shap
v0.46.0
SHAP (SHapley Additive exPlanations)は、機械学習モデルの出力を説明するためのゲーム理論的アプローチです。ゲーム理論とその関連拡張からの古典的な Shapley 値を使用して、最適なクレジット割り当てを局所的な説明と結び付けます (詳細と引用については論文を参照してください)。
SHAP は PyPI または conda-forge からインストールできます。
pip インストール形状 または conda install -c conda-forge 形状
SHAP はあらゆる機械学習モデルの出力を説明できますが、私たちはツリー アンサンブル手法のための高速正確アルゴリズムを開発しました (Nature MI の論文を参照)。高速 C++ 実装は、 XGBoost 、 LightGBM 、 CatBoost 、 scikit-learn 、およびpysparkツリー モデルでサポートされています。
import xgboost
import shap
# train an XGBoost model
X , y = shap . datasets . california ()
model = xgboost . XGBRegressor (). fit ( X , y )
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap . Explainer ( model )
shap_values = explainer ( X )
# visualize the first prediction's explanation
shap . plots . waterfall ( shap_values [ 0 ])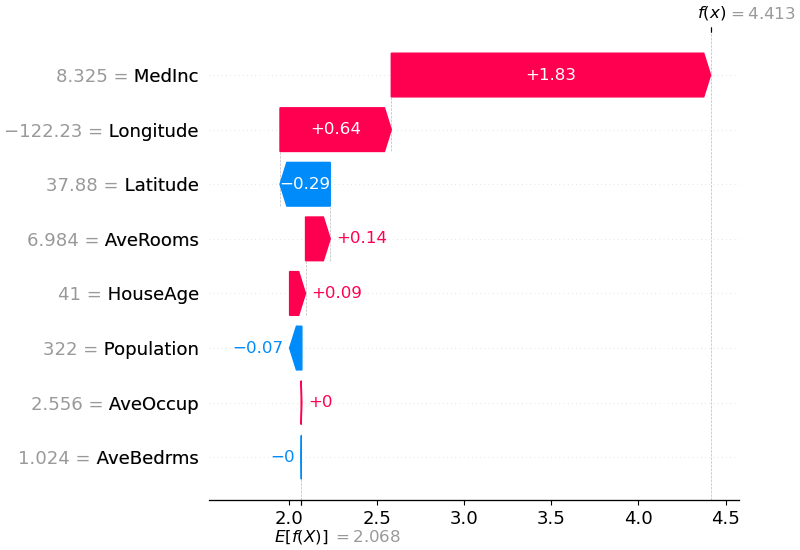
上記の説明は、モデル出力をベース値 (渡したトレーニング データセットにわたる平均モデル出力) からモデル出力にプッシュするのにそれぞれ寄与する特徴を示しています。予測を高くする特徴は赤で表示され、予測を低くする特徴は青で表示されます。同じ説明を視覚化するもう 1 つの方法は、力のプロットを使用することです (これらは Nature BME 論文で紹介されています)。
# visualize the first prediction's explanation with a force plot
shap . plots . force ( shap_values [ 0 ])
上に示したような多くの力プロットの説明を取得し、90 度回転して水平に積み重ねると、データセット全体の説明が表示されます (ノートブックではこのプロットは対話型です)。
# visualize all the training set predictions
shap . plots . force ( shap_values [: 500 ])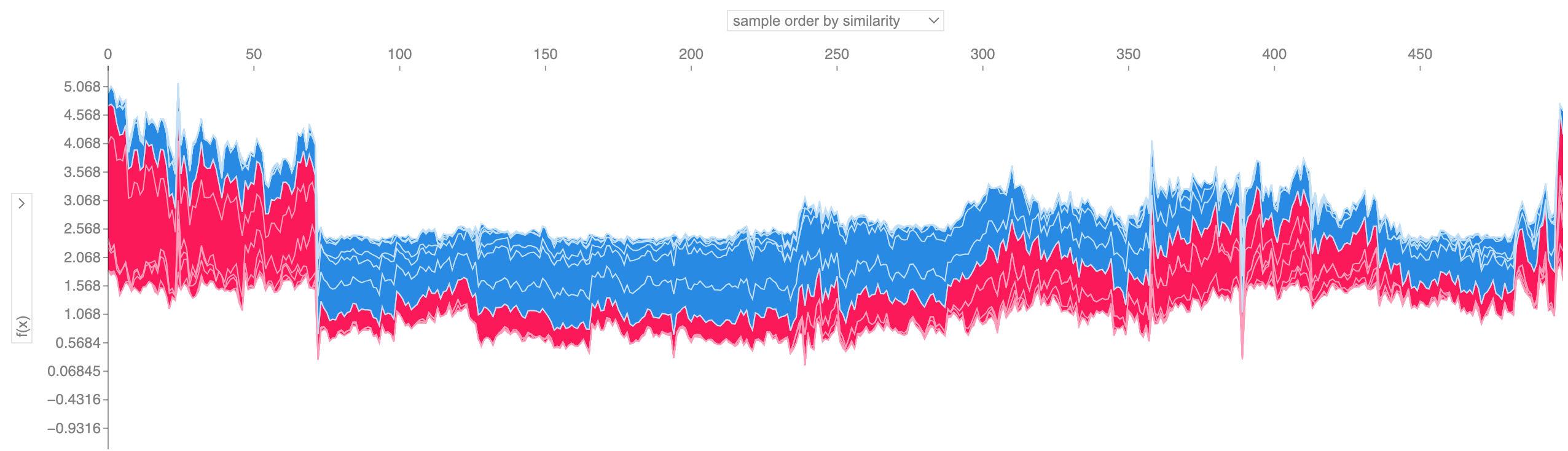
単一の特徴がモデルの出力にどのような影響を与えるかを理解するには、その特徴の SHAP 値とデータセット内のすべてのサンプルの特徴の値をプロットできます。 SHAP 値はモデル出力の変化に対するフィーチャの責任を表すため、以下のプロットは緯度の変化に伴う予測住宅価格の変化を表しています。単一の緯度値での垂直分散は、他の地物との相互作用効果を表します。これらの相互作用を明らかにするために、別の特徴によって色を付けることができます。説明テンソル全体をcolor引数に渡すと、散布図は色付けに最適な特徴を選択します。この場合、経度が選択されます。
