clearml agent
v1.9.2

ClearML エージェント - MLOps/LLMOps が簡単になりました
Linux、macOS、Windows をサポートする MLOps/LLMOps スケジューラおよびオーケストレーション ソリューション
? ClearML is open-source - Leave a star to support the project! ?
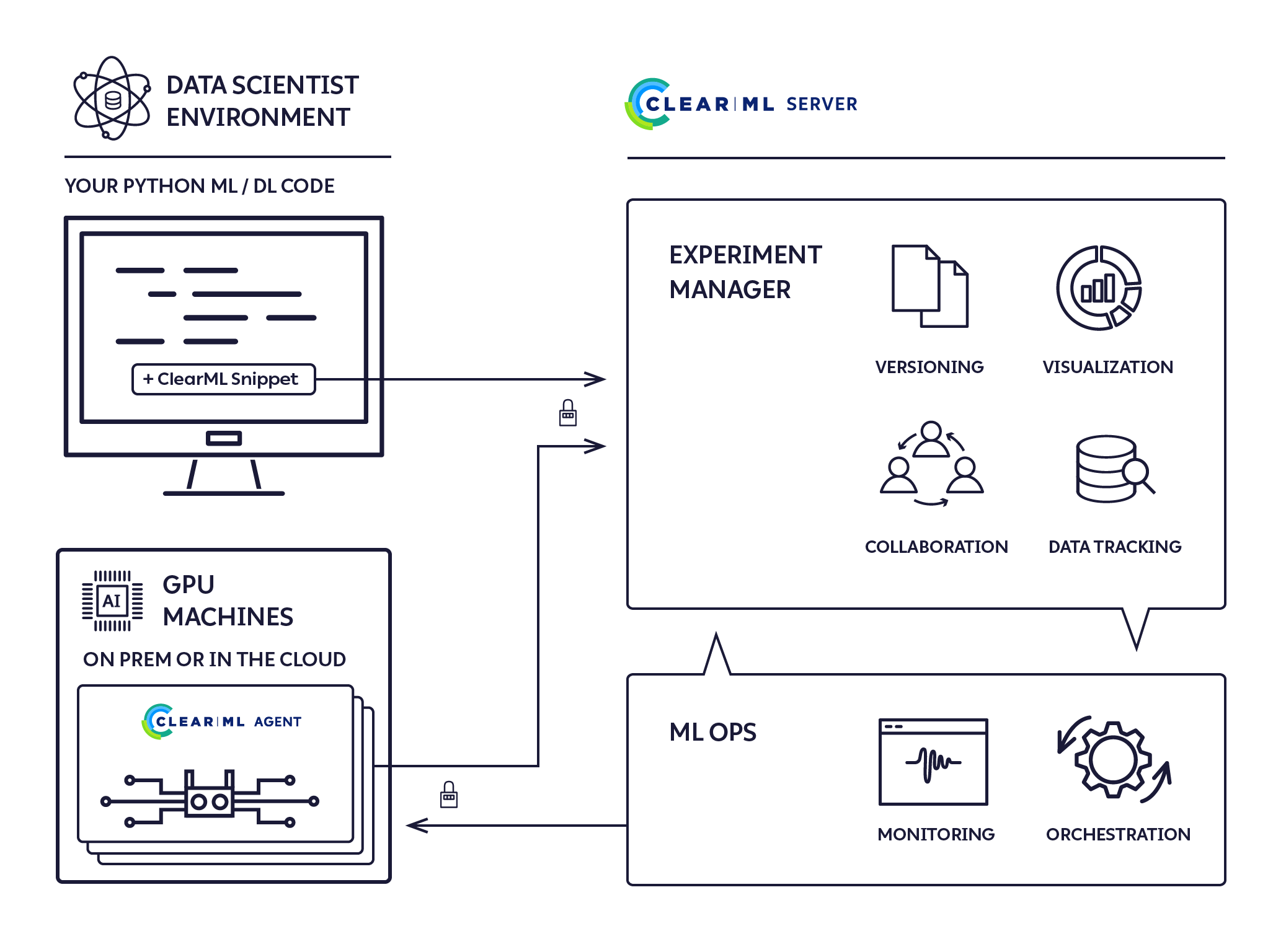
これは、完全な ML/DL クラスター ソリューションを提供する、ゼロ構成のファイアアンドフォーゲット実行エージェントです。
5ステップで完全自動化
pip install clearml-agent (任意の GPU マシン: オンプレミス / クラウド / ...) に ClearML エージェントをインストールします。「研究に必要なディープ / 機械学習 DevOps をすべて実行し、さらにいくつか... なぜなら、誰もそのようなことに時間を割くことができないからです。」
今すぐ ClearML を試すセルフホスティングまたは無料枠ホスティング
ClearML エージェントは、DL/ML R&D DevOps の次のニーズに対応するために構築されました。
ClearML エージェントを使用して、*epsilon DevOps で動的クラスターをセットアップできるようになりました
*イプシロン - 私たちはそうなので?そして本当にゼロの仕事なんてない
私たちは Kubernetes が素晴らしいと考えていますが、リモート実行エージェントとクラスター管理を始めるのに必須ではありません。私たちは、環境に合わせてベアメタルと Kubernetes 上の両方を実行できるように、 clearml-agent設計しました。
Dockerfile は docker フォルダーにあり、helm チャートは https://github.com/allegroai/clearml-helm-charts にあります。
Kubernetes Glue モードでエージェントを実行し、ClearML ジョブを K8s ジョブに直接マップします。
はい! Slurm の統合が利用可能です。詳細についてはドキュメントを確認してください。
ボタンをクリックするだけで本格的な HPC を実現
ClearML エージェントは、ジョブ キューをリッスンし、ジョブを取得し、ジョブ環境を設定し、ジョブを実行し、その進行状況を監視するジョブ スケジューラです。
すべての「ドラフト」実験は、ClearML エージェントによる実行をスケジュールできます。
以前に実行した実験は、次の 2 つの方法のいずれかで「ドラフト」状態にできます。
実験の実行は、ClearML UI の実験を右クリックしてコンテキスト メニューから[エンキュー]アクションを選択し、実行キューを選択して実行するようにスケジュールされます。
実験を作成して実行のためにキューに入れる方法を参照してください。
実験がキューに追加されると、このキューを監視している ClearML エージェントによって実験が取得されて実行されます。
ClearML UI の [ワーカーとキュー] ページには、進行中の実行情報が表示されます。
ClearML エージェントは、次のプロセスを使用して実験を実行します。
pip install clearml-agent完全なインターフェイスと機能は、
clearml-agent --help
clearml-agent daemon --helpclearml-agent init注: ClearML エージェントは、キャッシュ フォルダーを使用して、pip パッケージ、apt パッケージ、クローン リポジトリをキャッシュします。デフォルトの ClearML エージェント キャッシュ フォルダーは~/.clearmlです。
