地下鉄管理システム
SUSTech 2024 Spring のコースCS307 - Principles of Database System
Shenzhen-Metro
├── Project1 # part 1 of project (database design and data import)
│ ├── ShenzhenMetroDatabaseDesign
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # import script in java
│ │ │ │ ├── resources # data in json
│ │ │ │ └── sql # ddl
│ └── ShenzhenMetroDatabaseDesignPython
│ ├── import_script.py # import script in python
│ └── resources # data in json
├── Project2 # part 2 of project (building an api)
│ ├── DataImport # updated data import
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # updated import script in java
│ │ │ │ ├── resources # updated data
│ │ │ │ └── sql # updated ddl
│ └── ShenzhenMetro # spring boot project
│ ├── src
│ │ ├── main
│ │ │ ├── java # backend logic
│ │ │ │ └── com/sustech/cs307/project2/shenzhenmetro
│ │ │ │ ├── ShenzhenMetroApplication.java # main application driver
│ │ │ │ ├── controller # api route mapping
│ │ │ │ ├── dto # dto between client and server
│ │ │ │ ├── object # orm between database tables and application code
│ │ │ │ ├── repository # interfaces for data access
│ │ │ │ └── service # service layer containing business logic
│ │ │ └── resources # frontend logic
│ │ │ ├── application.properties # configuration file for spring boot application
│ │ │ ├── static
│ │ │ │ ├── assets
│ │ │ │ │ ├── css
│ │ │ │ │ ├── img
│ │ │ │ │ ├── js
│ │ │ │ │ └── vendor
│ │ │ │ │ ├── aos
│ │ │ │ │ ├── bootstrap
│ │ │ │ │ ├── bootstrap-icons
│ │ │ │ │ ├── glightbox
│ │ │ │ │ └── swiper
│ │ │ │ └── index.html # main html
│ │ │ └── templates
│ │ │ ├── buses
│ │ │ │ ├── create_bus.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_bus.html
│ │ │ ├── landmarks
│ │ │ │ ├── create_landmark.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_landmark.html
│ │ │ ├── lineDetails
│ │ │ │ ├── create_line_detail.html
│ │ │ │ ├── index.html
│ │ │ │ ├── navigate_routes.html