# create a dependence scatter plot to show the effect of a single feature across the whole dataset
shap . plots . scatter ( shap_values [:, "Latitude" ], color = shap_values )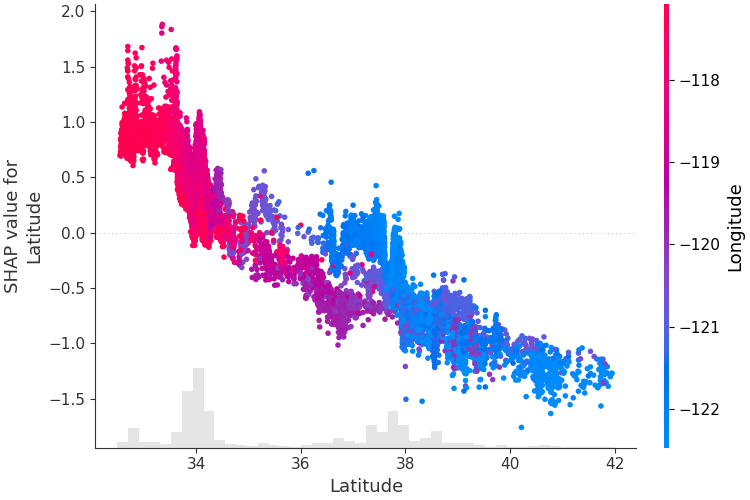
モデルにとってどの特徴が最も重要であるかの概要を得るために、すべてのサンプルのすべての特徴の SHAP 値をプロットできます。以下のプロットは、すべてのサンプルにわたる SHAP 値の大きさの合計によって特徴を並べ替えており、SHAP 値を使用して各特徴がモデル出力に与える影響の分布を示しています。色は特徴量を表します (赤が高、青が低)。これは、たとえば、収入の中央値が高いほど、予測される住宅価格が向上することを明らかにしています。
# summarize the effects of all the features
shap . plots . beeswarm ( shap_values )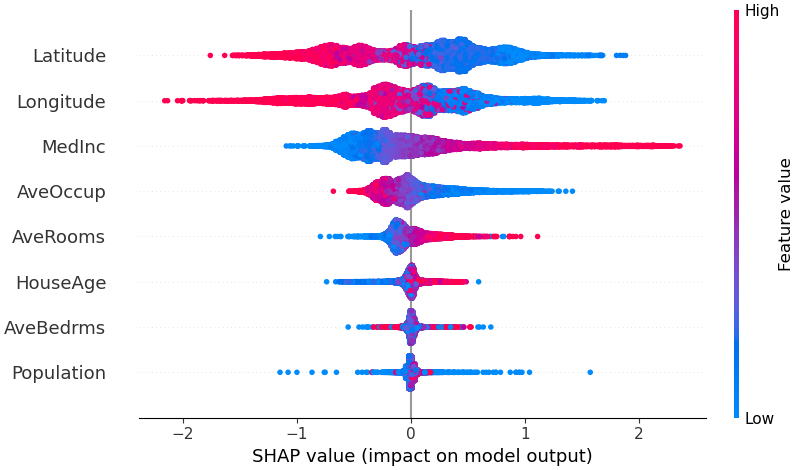
また、各特徴の SHAP 値の平均絶対値を取得して、標準の棒グラフを取得することもできます (マルチクラス出力の積み上げ棒を生成します)。
shap . plots . bar ( shap_values )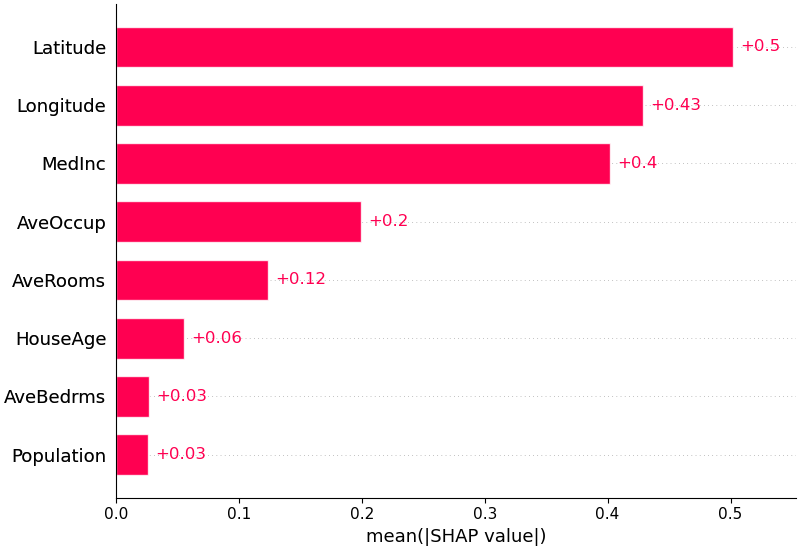
SHAP は、Hugging Face トランスフォーマー ライブラリにあるような自然言語モデルを特別にサポートしています。従来の Shapley 値に連合ルールを追加することで、非常に少ない関数評価を使用して大規模な現代の NLP モデルを説明するゲームを作成できます。この機能の使用は、サポートされているトランスフォーマー パイプラインを SHAP に渡すのと同じくらい簡単です。
import transformers
import shap
# load a transformers pipeline model
model = transformers . pipeline ( 'sentiment-analysis' , return_all_scores = True )
# explain the model on two sample inputs
explainer = shap . Explainer ( model )
shap_values = explainer ([ "What a great movie! ...if you have no taste." ])
# visualize the first prediction's explanation for the POSITIVE output class
shap . plots . text ( shap_values [ 0 , :, "POSITIVE" ])Deep SHAP は、SHAP NIPS 論文で説明されている DeepLIFT との接続に基づいて構築された、深層学習モデルの SHAP 値の高速近似アルゴリズムです。ここでの実装は、単一の参照値の代わりにバックグラウンド サンプルの分布を使用し、Shapley 方程式を使用して max、softmax、積、除算などのコンポーネントを線形化する点で、元の DeepLIFT とは異なります。これらの機能強化の一部も追加されていることに注意してください。 DeepLIFT に統合されて以来。 TensorFlow バックエンドを使用する TensorFlow モデルと Keras モデルがサポートされています (PyTorch の予備サポートもあります)。
# ...include code from https://github.com/keras-team/keras/blob/master/examples/demo_mnist_convnet.py
import shap
