

MPIREは MultiProcessing Is Really Easy の略で、マルチプロセッシング用の Python パッケージです。 MPIRE 、ほとんどのシナリオで高速であり、より多くの機能を搭載しており、通常、デフォルトのマルチプロセッシング パッケージよりもユーザー フレンドリーです。これは、 multiprocessing.Poolの関数のような便利なマップと、 multiprocessing.Processのコピーオンライト共有オブジェクトを使用する利点、および使いやすいワーカー状態、ワーカーの洞察、ワーカーの初期化および終了関数、タイムアウト、プログレスバー機能。
完全なドキュメントは https://sybrenjansen.github.io/mpire/ で入手できます。
map / map_unordered / imap / imap_unordered / apply / apply_async関数を使用したマルチプロセスforkでのみ使用可能)richとノートブックウィジェットがサポートされています)daemonオプションを設定する場合、ワーカーのネストされたプールが許可されますMPIRE は、Linux、macOS、および Windows でテストされています。 Windows および macOS ユーザーの場合、既知の小さな注意事項がいくつかあります。それらについては、「トラブルシューティング」の章に記載されています。
pip (PyPi) 経由:
pip install mpireMPIRE は conda-forge からも入手できます。
conda install -c conda-forge mpire入力を受け取り、その結果を返す、時間のかかる関数があるとします。このような単純な関数は、恥ずかしいほど並列問題として知られており、並列タスクに変えるのにほとんど労力を必要としない関数です。単純な関数の並列化は、 multiprocessingインポートしてmultiprocessing.Poolクラスを使用するのと同じくらい簡単です。
import time
from multiprocessing import Pool
def time_consuming_function ( x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
with Pool ( processes = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) MPIRE は、ほぼマルチmultiprocessingのドロップイン代替品として使用できます。 mpire.WorkerPoolクラスを使用し、利用可能なmap関数の 1 つを呼び出します。
from mpire import WorkerPool
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ))コードの違いはわずかです。通常のマルチmultiprocessingに慣れている場合は、まったく新しいマルチプロセッシング構文を学ぶ必要はありません。ただし、利用可能な追加機能が MPIRE の特徴です。
現在のタスクのステータスを知りたいとします。完了したタスクの数や、作業の準備が整うまでにどのくらい時間がかかりますか?これは、 progress_barパラメータをTrueに設定するのと同じくらい簡単です。
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )また、適切にフォーマットされた tqdm プログレスバーが出力されます。
MPIRE にはダッシュボードも用意されており、追加の依存関係をインストールする必要があります。詳細については、「ダッシュボード」を参照してください。
注: コピーオンライト共有オブジェクトは、開始メソッドforkでのみ使用できます。 threadingの場合、オブジェクトはそのまま共有されます。他の開始メソッドの場合、共有オブジェクトはワーカーごとに 1 回コピーされますが、タスクごとに 1 回よりも優れている可能性があります。
すべてのワーカー間で共有したいオブジェクトが 1 つ以上ある場合は、MPIRE のコピーオンライトshared_objectsオプションを利用できます。 MPIRE は、コピーやシリアル化を行わずに、ワーカーごとにこれらのオブジェクトを 1 回だけ渡します。ワーカー関数内のオブジェクトを変更した場合にのみ、そのワーカーに対してそのオブジェクトのコピーが開始されます。
def time_consuming_function ( some_object , x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
def main ():
some_object = ...
with WorkerPool ( n_jobs = 5 , shared_objects = some_object ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )詳細については、「shared_objects」を参照してください。
ワーカーは、 worker_init機能を使用して初期化できます。 worker_stateと併用すると、モデルをロードしたり、データベース接続をセットアップしたりすることができます。
def init ( worker_state ):
# Load a big dataset or model and store it in a worker specific worker_state
worker_state [ 'dataset' ] = ...
worker_state [ 'model' ] = ...
def task ( worker_state , idx ):
# Let the model predict a specific instance of the dataset
return worker_state [ 'model' ]. predict ( worker_state [ 'dataset' ][ idx ])
with WorkerPool ( n_jobs = 5 , use_worker_state = True ) as pool :
results = pool . map ( task , range ( 10 ), worker_init = init )同様に、 worker_exit機能を使用すると、ワーカーが終了するたびに MPIRE で関数を呼び出すことができます。この exit 関数に結果を返させることもでき、その結果は後で取得できます。詳細については、「worker_init」と「worker_exit」のセクションを参照してください。
マルチプロセッシング設定が期待どおりに実行されず、その原因がわからない場合は、ワーカー インサイト機能を使用します。これにより、セットアップに関する洞察が得られますが、実行している関数のプロファイリングは行われません (そのためのライブラリは他にもあります)。代わりに、作業者の起動時間、待機時間、作業時間をプロファイルします。ワーカーの初期化関数と終了関数が提供されている場合、それらの関数も同様に計測されます。
おそらく、タスク キューを介して大量のデータを送信しているため、待ち時間が長くなっている可能性があります。いずれの場合でも、 enable_insightsフラグとmpire.WorkerPool.get_insights関数を使用して、それぞれ有効にして洞察を取得できます。
with WorkerPool ( n_jobs = 5 , enable_insights = True ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ))
insights = pool . get_insights ()より詳細な例と予想される出力については、Worker Insights を参照してください。
タイムアウトは、target、 worker_init 、 worker_exit関数に対して個別に設定できます。タイムアウトが設定されて到達すると、 TimeoutErrorがスローされます。
def init ():
...
def exit_ ():
...
