chrono_lens
v1.1.1
これは、ONS コロナウイルス高速化指標 (例: 交通カメラの活動 - 2020 年 9 月 10 日) の一部として国家統計局データ サイエンス キャンパス ブログで公開されている交通カメラ分析プロジェクトのパブリック リポジトリとその基礎となる方法論です。このプロジェクトでは、スケーラブルなソリューションを実現するために Google Compute Platform (GCP) を利用しましたが、基礎となる方法論はプラットフォームに依存しません。このリポジトリには、GCP 指向の実装が含まれています。
コロナウイルス高速インジケーター用に生成された出力例を以下に示します。
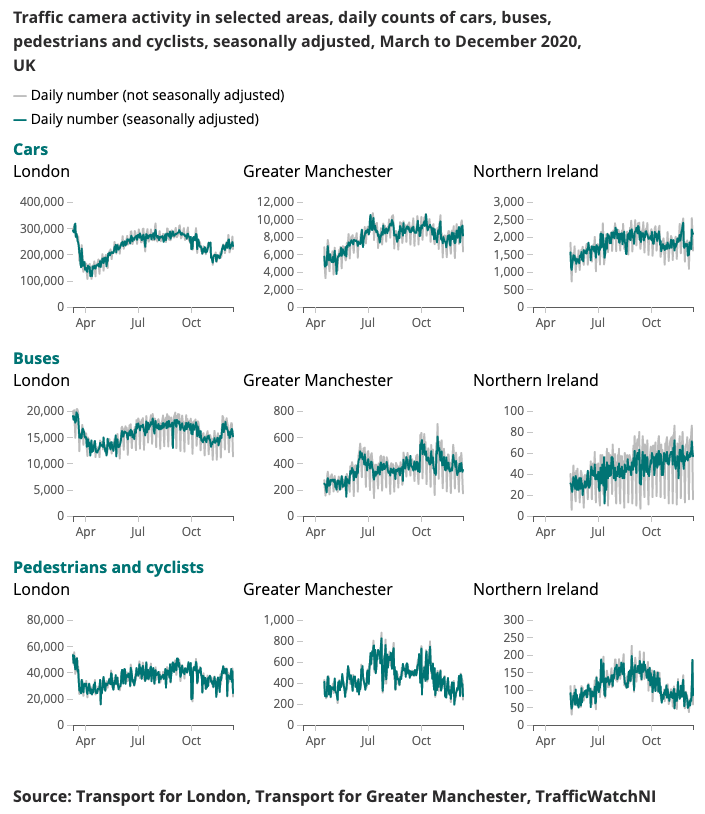
モビリティと行動の変化パターンをリアルタイムで理解することは、コロナウイルス(新型コロナウイルス感染症)に対する政府の対応の主な焦点となっている。データ サイエンス キャンパスは、社会的距離のレベルを推定し、ロックダウン条件が緩和されるにつれて社会と経済の好転を追跡する方法に関する洞察を提供する可能性のある代替データ ソースを探索してきました。
交通カメラは広く一般に利用可能なデータ ソースであり、交通専門家や一般の人々がインターネット経由で国内のさまざまな地域の交通の流れを評価できるようになります。交通カメラが生成する画像は一般に公開されており、解像度が低く、人や車両を個別に特定することはできません。これらは、公安や法執行機関の自動ナンバープレート認識 (ANPR) や交通速度の監視に使用される CCTV とは異なります。
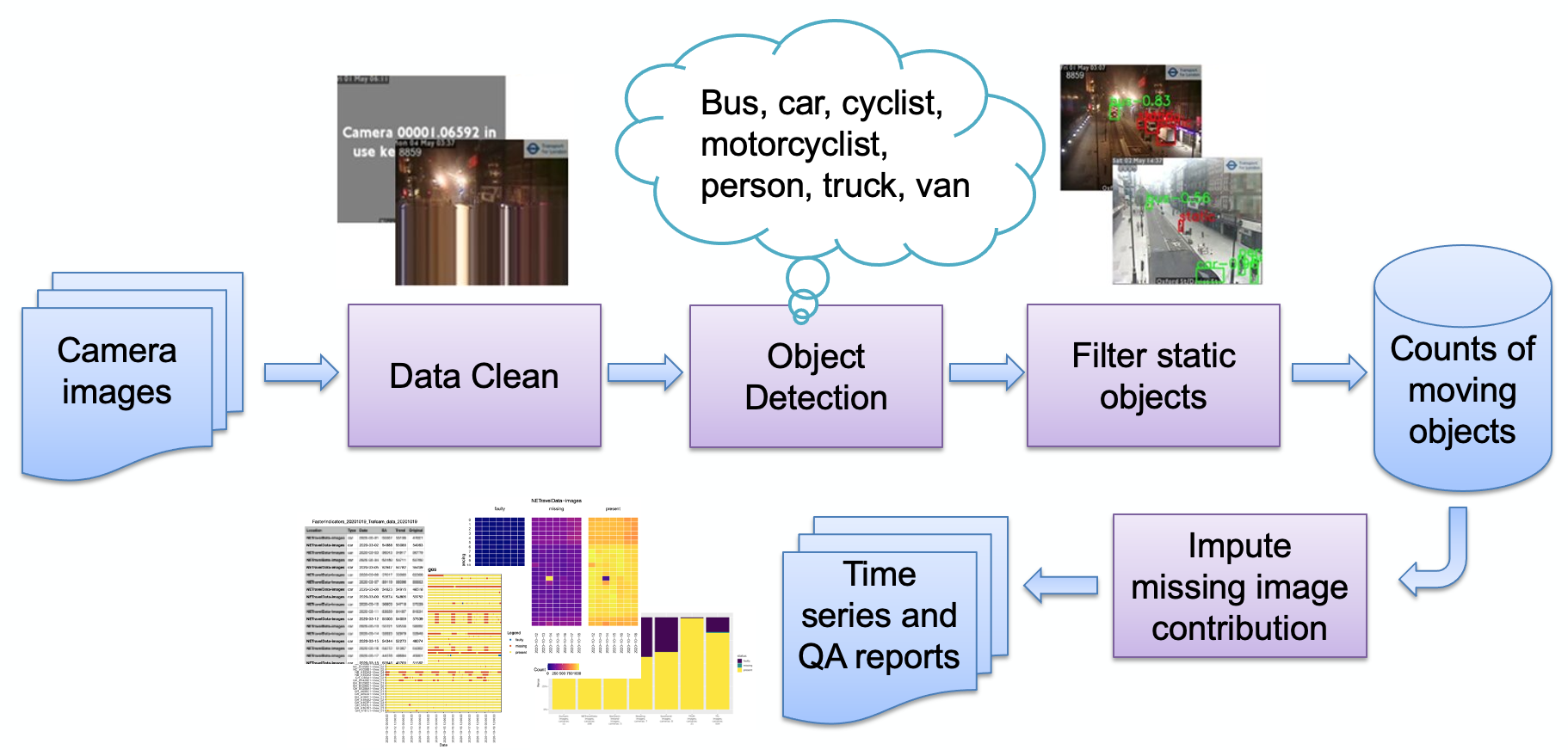
画像に示すように、パイプラインの主なステージは次のとおりです。
画像の取り込み
異常画像検出
物体検出
静的物体の検出
結果のカウントの保存
その後、カウントはさらに処理 (季節調整、欠損値の補完) され、必要に応じてレポートに変換されます。主要なパイプライン ステージを簡単に説明します。
一連のカメラ ソース (Web でホストされる JPEG 画像) がユーザーによって選択され、URL のリストとしてユーザーに提供されます。ロンドン交通局から公開画像を取得するためのサンプル コードと、ニューカッスル大学の都市天文台から直接 NE 交通データを取得するための専門コードが提供されています。
カメラはさまざまな理由 (システム障害、ローカル オペレーターによるフィードの無効化など) で利用できない場合があり、これらによりモデルが誤ったオブジェクト数を生成する可能性があります (たとえば、小さな塊が遠くのバスのように見える可能性があります)。そのような画像の例は次のとおりです。 
これまでのところ、これらの画像はすべて、(自然の風景の画像と比較して) 平らな背景色とオーバーレイされたテキストで構成される、非常に合成的な画像のパターンに従っています。現在、これらの画像は、色深度を減らし (類似した色を一緒にスナップする)、単一の色が占める画像の最大部分を調べることによって検出されます。これがしきい値を超えると、画像が合成であると判断され、欠陥があるとマークされます。エンコードが原因で、次のような他の障害が発生する可能性があります。 