import numpy as np
# select a set of background examples to take an expectation over
background = x_train [ np . random . choice ( x_train . shape [ 0 ], 100 , replace = False )]
# explain predictions of the model on four images
e = shap . DeepExplainer ( model , background )
# ...or pass tensors directly
# e = shap.DeepExplainer((model.layers[0].input, model.layers[-1].output), background)
shap_values = e . shap_values ( x_test [ 1 : 5 ])
# plot the feature attributions
shap . image_plot ( shap_values , - x_test [ 1 : 5 ])上のプロットは、4 つの異なる画像に対する 10 個の出力 (数字 0 ~ 9) を説明しています。赤色のピクセルはモデルの出力を増加させ、青色のピクセルは出力を減少させます。入力画像は左側に示されており、それぞれの説明の後ろにほぼ透明なグレースケールの背景が表示されています。 SHAP 値の合計は、予想されるモデル出力 (バックグラウンド データセットの平均) と現在のモデル出力の差に等しくなります。 「ゼロ」イメージでは中央の空白が重要ですが、「フォー」イメージでは上部に接続がないため、9 ではなく 4 になることに注意してください。
Expected gradients は、Integrated Gradients、SHAP、および SmoothGrad のアイデアを単一の期待値方程式に結合します。これにより、データセット全体を (単一の参照値ではなく) バックグラウンド分布として使用できるようになり、局所的な平滑化が可能になります。各バックグラウンド データ サンプルと説明対象の現在の入力の間の線形関数を使用してモデルを近似し、入力特徴が独立していると仮定すると、予想される勾配によって近似の SHAP 値が計算されます。以下の例では、VGG16 ImageNet モデルの 7 番目の中間層が出力確率にどのような影響を与えるかを説明しました。
from keras . applications . vgg16 import VGG16
from keras . applications . vgg16 import preprocess_input
import keras . backend as K
import numpy as np
import json
import shap
# load pre-trained model and choose two images to explain
model = VGG16 ( weights = 'imagenet' , include_top = True )
X , y = shap . datasets . imagenet50 ()
to_explain = X [[ 39 , 41 ]]
# load the ImageNet class names
url = "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
fname = shap . datasets . cache ( url )
with open ( fname ) as f :
class_names = json . load ( f )