│ │ │ │ └── search_line_detail.html
│ │ │ ├── lines
│ │ │ │ ├── create_line.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_line.html
│ │ │ ├── ongoingRides
│ │ │ │ └── index.html
│ │ │ ├── rides
│ │ │ │ ├── create_ride.html
│ │ │ │ ├── filter_ride.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_ride.html
│ │ │ ├── stations
│ │ │ │ ├── create_station.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_station.html
│ │ │ └── users
│ │ │ ├── card.html
│ │ │ └── passenger.html
└── README.md
プロジェクトの最初の部分では、主に、提供されたデータの背景に基づいて、リレーショナル データベースの原則を満たすデータベース スキーマを設計します。設計フェーズが完了したら、それらの大規模なデータセットをインポートするためのスクリプトを作成しました。インポートされたデータの正確性を確保するために、弁護日にいくつかのクエリ ステートメントを実行し、クエリ結果をチェックする必要がありました。それに加えて、後で示すように、いくつかの素晴らしい洞察を得るために、データを使用していくつかの実験も実行しました。
[詳しい要件を読む]
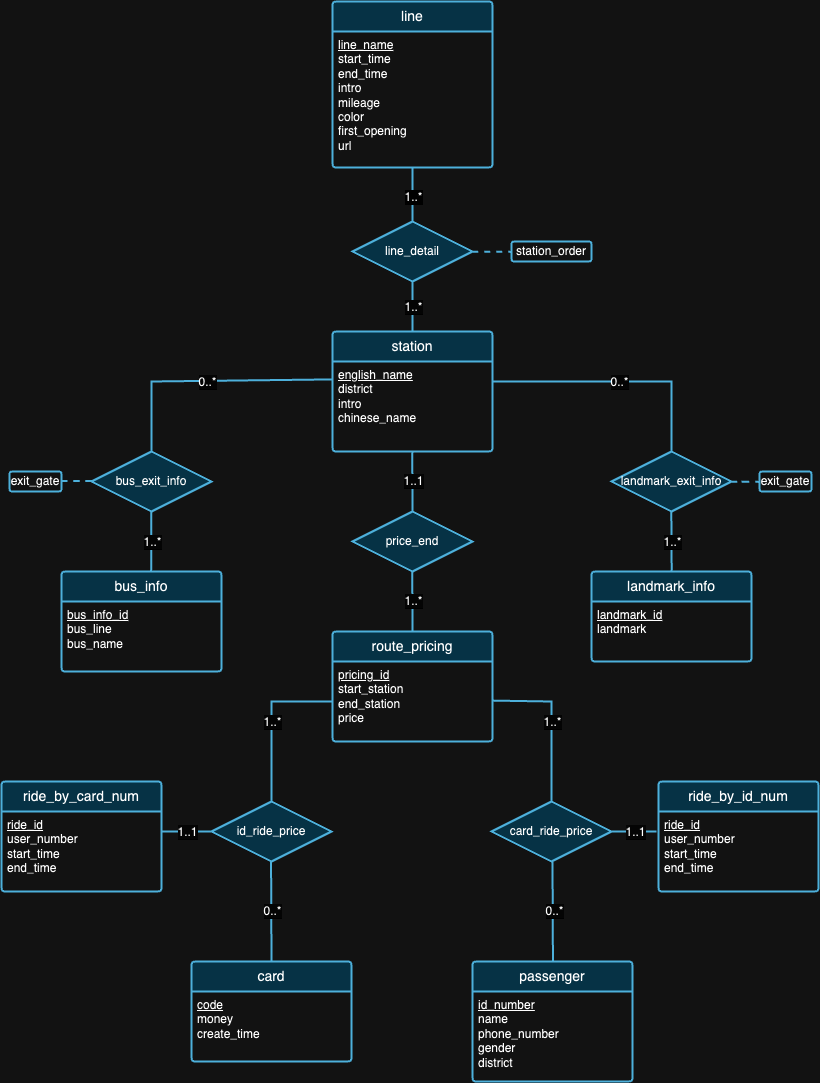
私たちは、完璧なデータベース設計は存在しないと考えています。実際、上記の ER 図で私たちが提案した設計には欠陥があります。データセットと各データセットの背景を確認した後、ご自身で設計上の欠陥を見つけてみていただければ幸いです。 :)
注:図の解釈については、
| ID | OS | チップ | メモリ | SSD | ツール |
|---|---|---|---|---|---|
| 1 | macOS ソノマ 14.4.1 | アップル M3 プロ | 18GB | 1TB | IDEA 2024.1 (CE)、PyCharm 2023.3.4 (CE)、Datagrip 2024.1 |
| 2 | Windows 11 ホーム 23H2 | 第12世代インテル(R) Core(TM) i9-12900H | 32GB | 1TB | IDEA 2024.1 (CE)、データグリップ 2024.1 |
| 3 | Ubuntu 22.04.4 (VM) | アップル M1 プロ | 16ギガバイト | 512GB | IDEA 2024.1 (CE)、データグリップ 2024.1 |
Experiment 1: Different Import Methods方法 1 (オリジナル スクリプト): この方法では、 java.sqlライブラリを利用します。まず、PostgreSQL サーバーへの接続を確立しました。次に、JSON ファイルからすべてのデータを読み取ります。次に、各データを反復処理し、挿入ステートメントごとにPreparedStatement作成しました。最後に、 executeUpdate()メソッドを呼び出して、各ステートメントを個別に実行しました。
方法 2 (最適化されたスクリプト): この方法でもjava.sqlライブラリが利用され、方法 1 と同じデータ読み取りアルゴリズムが使用されます。違いは、 executeBatch()メソッドを使用することです。そこで、データ全体を反復処理し、 PreparedStatementを使用して各挿入ステートメントを作成し、バッチ実行のために各PreparedStatementバッチに追加しました。
方法 3 (.sql ファイルの実行): Java プログラムを使用して SQL 挿入ステートメントを生成し、上記と同じデータ読み取りアルゴリズムを使用してそれらを.sqlファイルに書き込みました。次に、DataGrip でファイルを実行します。