ここでは、カメラのフィードが停止し、最後の「ライブ」行が繰り返されています。これは、画像の下の行が上の行と(しきい値内で)一致するかどうかをチェックすることで検出します。一致する場合は、上の次の行が一致するかどうかがチェックされ、行が一致しなくなるか行がなくなるまで繰り返されます。一致する行の数がしきい値を超えている場合、イメージは有用なデータを生成する可能性が低いため、欠陥があるとしてフラグが立てられます。
画像プロバイダーが異なれば、カメラが利用できないことを示す方法も異なることに注意してください。私たちの検出技術は、使用されている少数の色、つまり純粋な合成画像に依存しています。より自然な画像が使用される場合、私たちの技術は機能しない可能性があります。別の方法は、失敗した画像の「ライブラリ」を保持し、類似点を探すことです。これは、より自然な画像でより効果的に機能する可能性があります。
物体検出プロセスでは、ニューカッスル大学都市天文台が提供する事前トレーニング済み Faster-RCNN を使用して、静的物体と移動物体の両方を識別します。このモデルはイングランド北東部の 10,000 台の交通カメラ画像でトレーニングされ、ONS データ サイエンス キャンパスによってさらに検証され、モデルが英国の他の地域のカメラ画像でも使用できることが確認されました。次のオブジェクト タイプを検出します: 車、バン、トラック、バス、歩行者、自転車、オートバイ。
アクティビティの検出を目的としているため、時間情報を使用して静的なオブジェクトを除外することが重要です。画像は 10 分間隔でサンプリングされるため、ガウスの混合などのビデオ内の背景検出のための従来の方法は適していません。
物体検出中に分類された歩行者と車両は、背景にも表示される場合、静的として設定され、最終的なカウントから削除されます。以下の画像は、静的マスクの結果の例を示しています。画像 (a) の駐車中の車が静的であると識別され、削除されています。さらなる利点は、静的マスクが誤報の除去に役立つことです。たとえば、画像 (b) では、物体検出でゴミ箱が歩行者として誤認されましたが、静的な背景として除外されました。

結果は単純にテーブルとして保存され、カメラ ID、日付、時刻、オブジェクト タイプ (車、バン、歩行者など) ごとの関連カウント、画像に欠陥があるか画像が欠落している場合のスキーマが記録されます。
当初、システムは拡張性を可能にするためにクラウド ネイティブになるように設計されました。ただし、これには参入障壁が生じます。クラウド プロバイダーのアカウントが必要であり、インフラストラクチャを保護する方法などを知っている必要があります。これを念頭に置いて、スタンドアロン マシンで動作するようにコードもバックポートしました。 (または「ローカル ホスト」) を使用すると、関心のあるユーザーが自分のラップトップでシステムを簡単に実行できるようになります。両方の実装について以下に説明します。
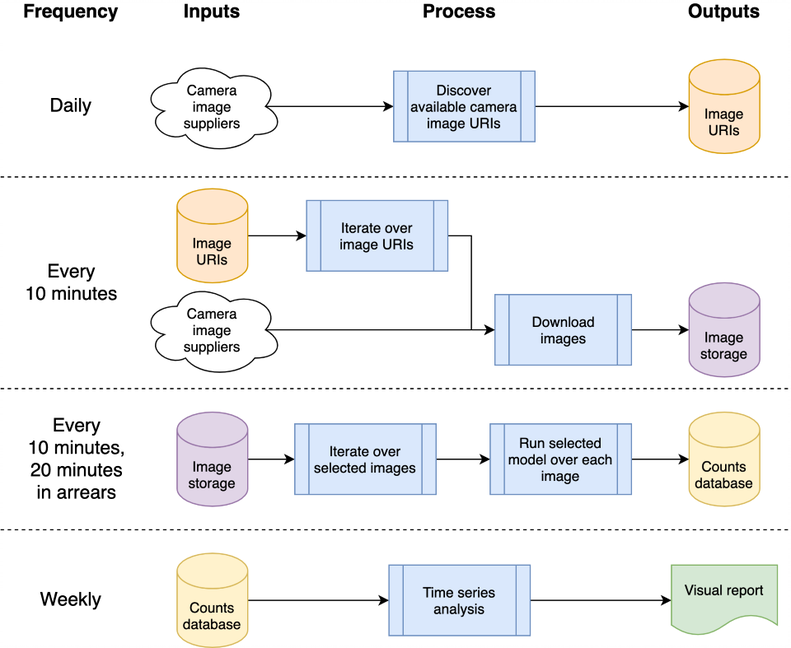
このアーキテクチャは、単一のマシンまたはクラウド システムにマッピングできます。私たちは Google Compute Platform (GCP) を使用することを選択しましたが、Amazon Web Services (AWS) や Microsoft の Azure などの他のプラットフォームでも比較的同等のサービスを提供します。
