whisperX
3.1.1
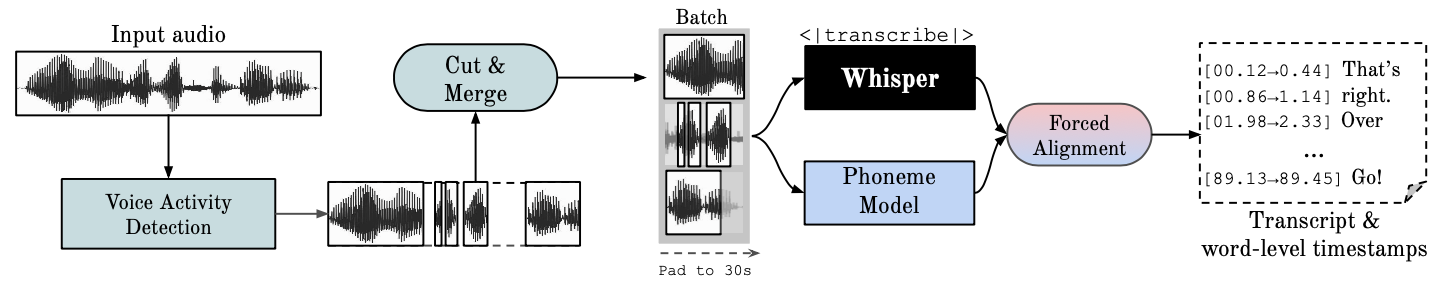
このリポジトリは、単語レベルのタイムスタンプと話者ダイアリゼーションによる高速自動音声認識 (large-v2 で 70 倍リアルタイム) を提供します。
Whisper はOpenAI によって開発された ASR モデルで、多様な音声の大規模なデータセットでトレーニングされています。非常に正確な文字起こしが生成されますが、対応するタイムスタンプは単語単位ではなく発話レベルであり、数秒間不正確になる可能性があります。 OpenAI の Whisper はバッチ処理をネイティブにサポートしていません。
音素ベースの ASR ある単語を別の単語から区別する音声の最小単位、たとえば「タップ」の要素 p を認識するように微調整された一連のモデル。一般的なモデル例は wav2vec2.0 です。
強制アライメントとは、正書法トランスクリプションをオーディオ録音に合わせて調整し、電話レベルのセグメンテーションを自動的に生成するプロセスを指します。
音声アクティビティ検出 (VAD) は、人間の音声の有無を検出することです。
話者ダイアライゼーションは、人間の音声を含むオーディオ ストリームを、各話者のアイデンティティに従って均一なセグメントに分割するプロセスです。
GPU を実行するには、NVIDIA ライブラリ cuBLAS 11.x および cuDNN 8.x がシステムにインストールされている必要があります。 CTranslate2 のドキュメントを参照してください。
conda create --name whisperx python=3.10
conda activate whisperx
conda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
他の方法については、こちらをご覧ください。
pip install git+https://github.com/m-bain/whisperx.git
すでにインストールされている場合は、パッケージを最新のコミットに更新します
pip install git+https://github.com/m-bain/whisperx.git --upgrade
このパッケージを変更したい場合は、クローンを作成して編集可能モードでインストールします。
$ git clone https://github.com/m-bain/whisperX.git
$ cd whisperX
$ pip install -e .
ffmpeg、Rust などをインストールする必要がある場合もあります。https://github.com/openai/whisper#setup の openAI の手順に従ってください。
Speaker Diarization を有効にするには、ここから生成できる Hugging Face アクセス トークン (読み取り) を--hf_token引数の後に含めて、次のモデルのユーザー同意書に同意します: Segmentation および Speaker-Diarization-3.1 (Speaker を使用することを選択した場合) - ダイアライゼーション 2.x、代わりにここの要件に従ってください。)
注記
2023 年 10 月 11 日の時点で、whisperX の pyannote/Speaker-Diarization-3.0 のパフォーマンスの低下に関する既知の問題があります。これは、faster-whisper と pyannote-audio 3.0.0 の間の依存関係の競合が原因です。詳細と考えられる回避策については、この問題を参照してください。
サンプルセグメントでウィスパーを実行します (デフォルトのパラメータを使用し、スモールウィスパー) --highlight_words Trueを追加して、.srt ファイル内の単語のタイミングを視覚化します。
whisperx examples/sample01.wav
WhisperX をwav2vec2.0 ラージに強制的にアライメントして使用した結果:
これを、多くの文字起こしが同期していない、箱から出されたオリジナルのウィスパーと比較してください。
タイムスタンプの精度を高めるには、より高い GPU メモリを犠牲にして、より大きなモデルを使用します (より大きなアライメント モデルはあまり役に立たないと考えられています。論文を参照してください)。
whisperx examples/sample01.wav --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --batch_size 4
トランスクリプトにスピーカー ID のラベルを付けるには (既知の場合はスピーカー数を設定します。例: --min_speakers 2 --max_speakers 2 ):
whisperx examples/sample01.wav --model large-v2 --diarize --highlight_words True
GPU ではなく CPU で実行するには (および Mac OS X で実行するには):
whisperx examples/sample01.wav --compute_type int8
音素 ASR アラインメント モデルは言語固有であり、テストされた言語の場合、これらのモデルは torchaudio パイプラインまたは ハグフェイスから自動的に選択されます。 --languageコードを渡して、 Whisper --model large使用するだけです。
現在、デフォルトのモデルは{en, fr, de, es, it, ja, zh, nl, uk, pt}に対して提供されています。検出された言語がこのリストにない場合は、huggingface モデル ハブから音素ベースの ASR モデルを見つけて、データでテストする必要があります。
whisperx --model large-v2 --language de examples/sample_de_01.wav
他の言語での例については、こちらをご覧ください。
import whisperx
import gc
device = "cuda"
audio_file = "audio.mp3"
batch_size = 16 # reduce if low on GPU mem
compute_type = "float16" # change to "int8" if low on GPU mem (may reduce accuracy)
# 1. Transcribe with original whisper (batched)
model = whisperx . load_model ( "large-v2" , device , compute_type = compute_type )
