Candle は、パフォーマンス (GPU サポートを含む) と使いやすさに重点を置いた、Rust 用の最小限の ML フレームワークです。オンライン デモをお試しください: Whisper、LLaMA2、T5、yolo、Segment Anything。
「インストール」の説明に従って、 candle-coreが正しくインストールされていることを確認してください。
単純な行列の乗算を実行する方法を見てみましょう。 myapp/src/main.rsファイルに次の内容を書き込みます。
use candle_core :: { Device , Tensor } ;
fn main ( ) -> Result < ( ) , Box < dyn std :: error :: Error > > {
let device = Device :: Cpu ;
let a = Tensor :: randn ( 0f32 , 1. , ( 2 , 3 ) , & device ) ? ;
let b = Tensor :: randn ( 0f32 , 1. , ( 3 , 4 ) , & device ) ? ;
let c = a . matmul ( & b ) ? ;
println ! ( "{c}" ) ;
Ok ( ( ) )
} cargo run Tensor[[2, 4], f32]の形状のテンソルを表示する必要があります。
Cuda サポートを備えたcandleをインストールしたら、GPU 上にdeviceを定義するだけです。
- let device = Device::Cpu;
+ let device = Device::new_cuda(0)?;より高度な例については、次のセクションをご覧ください。
これらのオンライン デモはすべてブラウザ内で実行されます。
最先端のモデルを使用したコマンド ライン ベースの例もいくつか提供します。
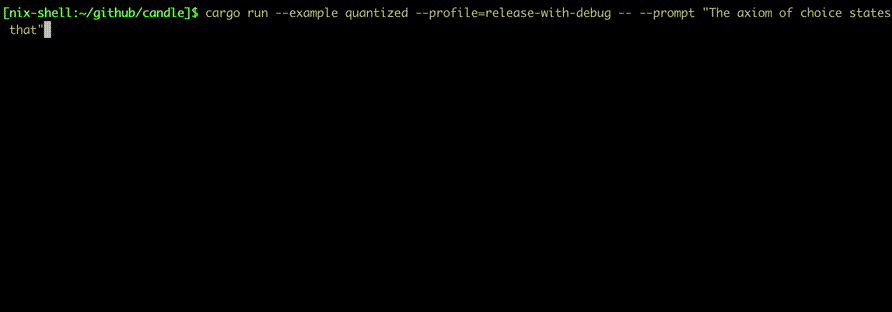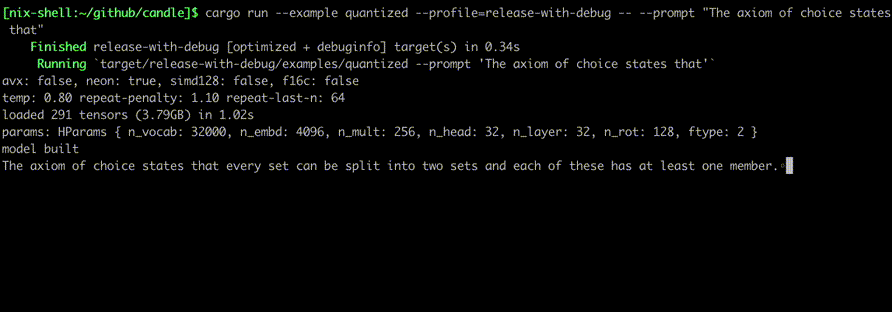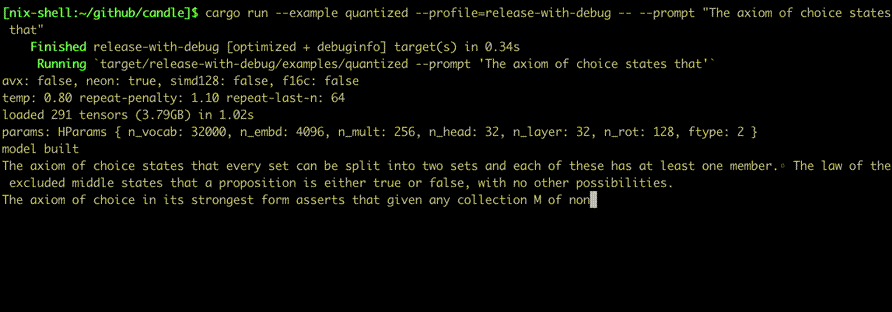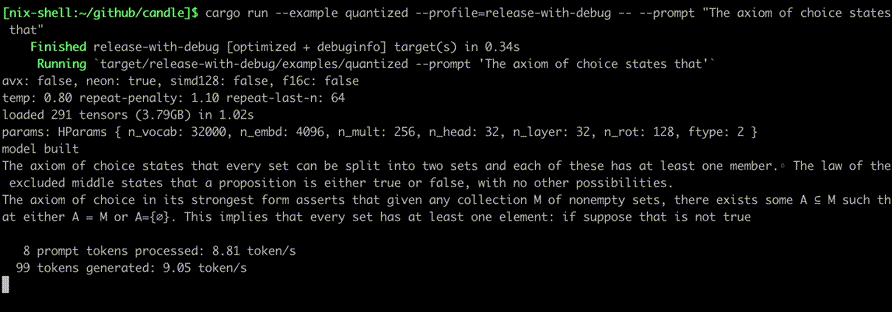





次のようなコマンドを使用して実行します。
cargo run --example quantized --release
CUDAを使用するには、コマンド ライン例に--features cudaを追加します。 cuDNN がインストールされている場合は、 --features cudnn使用するとさらに高速化できます。
ウィスパーと llama2.c の wasm の例もいくつかあります。これらは、 trunkで構築することも、オンラインで試すこともできます: Whisper、llama2、T5、Phi-1.5、および Phi-2、Segment Anything Model。
LLaMA2 の場合は、次のコマンドを実行して重みファイルを取得し、テスト サーバーを起動します。
cd candle-wasm-examples/llama2-c
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/model.bin
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/tokenizer.json
trunk serve --release --port 8081次に、http://localhost:8081/ に移動します。
candle-tutorial : PyTorch モデルを Candle に変換する方法を示す非常に詳細なチュートリアル。candle-lora : Candle 用の効率的かつ人間工学に基づいた LoRA 実装。 candle-loraが持っていますoptimisers : 勢いのある SGD、AdaGrad、AdaDelta、AdaMax、NAdam、RAdam、および RMSprop を含むオプティマイザーのコレクション。candle-vllm : OpenAI 互換 API サーバーを含む、ローカル LLM の推論とサービスを提供するための効率的なプラットフォーム。candle-ext : 現在 Candle で利用できない PyTorch 関数を提供する Candle の拡張ライブラリ。candle-coursera-ml : Coursera の機械学習スペシャライゼーション コースからの ML アルゴリズムの実装。kalosm : 制御された生成、カスタム サンプラー、メモリ内ベクトル データベース、オーディオ トランスクリプションなどをサポートする、ローカルの事前トレーニング済みモデルとインターフェイスするための Rust のマルチモーダル メタ フレームワーク。candle-sampling : Candle のサンプリング手法。gpt-from-scratch-rs : YouTube にある Andrej Karpathy のLet's build GPTチュートリアルの移植版で、おもちゃの問題に関する Candle API を紹介しています。candle-einops : Python einops ライブラリの純粋な Rust 実装。atoma-infer : 大規模な高速推論のための Rust ライブラリ。効率的なアテンション計算のための FlashAttendant2、効率的な KV キャッシュ メモリ管理のための PagedAttendance、およびマルチ GPU サポートを活用します。 OpenAI APIに対応しています。このリストに追加がある場合は、プル リクエストを送信してください。