システムは「クラウド関数」としてホストされます。これは、破損を引き起こすことなく繰り返し呼び出すことができるスタンドアロンのステートレス コードです。これは、関数の堅牢性を高めるための重要な考慮事項です。毎日および「10 分ごと」の処理バーストは、GCP のスケジューラを使用して調整され、希望のスケジュールに従って GCP Pub/Sub トピックをトリガーします。 GCP クラウド関数はトピックに対して登録され、トピックがトリガーされるたびに開始されます。
画像を処理して車両や歩行者を検出すると、物体の数がデータベースに書き込まれ、後で時系列で分析できるようになります。データベースは、データ収集と時系列分析の間でデータを共有するために使用され、結合を軽減します。データ視覚化のためのデータスタジオなど、他の GCP プロダクトで幅広くサポートされているため、GCP 内で BigQuery をデータベースとして使用しています。ローカル ホストの実装では、毎日の CSV を比較して保存し、特定のデータベースやその他のインフラストラクチャへの依存を排除します。
GCP 関連のソース コードはcloudフォルダーに保存されます。これにより、画像がダウンロードされ、それを処理してオブジェクトをカウントし、カウントをデータベースに保存して、(毎週) 時系列分析を生成します。すべてのドキュメントとソース コードはcloudフォルダーに保存されます。アーキテクチャの概要と、スクリプトを使用して独自のインスタンスを GCP プロジェクト スペースにインストールする方法については、Cloud README.md を参照してください。プロジェクトは GitHub に統合でき、ローカル GitHub プロジェクトへのコミットから自動的に自動デプロイとテスト実行が可能になります。これは Cloud README.md にも記載されています。クラウド サポート コードもchrono_lens.gcloudモジュールに保存されており、 cloudフォルダー内の Cloud Function コードとともにコマンドライン スクリプトで GCP をサポートできるようになります。
スタンドアロンの単一マシン (「localhost」) コードは、 chrono_lens.localhostモジュールに含まれています。このプロセスは GCP バリアントと同じフローに従いますが、単一マシンを使用し、 chrono_lens.localhost内の各 Python ファイルが GCP の Cloud Functions にマップされます。詳細については、README-localhost.md を参照してください。
GCP とローカル ホストの両方の実装には少なくともローカル インストールが必要であることを前提として、システムをインストールするためのさまざまな手順と前提条件について説明します。
隔離された作業環境を可能にする仮想環境を作成することを強くお勧めします。良好な作業環境の例には、conda、pyenv、poerty などがあります。
依存関係はすでにrequirements.txtに含まれているので、これをpip経由でインストールしてください。
pip install -r requirements.txt