# Will raise TimeoutError, provided that the target function takes longer
# than half a second to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), task_timeout = 0.5 )
# Will raise TimeoutError, provided that the worker_init function takes longer
# than 3 seconds to complete or the worker_exit function takes longer than
# 150.5 seconds to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), worker_init = init , worker_exit = exit_ ,
worker_init_timeout = 3.0 , worker_exit_timeout = 150.5 )開始メソッドとしてthreading使用する場合、MPIRE はtime.sleepなどの特定の関数を中断できません。
詳細については、「タイムアウト」を参照してください。
MPIRE は、数値計算、ステートフル計算、および高価な初期化という 3 つの異なるベンチマークでベンチマークされています。これらのベンチマークの詳細については、このブログ投稿を参照してください。これらのベンチマークのコードはすべて、このプロジェクトにあります。
つまり、MPIRE が高速である主な理由は次のとおりです。
forkが利用可能な場合、コピーオンライト共有オブジェクトを利用できるため、子プロセス間で共有する必要があるオブジェクトをコピーする必要性が減ります。次のグラフは、3 つのベンチマークすべての平均正規化結果を示しています。個々のベンチマークの結果はブログ投稿でご覧いただけます。ベンチマークは、20 コア、無効なハイパースレッディング、200 GB の RAM を備えた Linux マシンで実行されました。各タスクについて、異なる数のプロセス/ワーカーを使用して実験が実行され、結果は 5 回の実行で平均されました。
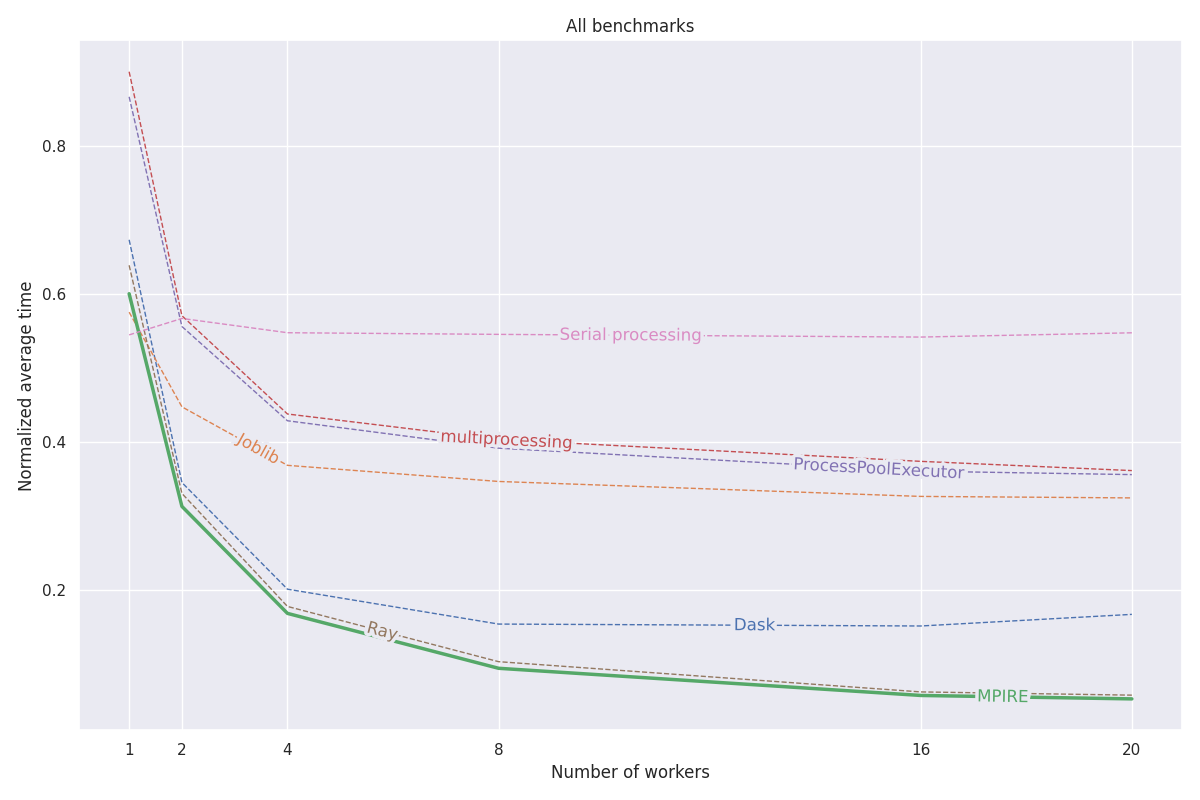
MPIRE の他のすべての機能については、https://sybrenjansen.github.io/mpire/ にある完全なドキュメントを参照してください。
ドキュメントを自分で構築したい場合は、次のコマンドを実行してドキュメントの依存関係をインストールしてください。
pip install mpire[docs]または
pip install .[docs]その後、Python 3.9 以下を使用して以下を実行することでドキュメントを構築できます。
python setup.py build_docsドキュメントはdocsフォルダーから直接ビルドすることもできます。その場合、 MPIREがインストールされ、現在の作業環境で使用できるようになります。次に、以下を実行します。
make html docsフォルダー内にあります。