チートシート:
| PyTorch の使用 | キャンドルの使い方 | |
|---|---|---|
| 創造 | torch.Tensor([[1, 2], [3, 4]]) | Tensor::new(&[[1f32, 2.], [3., 4.]], &Device::Cpu)? |
| 創造 | torch.zeros((2, 2)) | Tensor::zeros((2, 2), DType::F32, &Device::Cpu)? |
| インデックス作成 | tensor[:, :4] | tensor.i((.., ..4))? |
| 運営 | tensor.view((2, 2)) | tensor.reshape((2, 2))? |
| 運営 | a.matmul(b) | a.matmul(&b)? |
| 算術 | a + b | &a + &b |
| デバイス | tensor.to(device="cuda") | tensor.to_device(&Device::new_cuda(0)?)? |
| Dタイプ | tensor.to(dtype=torch.float16) | tensor.to_dtype(&DType::F16)? |
| 保存 | torch.save({"A": A}, "model.bin") | candle::safetensors::save(&HashMap::from([("A", A)]), "model.safetensors")? |
| 読み込み中 | weights = torch.load("model.bin") | candle::safetensors::load("model.safetensors", &device) |
Tensor構造体定義Candle の中心的な目標は、サーバーレス推論を可能にすることです。 PyTorch のような完全な機械学習フレームワークは非常に大きいため、クラスター上でのインスタンスの作成が遅くなります。 Candle を使用すると、軽量のバイナリをデプロイできます。
次に、Candle を使用すると、実稼働ワークロードからPython を削除できます。 Python のオーバーヘッドはパフォーマンスに重大な悪影響を与える可能性があり、GIL は頭痛の種として悪名高いです。
最後に、Rustはカッコいいです! HF エコシステムの多くには、セーフテンサーやトークナイザーなどの Rust クレートがすでにあります。
dfdx は、型にシェイプが含まれている強力なクレートです。これにより、コンパイラーが形状の不一致についてすぐに通知するため、多くの問題を回避できます。ただし、一部の機能は依然として夜間に必要であり、Rust の専門家以外にとってコードを記述するのは少し難しい場合があることがわかりました。
私たちはランタイム用に他のコア クレートを活用して貢献しているため、両方のクレートが相互にメリットを享受できることを願っています。
burn は複数のバックエンドを利用できる一般的なクレートなので、ワークロードに最適なエンジンを選択できます。
tch-rs Rust の torch ライブラリへのバインディング。非常に多用途ですが、トーチ ライブラリ全体をランタイムに組み込みます。 tch-rsの主な貢献者は、 candleの開発にも携わっています。
mkl またはアクセラレーション機能を使用してバイナリ/テストをコンパイルするときに欠落しているシンボルが発生した場合、たとえば mkl の場合は次のようになります。
= note: /usr/bin/ld: (....o): in function `blas::sgemm':
.../blas-0.22.0/src/lib.rs:1944: undefined reference to `sgemm_' collect2: error: ld returned 1 exit status
= note: some `extern` functions couldn't be found; some native libraries may need to be installed or have their path specified
= note: use the `-l` flag to specify native libraries to link
= note: use the `cargo:rustc-link-lib` directive to specify the native libraries to link with Cargo
または加速の場合:
Undefined symbols for architecture arm64:
"_dgemm_", referenced from:
candle_core::accelerate::dgemm::h1b71a038552bcabe in libcandle_core...
"_sgemm_", referenced from:
candle_core::accelerate::sgemm::h2cf21c592cba3c47 in libcandle_core...
ld: symbol(s) not found for architecture arm64