誤ってパスワードをコミットしないようにするには、機密情報がリポジトリに到達する前に git コミットが処理されないように、コミット前フックを使用することをお勧めします。 https://github.com/ukgovdatascience/govcookiecutter のコミット前フックを使用しました。
requirements.txt をインストールすると、事前コミット ツールがインストールされます。このツールを git に接続する必要があります。
pre-commit install
...これにより、 .pre-commit-config.yamlから構成がプルされます。
注意: check-added-large-filesコミット前テストには.pre-commit-config.yamlの最大 KB サイズがあり、RCNN モデル ファイル/tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pbを追加すると一時的に 60MB に増加します。 。その後、この制限は、賢明な「通常の」上限として 5Mb に戻ります。
先に進む前に、すべてのファイルに対してスイープを実行して、誤って存在しないことを確認することをお勧めします。
pre-commit run --all-files
これにより、既存の問題が報告されます。フックは編集されたファイルに対してのみ実行されるため便利です。
このプロジェクトは主にクラウド インフラストラクチャ経由で使用するように設計されていますが、ローカル アクセスとクラウド内の時系列の更新用のユーティリティ スクリプトがあります。これらのスクリプトはscripts/gcloudフォルダーにあり、各スクリプトについては以降の個別のセクションで説明します。詳細についてはscripts/gcloud/README.mdを参照してください。また、オプションの仮想マシンでの使用方法については、 cloud/README.mdで説明されています。
非クラウドの使用は、 scripts/localhostフォルダー内のスクリプトによってサポートされており、スタンドアロン マシンでchrono_lensシステムを使用する方法の詳細はREADME-localhost.mdに説明されています。スクリプトの使用方法の詳細については、 scripts/localhost/README.mdを参照してください。
スクリプトはchrono_lensフォルダー内のコードを使用することに注意してください。
| バージョン | 日付 | 注意事項 |
|---|---|---|
| 1.0.0 | 2021-06-08 | パブリックリポジトリの最初のリリース |
| 1.0.1 | 2021-09-21 | 孤立した画像のバグ修正、tensorflow バージョンのバンプ |
| 1.1.0 | ? | スタンドアロンの単一マシンに対する限定的なサポートを追加しました |
将来的に取り組む可能性のある分野をここに示します。これらの変更は調査されない可能性がありますが、私たちが検討した潜在的な改善点を人々に知ってもらうためにここにあります。
現在、GCP インフラストラクチャの作成には bash シェル スクリプトが使用されています。改善するには、Terraform などの IaC を使用します。これにより、ランタイム環境やメモリ制限が変更されたときに Cloud Build トリガーを手動で削除して再作成する必要がなく、Cloud Function 構成の変更などが簡素化されます。