3 つのメソッドすべてで同じデータ読み取りアルゴリズムを使用しているため、後続のテストでは平均ランタイムを使用します。最初に 3 つの異なる実行時間 (504 ミリ秒、546 ミリ秒、552 ミリ秒) を収集し、平均実行時間 534 ミリ秒を計算しました。
| テスト環境 | 方法 | 平均読み取り時間 (ミリ秒) | 書き込み時間 (ミリ秒) | 合計時間 (ミリ秒) | スループット (ステートメント/秒) |
|---|---|---|---|---|---|
| 1 | 1 | 534 | 206396 | 206930 | 8636.91 |
| 1 | 2 | 534 | 2114 | 2648 | 97632.92 |
| 1 | 3 | 534 | 13581 | 14115 | 15197.41 |
表 2 は、さまざまなメソッドにわたるさまざまなパフォーマンス メトリックを示しています。メソッド 2 は最高のスループットを示し、メソッド 1 は合計時間が最も遅いことを示しています。これにより、方法 2 が今後の実験における標準的なテスト方法になります。
Experiment 2: Data Import with Different Data Volumesさまざまなボリュームのデータの管理とインポートは、データベース システムのパフォーマンス、拡張性、信頼性を確保する上で重要な側面です。
インポート プロセスの前に、「乗り物」データの量が他のものと比べて著しく大きいことに気づきました。この考えに基づいて、 ride.jsonのみで異なるボリュームでデータのインポートをテストすることにしました。データの重みが一貫していないため、他のテーブルのインポート量を少なくすると、テーブル間の接続により重大な問題が発生する可能性があります。
最初に、設計の一貫性を確保するために、 rides_by_id_numテーブルとrides_by_card_numテーブルを除く他のすべてのテーブルの完全なデータ (100% ボリューム) をインポートすることから始めました。これを効果的に管理するために、 rideデータの段階的なインポート戦略を採用し、データの 20% のサブセット (20,000 レコードに相当) から始めました。この最初のフェーズにより、データベースの安定性を損なうことなく、システム パフォーマンスへの影響を評価し、インポート プロセスに必要な調整を行うことができました。検証とパフォーマンスの調整が成功した後、データの 50% のインポートを続行し、最後に残りの部分をインポートして 100% データのインポートを完了しました。最も速い方法 2 をすべてのインポートに使用したことに注意してください。
| テスト環境 | 方法 | 音量 | 読み取り時間 (ミリ秒) | 書き込み時間 (ミリ秒) | 合計時間 (ミリ秒) | ステートメントの数 | スループット (ステートメント/秒) |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 20% | 507 | 808 | 1315 | 80165 | 99214.11 |
| 1 | 2 | 50% | 521 | 1338 | 1859年 | 130849 | 97794.47 |
| 1 | 2 | 100% | 534 | 2114 | 2648 | 203502 | 96263.95 |
表 3 から、データ量が増加するにつれて (20% から 50%、および 100% へ)、読み取り時間と書き込み時間の両方が増加する傾向があり、その結果、操作の合計時間が長くなります。ただし、輸入量が異なるため、これらの数字は洞察力のある意味を与えません。代わりにスループット数に注目すると、データ量の増加に伴ってスループット (ステートメント/秒) が徐々に減少しており、ワークロードが増加するにつれてシステムのステートメント処理の効率が低下していることがわかります。
Experiment 3: Data Import on Different Operating Systemsさまざまな OS でデータをインポートするプロセスをテストする場合、インポート量が 100% の最も高速なインポート方法である方法 2 を採用しました。
仮想マシンを介して Linux 上で Java インポート スクリプトを実行する場合は、仮想化によってオーバーヘッドが生じ、システムの効率に影響を与える可能性があるため、パフォーマンスとリソース割り当てに対する不当な不利益を考慮することが重要であることに注意してください。
