2 のチャット バージョンを使用します。Llama 2 で独自の注釈を生成したい場合、または注釈プロセスを再現したい場合は、公式の手順に従ってモデルをダウンロードできることを確認してください (モデルの重みにアクセスできるようになるまでに数日かかります)。
アノテーション スクリプトは、 n-annotation-chunks引数を使用して、データセットが異なるチャンクにアノテーションが付けられることを前提としています。これにより、リソースの可用性に応じてプロセスを並列化でき、再起動やプリエンプションに対して堅牢になります。単一のチャンクを使用して実行し (つまり、データセット全体を処理するには)、デフォルトのプロンプト テンプレートとタスク仕様で注釈を付けるには、次のコマンドを実行します。
python -m scripts.annotate_pairs_dataset --directory motif_dataset
--prompt-version default --goal-key defaultgoal
--n-annotation-chunks 1 --chunk-number 0
--llm-size 70 --num-gpus 8
--ignore-existingフラグで特に指定されていない限り、デフォルトの動作では、構成を指定するファイルに注釈を追加することによって注釈プロセスが再開されることに注意してください。注釈用に作成される「.npy」ファイルの名前は、 --custom-annotator-stringフラグを使用して手動で選択することもできます。 32 GB のメモリを備えた単一の GPU を使用すると、 --llm-size 7および--llm-size 13使用してアノテーションを付けることができます。 8 GPU ノードで--llm-size 70使用してアノテーションを付けることができます。ここでは、100k ペアのデータセットについて、NVIDIA V100s 32G GPU を使用したアノテーション時間の大まかな推定値を提供します。これにより、ほとんどの結果 (500k ペアで取得) をほぼ再現できるはずです。
| モデル | 注釈を付けるリソース |
|---|---|
| ラマ 2 7b | ~32 GPU 時間 |
| ラマ 2 13b | ~40 GPU 時間 |
| ラマ 2 70b | 約 72 GPU 時間 |
第 2 フェーズでは、クロスエントロピーを通じて LLM の好みを報酬関数に抽出します。デフォルトのハイパーパラメータを使用して報酬トレーニングを開始するには、次のコマンドを使用します。
python -m scripts.train_reward --batch_size 1024 --num_workers 40
--reward_lr 1e-5 --num_epochs 10 --seed 777
--dataset_dir motif_dataset --annotator llama70b_msg_defaultgoal_default
--experiment standard_reward --train_dir train_dir/reward_saving_dir
報酬関数は、 --dataset_dirにあるannotatorのアノテーションを通じてトレーニングされます。結果の関数は、サブフォルダー--experimentの下のtrain_dirに保存されます。
最後に、強化学習を通じて結果として得られる報酬関数を使用してエージェントをトレーニングします。内部報酬と外部報酬を組み合わせた実験に使用されるデフォルトのハイパーパラメーターを使用して、 NetHackScore-v1タスクでエージェントをトレーニングするには、次のコマンドを使用できます。
python -m scripts.main --algo APPO --env nle_fixed_eat_action --num_workers 24
--num_envs_per_worker 20 --batch_size 4096 --reward_scale 0.1 --obs_scale 255.0
--train_for_env_steps 2_000_000_000 --save_every_steps 10_000_000
--keep_checkpoints 5 --stats_avg 1000 --seed 777 --reward_dir train_dir/reward_saving_dir/standard_reward/
--experiment standard_motif --train_dir train_dir/rl_saving_dir
--extrinsic_reward 0.1 --llm_reward 0.1 --reward_encoder nle_torchbeast_encoder
--root_env NetHackScore-v1 --beta_count_exponent 3 --eps_threshold_quantile 0.5
タスクを変更するには、 --root_env引数を変更するだけです。次の表は、論文で提示された実験と一致するために必要な値を明示的に示しています。 NetHackScore-v1タスクは、エージェントに目標を達成するよう促すために、 extrinsic_reward値が0.1になるように学習されますが、他のすべてのタスクは値10.0をとります。
| 環境 | root_env |
|---|---|
| スコア | NetHackScore-v1 |
| 階段 | NetHackStaircase-v1 |
| 階段(レベル3) | NetHackStaircaseLvl3-v1 |
| 階段(レベル4) | NetHackStaircaseLvl4-v1 |
| オラクル | NetHackOracle-v1 |
| オラクル-地味 | NetHackOracleSober-v1 |
さらに、環境からの報酬を使用せず、LLM からの固有報酬のみを使用してエージェントをトレーニングする場合は、 --extrinsic_reward 0.0設定するだけです。本質的報酬のみの実験では、エージェントが目標に到達したときではなく、エージェントが死亡した場合にのみエピソードを終了します。これらの変更された環境を次の表に列挙します。
| 環境 | root_env |
|---|---|
| 階段 (レベル 3) - 本質的のみ | NetHackStaircaseLvl3Continual-v1 |
| 階段 (レベル 4) - 本質的のみ | NetHackStaircaseLvl4Continual-v1 |
さらに、トレーニングされた RL エージェントを視覚化するためのスクリプトも提供します。これにより、その動作に関する重要な洞察が得られるだけでなく、各エピソードのトップ メッセージも生成され、最適化しようとしているものを理解するのに役立ちます。次のコマンドを実行するだけです。
python -m scripts.visualize --train_dir train_dir/rl_saving_dir --experiment standard_motif
私たちの成果を基にしている場合、またはそれが役立つと思われる場合は、次の bibtex を使用して引用してください。
@article{klissarovdoro2023motif,
title={Motif: Intrinsic Motivation From Artificial Intelligence Feedback},
author={Klissarov, Martin and D’Oro, Pierluca and Sodhani, Shagun and Raileanu, Roberta and Bacon, Pierre-Luc and Vincent, Pascal and Zhang, Amy and Henaff, Mikael},
year={2023},
month={9},
journal={arXiv preprint arXiv:2310.00166}
}
Motif の大部分は CC-BY-NC に基づいてライセンスされていますが、プロジェクトの一部は別のライセンス条項に基づいて利用可能です。sample-factory は MIT ライセンスに基づいてライセンスされています。