~/clearml.confにある構成ファイルで詳細を確認してください。
注: ClearML エージェントは、 ClearML構成ファイル~/clearml.confを拡張します。これらは同じ構成ファイルを共有するように設計されています。ここで例を参照してください。
デバッグと実験の場合は、ClearML エージェントをforegroundモードで起動し、すべての出力が画面に出力されます。
clearml-agent daemon --queue default --foreground実際のサービス モードでは、すべての stdout が一時ファイルに自動的に保存されます (パイプする必要はありません)。注意: --detachedフラグを使用すると、 clearml-agent がバックグラウンドで実行されます。
clearml-agent daemon --detached --queue default GPU の割り当ては、標準の OS 環境NVIDIA_VISIBLE_DEVICESまたは--gpusフラグ (または--cpu-onlyで無効) によって制御されます。
フラグが設定されておらず、 NVIDIA_VISIBLE_DEVICES変数が存在しない場合は、すべての GPU がclearml-agentに割り当てられます。
--cpu-onlyフラグが設定されている場合、またはNVIDIA_VISIBLE_DEVICES="none"場合、GPU はclearml-agentに割り当てられません。
例: 同じマシン上の GPU ごとに 1 つずつ、2 つのエージェントをスピンします。
注意: --detachedフラグを使用すると、 clearml-agent がバックグラウンドで実行されます。
clearml-agent daemon --detached --gpus 0 --queue default
clearml-agent daemon --detached --gpus 1 --queue default例: 2 つのエージェントをスピンし、専用のdual_gpuキューから取得し、エージェントごとに 2 つの GPU
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpuデバッグと実験の場合は、ClearML エージェントをforegroundモードで起動し、すべての出力が画面に出力されます。
clearml-agent daemon --queue default --docker --foreground実際のサービス モードでは、すべての stdout が自動的にファイルに保存されます (パイプする必要はありません)。注意: --detachedフラグを使用すると、 clearml-agent がバックグラウンドで実行されます。
clearml-agent daemon --detached --queue default --docker例: デフォルトのnvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 Docker を使用して、同じマシン上の GPU ごとに 1 つずつ、2 つのエージェントをスピンします。
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 1 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04例: デフォルトのnvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 Docker を使用して、専用のdual_gpuキューからプルして 2 つのエージェントをスピンし、エージェントごとに 2 つの GPU を使用します。