# explain how the input to the 7th layer of the model explains the top two classes
def map2layer ( x , layer ):
feed_dict = dict ( zip ([ model . layers [ 0 ]. input ], [ preprocess_input ( x . copy ())]))
return K . get_session (). run ( model . layers [ layer ]. input , feed_dict )
e = shap . GradientExplainer (
( model . layers [ 7 ]. input , model . layers [ - 1 ]. output ),
map2layer ( X , 7 ),
local_smoothing = 0 # std dev of smoothing noise
)
shap_values , indexes = e . shap_values ( map2layer ( to_explain , 7 ), ranked_outputs = 2 )
# get the names for the classes
index_names = np . vectorize ( lambda x : class_names [ str ( x )][ 1 ])( indexes )
# plot the explanations
shap . image_plot ( shap_values , to_explain , index_names ) 2 つの入力イメージの予測は、上のプロットで説明されています。赤いピクセルはクラスの確率を高める正の SHAP 値を表し、青のピクセルはクラスの確率を下げる負の SHAP 値を表します。 ranked_outputs=2使用することで、各入力に対して最も可能性の高い 2 つのクラスのみを説明します (これにより、1,000 のクラスすべてを説明する必要がなくなります)。
カーネル SHAP は、特別に重み付けされた局所線形回帰を使用して、任意のモデルの SHAP 値を推定します。以下は、古典的なアヤメ データセットのマルチクラス SVM を説明する簡単な例です。
import sklearn
import shap
from sklearn . model_selection import train_test_split
# print the JS visualization code to the notebook
shap . initjs ()
# train a SVM classifier
X_train , X_test , Y_train , Y_test = train_test_split ( * shap . datasets . iris (), test_size = 0.2 , random_state = 0 )
svm = sklearn . svm . SVC ( kernel = 'rbf' , probability = True )
svm . fit ( X_train , Y_train )
# use Kernel SHAP to explain test set predictions
explainer = shap . KernelExplainer ( svm . predict_proba , X_train , link = "logit" )
shap_values = explainer . shap_values ( X_test , nsamples = 100 )