これは、mkl ライブラリを有効にするために必要なリンカー フラグが欠落していることが原因である可能性があります。バイナリの先頭に mkl に次のコードを追加してみてください。
extern crate intel_mkl_src ;または加速の場合:
extern crate accelerate_src ; Error: request error: https://huggingface.co/meta-llama/Llama-2-7b-hf/resolve/main/tokenizer.json: status code 401
これは、LLaMA-v2 モデルに対する権限がないことが原因である可能性があります。これを修正するには、huggingface-hub に登録し、LLaMA-v2 モデル条件を受け入れ、認証トークンを設定する必要があります。詳細については、問題 #350 を参照してください。
In file included from kernels/flash_fwd_launch_template.h:11:0,
from kernels/flash_fwd_hdim224_fp16_sm80.cu:5:
kernels/flash_fwd_kernel.h:8:10: fatal error: cute/algorithm/copy.hpp: No such file or directory
#include <cute/algorithm/copy.hpp>
^~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
Error: nvcc error while compiling:
Cutlass は git サブモジュールとして提供されているため、次のコマンドを実行して適切にチェックインすることができます。
git submodule update --init /usr/include/c++/11/bits/std_function.h:530:146: error: parameter packs not expanded with ‘...’:
これは、Cuda コンパイラによって引き起こされる gcc-11 のバグです。これを修正するには、別のサポートされている gcc バージョン (gcc-10 など) をインストールし、NVCC_CCBIN 環境変数でコンパイラへのパスを指定します。
env NVCC_CCBIN=/usr/lib/gcc/x86_64-linux-gnu/10 cargo ...
Couldn't compile the test.
---- .candle-booksrcinferencehub.md - Using_the_hub::Using_in_a_real_model_ (line 50) stdout ----
error: linking with `link.exe` failed: exit code: 1181
//very long chain of linking
= note: LINK : fatal error LNK1181: cannot open input file 'windows.0.48.5.lib'
プロジェクト ターゲットの外部にある可能性のあるすべてのネイティブ ライブラリを必ずリンクしてください。たとえば、mdbook テストを実行するには、次を実行する必要があります。
mdbook test candle-book -L .targetdebugdeps `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.42.2lib `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.48.5lib
これは、モデルが/mnt/cからロードされていることが原因である可能性があります。詳細については stackoverflow を参照してください。
RUST_BACKTRACE=1設定すると、ローソク足エラーが生成されたときにバックトレースが提供されます。
Err 値on an Result::unwrap() called次のようなエラーが発生した場合value: LoadLibraryExW { source: Os { code: 126, kind: Uncategorized, message: "The specified module could not be found." } } Windows ではvalue: LoadLibraryExW { source: Os { code: 126, kind: Uncategorized, message: "The specified module could not be found." } } 。修正するには、これら 3 つのファイルをコピーして名前を変更します (パス内にあることを確認してください)。パスは cuda のバージョンによって異なります。 c:WindowsSystem32nvcuda.dll -> cuda.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincublas64_12.dll -> cublas.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincurand64_10.dll -> curand.dll