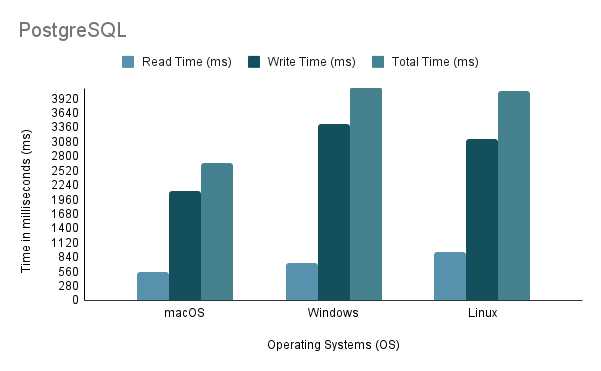
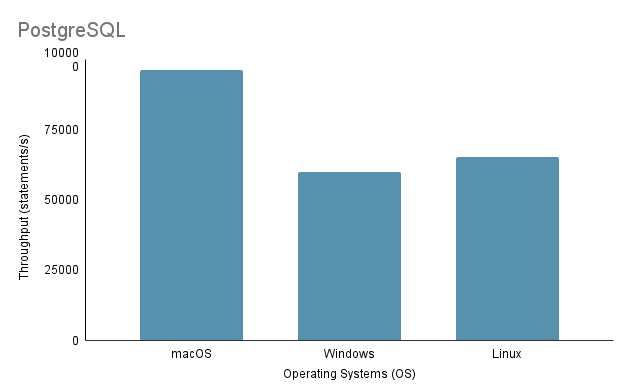
上記の分析に基づいて、環境 1 (macOS) が、合計時間が 2648 ミリ秒と最も短く、スループットが 97,632.92 ステートメント/秒で最高のパフォーマンスを示していることは明らかです。対照的に、環境 2 (Windows) は合計時間が 4117 ミリ秒で最も遅く、スループットは 60,669.02 ステートメント/秒で最低です。 Linux Ubuntu が VM として実行されているにもかかわらず、依然としてベアメタル Windows よりも優れたパフォーマンスを示していることは注目に値します。
Experiment 4: Data Import with Various Programming Languagesこの実験では、Java コードに対して前述の方法 2 が最も高速であるため、それを使用しました。一方、Python では、Psycopg2 を利用して PostgreSQL データベース サーバーと通信するインポート メソッドを作成しました。
| テスト環境 | プログラミング言語 | 読み取り時間 (ミリ秒) | 書き込み時間 (ミリ秒) | 合計時間 (ミリ秒) | スループット (ステートメント/秒) |
|---|---|---|---|---|---|
| 1 | ジャワ | 534 | 2114 | 2648 | 96263.95 |
| 1 | パイソン | 390 | 7237 | 7627 | 28119.66 |
表 4 のデータは、Java が速度とスループットの両方で Python を上回っていることを示しており、読み取り/書き込み操作の効率が優れていることを示しています。
Experiment 5: Data Import on Different DatabasesPostgreSQL と MySQL の両方に対して 3 つの異なるインポート方法を開発しましたが、データのインポートについては開発者が選択したものであるため、方法 2 についてのみ実験を実行しました。 PostgreSQL と MySQL はどちらも、同様のデータベース実装設計 (DDL に関して) と同様のインポート コード設計を備えています。
| テスト環境 | 方法 | データベース | 読み取り時間 (ミリ秒) | 書き込み時間 (ミリ秒) | 合計時間 (ミリ秒) | スループット (ステートメント/秒) |
|---|---|---|---|---|---|---|
| 1 | 2 | PostgreSQL | 534 | 2114 | 2648 | 96263.95 |
| 1 | 2 | MySQL | 534 | 42315 | 42849 | 4809.22 |
どちらも SQL ベースのデータベースであるにもかかわらず、書き込み時間に関しては PostgreSQL の方が約 16 倍高速です。これは、データベース エンジンのアーキテクチャとドライバーの実装の違いが原因である可能性があります (PostgreSQL の場合はpostgresql-42.2.5.jar 、MySQL の場合はmysql-connector-j-8.3.0.jar )。
プロジェクトのパート 2 では、アプリケーション プログラミング インターフェイス (API) のセットを公開するバックエンド ライブラリを構築することにより、データベース システムにアクセスする基本機能を提供することに焦点を当てています。追加のデータセットもインポートする必要があるため、更新されたデータベース実装が必要であることに注意してください ( ./Project2/DataImportにあります)。
[詳しい要件を読む]
./Project2/DataImport/src/main/sql/ddl.sqlで提供される DDL を使用して MySQL データベースをセットアップします。./Project2/DataImport/src/main/java/ImportScript.javaで提供されるスクリプトを使用してデータをインポートします。./Project2/ShenzhenMetro内) をビルドします (IntelliJ IDEA IDE を推奨します)