# plot the SHAP values for the Setosa output of the first instance
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ][ 0 ,:], X_test . iloc [ 0 ,:], link = "logit" )上記の説明では、モデル出力をベース値 (渡したトレーニング データセットにわたる平均モデル出力) からゼロに近づけるのにそれぞれ寄与する 4 つの特徴を示しています。クラス ラベルを上位に押し上げるフィーチャがある場合は、赤で表示されます。
上に示したような多くの説明を 90 度回転して水平に積み重ねると、データセット全体の説明が表示されます。これは、iris テスト セットのすべての例に対して以下で行うこととまったく同じです。
# plot the SHAP values for the Setosa output of all instances
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ], X_test , link = "logit" )SHAP 相互作用値は、SHAP 値を高次の相互作用に一般化したものです。ペアごとの相互作用の高速で正確な計算はshap.TreeExplainer(model).shap_interaction_values(X)を使用してツリー モデルに実装されます。これにより、すべての予測の行列が返されます。主効果は対角線上にあり、交互作用効果は対角線上にありません。これらの値は、男性の死亡リスクの増加が 60 歳でどのようにピークに達するかなど、興味深い隠された関係を明らかにすることがよくあります (詳細については、NHANES ノートを参照してください)。
以下のノートブックは、SHAP のさまざまな使用例を示しています。オリジナルのノートブックを自分で試してみたい場合は、リポジトリのノートブック ディレクトリ内を調べてください。
Tree SHAP の実装。ツリーおよびツリーのアンサンブルの SHAP 値を計算する高速かつ正確なアルゴリズムです。
XGBoost と SHAP 相互作用値を使用した NHANES 生存モデル- 20 年間の追跡調査からの死亡率データを使用して、このノートブックは、XGBoost とshap使用して複雑な危険因子の関係を明らかにする方法を示します。
LightGBM を使用した国勢調査の収入分類- 標準の成人国勢調査の収入データセットを使用して、このノートブックは LightGBM で勾配ブースティング ツリー モデルをトレーニングし、次にshap使用して予測を説明します。
XGBoost を使用したリーグ オブ レジェンドの勝利予測- リーグ オブ レジェンドの 180,000 のランクマッチの Kaggle データセットを使用して、XGBoost を使用して勾配ブースティング ツリー モデルをトレーニングおよび説明し、プレイヤーが試合に勝つかどうかを予測します。
Deep SHAP の実装。SHAP と DeepLIFT アルゴリズムの間の接続に基づいて、深層学習モデルの SHAP 値を計算するための高速 (ただし近似のみ) アルゴリズムです。
Keras を使用した MNIST 数字分類- MNIST 手書き認識データセットを使用して、このノートブックは Keras でニューラル ネットワークをトレーニングし、次にshap使用して予測を説明します。
IMDB センチメント分類用の Keras LSTM - このノートブックは、IMDB テキストセンチメント分析データセット上で Keras を使用して LSTM をトレーニングし、次にshap使用した予測について説明します。
深層学習モデルの SHAP 値を近似するための予想される勾配の実装。これは、SHAP と統合勾配アルゴリズム間の接続に基づいています。 GradientExplainer は DeepExplainer よりも遅く、異なる近似仮定を行います。