現在の設計は、モデルが完成する前に画像を取得するという初期のユースケースに由来しているため、分析された画像だけではなく、利用可能なすべての画像がダウンロードされます。取り込みコストを節約するには、取り込みコードを分析 JSON ファイルと照合してクロスチェックし、それらのファイルのみをダウンロードする必要があります。これらのソースのいずれかが利用できなくなった場合、または新しいソースが利用可能になった場合には、アラートを生成する必要があります。
NETravelData の画像の夜間バックフィルにより、NETravelData 画像の約 40% が更新されるようです。数値が毎日のみ必要な場合は、定期的な更新の利点が薄れるため、クラウド関数distribute_ne_travel_data削除される可能性があります。
http asyncから PubSub への移行初期設計では、新しいモデルをテストするときに手動で操作するスクリプト (つまり、 batch_process_images.py ) を使用します。これにより、処理の成功 (または失敗) と画像の数が報告されます。これを行うには、結果を返す Cloud Function が適切に機能します。ただし、より効率的なアーキテクチャは、 distribute_json_sourcesとprocessed_scheduled関数を使用して内部で PubSub キューを使用し、現在の非同期呼び出しの階層ではなく、単一のワーカー関数によって消費される PubSub キューに作業を追加することです (スケールアウトするために 2 つの追加関数を使用します)。 )。
ニューカッスル大学の都市天文台は、私たちが使用する事前トレーニング済み Faster-RCNNN を提供しました (ローカル コピーは/tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pbに保存されています)。
データは、Open Government License 3.0 に基づいてライセンス供与された North East Urban Traffic Management and Control Open Data Service によって提供されます。画像は、Tyne and Wear Urban Traffic Management and Control に帰属します。
北東部のデータは、ニューカッスル大学都市天文台によってさらに処理され、ホストされています。その支援とアドバイスに感謝します。
データは TfL によって提供され、TfL オープン データによって強化されています。データは、Open Government License のバージョン 2.0 に基づいてライセンスされています。 TfL データには、OS データ © Crown 著作権およびデータベース権 2016 と、Geomni UK Map data © およびデータベース権 (2019) が含まれています。
このプロジェクトではさまざまなサードパーティ ライブラリが使用されています。これらは依存関係のページにリストされており、その貢献に感謝いたします。