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04プライオリティ キューもサポートされています。使用例:
高優先度キュー: important_jobs 、低優先度キュー: default
clearml-agent daemon --queue important_jobs default ClearML エージェントは、最初にimportant_jobsキューからジョブを取得しようとします。キューが空の場合にのみ、 defaultキューからジョブを取得しようとします。
キューの追加、キュー内のジョブ順序の管理、キュー間でのジョブの移動は、Web UI を使用して実行できます。無料サーバーの例を参照してください。
バックグラウンドで実行されているClearML エージェントを停止するには、エージェントの起動に使用したのと同じコマンド ラインに--stop追加して実行します。たとえば、上に示した同じマシンの最初の単一 GPU エージェントを停止するには、次のようにします。
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 --stopClearML をコードと統合する
マシン上でコードを実行します (手動 / PyCharm / Jupyter Notebook)
コードの実行中、 ClearML は必要な実行情報をすべて記録する実験を作成します。
これで、自動実行に必要なものがすべて揃った実験の「テンプレート」が完成しました。
ClearML UI で、実験を右クリックし、[クローン] を選択します。実験のコピーが作成されます。
元の実験からクローンされた新しいドラフト実験が作成されました。自由に編集してください。
新しく作成した実験の実行をスケジュールします。実験を右クリックして「エンキュー」を選択します。
ClearML-Agent Services は、ClearML-Agent の特別なモードであり、以前はローカル/専用マシンで実行する必要があった長期にわたるジョブを起動する機能を提供します。これにより、単一のエージェントがさまざまなユースケースに合わせて複数の Docker (タスク) を起動できるようになります。
ClearML-Agent Services モードは、指定されたキューにエンキューされたタスクをスピンします。 ClearML-Agent Services によって起動されるすべてのタスクは、システム内の新しいノードとして登録され、追跡機能と透過性機能を提供します。現在、サービス モードの clearml-agent は CPU のみの構成をサポートしています。 ClearML-Agent サービス モードは、GPU エージェントと一緒に起動できます。
clearml-agent daemon --services-mode --detached --queue services --create-queue --docker ubuntu:18.04 --cpu-only注: 適切なタスクが指定されたキューにプッシュされていることを確認するのはユーザーの責任です。
ClearML エージェントを使用して、ClearML パッケージと組み合わせて AutoML オーケストレーションおよび実験パイプラインを実装することもできます。
AutoML とオーケストレーションのサンプル例は、ClearML example/automation フォルダーにあります。
AutoML の例:
実験パイプラインの例:
Apache ライセンス、バージョン 2.0 (詳細についてはライセンスを参照してください)