独立した特徴を持つ線形モデルの場合、正確な SHAP 値を分析的に計算できます。特徴共分散行列を推定したい場合は、特徴相関を考慮することもできます。 LinearExplainer はこれらのオプションの両方をサポートしています。
カーネル SHAP の実装。モデルに依存せずに任意のモデルの SHAP 値を推定する方法です。 KernelExplainer はモデル タイプについて何も仮定しないため、他のモデル タイプ固有のアルゴリズムよりも遅くなります。
scikit-learn を使用した国勢調査の収入分類- 標準の成人国勢調査の収入データセットを使用して、このノートブックは scikit-learn を使用して k 最近傍分類器をトレーニングし、次にshapを使用して予測を説明します。
Keras を使用した ImageNet VGG16 モデル- 古典的な VGG16 畳み込みニューラル ネットワークの画像予測について説明します。これは、モデルに依存しないカーネル SHAP メソッドをスーパーピクセルでセグメント化された画像に適用することで機能します。
アヤメ分類- 人気のあるアヤメ種データセットを使用した基本的なデモンストレーション。 scikit-learn のshapを使用した 6 つの異なるモデルからの予測について説明します。
これらのノートブックは、特定の関数とオブジェクトの使用方法を包括的に示します。
shap.decision_plotおよびshap.multioutput_decision_plot
shap.dependence_plot
ライム:リベイロ、マルコ・トゥーリオ、サミール・シン、カルロス・ゲゲリン。 「なぜあなたを信頼する必要があるのですか?: 分類器の予測について説明します。」知識発見とデータマイニングに関する第 22 回 ACM SIGKDD 国際会議の議事録。 ACM、2016 年。
Shapley のサンプリング値: Strumbelj、Erik、および Igor Konnenko。 「予測モデルと個々の予測を機能貢献とともに説明します。」知識と情報システム 41.3 (2014): 647-665。
DeepLIFT:シュリクマー、アバンティ、ペイトン グリーンサイド、アンシュル クンダジェ。 「アクティベーションの違いを伝播することで重要な機能を学習します。」 arXiv プレプリント arXiv:1704.02685 (2017)。
QII:ダッタ、アヌパム、シャヤック・セン、ヤイール・ジック。 「定量的入力の影響によるアルゴリズムの透明性: 学習システムの理論と実験」セキュリティとプライバシー (SP)、2016 IEEE シンポジウム開催。 IEEE、2016 年。
層ごとの関連性の伝播: Bach、Sebastian、他。 「層ごとの関連性伝播による非線形分類器の決定に関するピクセルごとの説明について」 PloS one 10.7 (2015): e0130140。
Shapley 回帰値: Lipovetsky、Stan、Michael Conklin。 「ゲーム理論アプローチにおける回帰分析」ビジネスと産業における応用確率モデル 17.4 (2001): 319-330。
ツリー通訳:サーバス、安藤。ランダムフォレストの解釈。 http://blog.datadive.net/interpreting-random-forests/
このパッケージで使用されているアルゴリズムと視覚化は、主にワシントン大学の Su-In Lee の研究室と Microsoft Research の研究から生まれました。研究で SHAP を使用する場合は、適切な論文を引用していただければ幸いです。
force_plot視覚化と医療アプリケーションについては、Nature Biomedical Engineering の論文 (bibtex; 無料アクセス) を読んだり引用したりできます。