# save model to local path (optional)
# model_dir = "/path/"
# model = whisperx.load_model("large-v2", device, compute_type=compute_type, download_root=model_dir)
audio = whisperx . load_audio ( audio_file )
result = model . transcribe ( audio , batch_size = batch_size )
print ( result [ "segments" ]) # before alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model
# 2. Align whisper output
model_a , metadata = whisperx . load_align_model ( language_code = result [ "language" ], device = device )
result = whisperx . align ( result [ "segments" ], model_a , metadata , audio , device , return_char_alignments = False )
print ( result [ "segments" ]) # after alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model_a
# 3. Assign speaker labels
diarize_model = whisperx . DiarizationPipeline ( use_auth_token = YOUR_HF_TOKEN , device = device )
# add min/max number of speakers if known
diarize_segments = diarize_model ( audio )
# diarize_model(audio, min_speakers=min_speakers, max_speakers=max_speakers)
result = whisperx . assign_word_speakers ( diarize_segments , result )
print ( diarize_segments )
print ( result [ "segments" ]) # segments are now assigned speaker IDs 独自の GPU にアクセスできない場合は、上記のリンクを使用して WhisperX を試してください。
バッチ処理とアライメント、VAD の効果、および選択したアライメント モデルの詳細については、プレプリント ペーパーを参照してください。
GPU メモリ要件を軽減するには、次のいずれかを試してください (2. と 3. は品質に影響する可能性があります)。
--batch_size 4 。--model base--compute_type int8を使用するopenai の Whisper との転写の違い:
--without_timestamps True 。これにより、バッチ内のサンプルごとに 1 つの前方パスが保証されます。ただし、これによりデフォルトのウィスパー出力との不一致が生じる可能性があります。--condition_on_prev_textはデフォルトでFalseに設定されます (幻覚を軽減します)。 あなたが多言語を話す場合、このプロジェクトに貢献できる主な方法は、huggingface で音素モデルを見つけて (または独自にトレーニングして)、ターゲット言語の音声でテストすることです。結果が良好であると思われる場合は、プル リクエストとその成功を示すいくつかの例を送信します。
このプロジェクトはすでに当初の研究範囲から逸脱しつつあるため、バグ発見とプルリクエストもこのプロジェクトを継続するために非常に高く評価されています。
多言語の初期化
言語検出に基づいた自動調整モデル選択
Pythonの使用法
話者ダイアライゼーションの組み込み
モデルフラッシュ、GPUメモリリソースが少ない場合
より高速なウィスパー バックエンド
max-line などを追加します。(openai の Whisper utils.py) を参照してください。
文レベルのセグメント (nltk ツールボックス)
アライメントロジックを改善する
ダイアライゼーションと単語のハイライトを使用して例を更新する
字幕 .ass 出力 <- これを元に戻す (v3 で削除)
ベンチマークコードの追加 (spd/WER および単語セグメンテーション用の TEDLIUM)
代替 VAD オプションとして silero-vad を許可する
日記化(単語レベル)を改善します。最初に思ったよりも大変でした...
ご質問については、[email protected] までご連絡ください。
この研究と私の博士号は、VGG (Visual Geometry Group) とオックスフォード大学によってサポートされています。
もちろん、これは openAI のささやきに基づいて構築されています。強制アライメントに関する PyTorch チュートリアルから重要なアライメント コードを借用し、素晴らしい pyannote VAD / Diarization を使用します https://github.com/pyannote/pyannote-audio
[pyannote audio][https://github.com/pyannote/pyannote-audio] の貴重な VAD およびダイアライゼーション モデル
Faster-Whisper と CTranslate2 による優れたバックエンド
この活動を経済的に支援してくださった方々
最後に、このプロジェクトを継続し、バグを特定してくれたこのプロジェクトの OS 貢献者に感謝します。
@article { bain2022whisperx ,
title = { WhisperX: Time-Accurate Speech Transcription of Long-Form Audio } ,
author = { Bain, Max and Huh, Jaesung and Han, Tengda and Zisserman, Andrew } ,
journal = { INTERSPEECH 2023 } ,
year = { 2023 }
}

