./imagesに配置しますDockerfile更新してバイナリを含めますf()でメトリクスをエンコード、デコード、計算するコードを追加します。TUPLE_CODECSに追加します
docker build -t image_compression_comparison .
docker run -it -v $(pwd):/image_compression_comparison image_compression_comparison
python3 script_compress_parallel.py
特定のメトリック値を対象としたエンコードが実行され、結果がそれぞれのデータベース ファイルに保存されます。次に例を示します。
main(metric='ssim', target_arr=[0.92, 0.95, 0.97, 0.99], target_tol=0.005, db_file_name='encoding_results_ssim.db')main(metric='vmaf', target_arr=[75, 80, 85, 90, 95], target_tol=0.5, db_file_name='encoding_results_vmaf.db')
compression_results_[PID]_[TIMESTAMP].txt内compression_results_worker_[PID]_[TIMESTAMP].txt sqlite3 データベース ファイルの場合、たとえば、 encoding_results_vmaf.dbおよびencoding_results_ssim.db 。
BD レートのパーセンテージは、 compute_BD_rates.pyというスクリプトを使用して計算できます。スクリプトは引数を 1 つ受け取ります。
python3 compute_BD_rates.py [db file name]
そして、すべてのソース イメージのBD Rate VMAF 、 BD Rate SSIM 、 BDRate MS_SSIM 、 BDRate VIF 、 BDRate PSNR_Y 、およびBDRate PSNR_AVGの値と、ソース データセットの平均を出力します。 BD レートは、 420サンプリングと444サブサンプリングの両方について出力されます。 PSNR_AVG 、すべての色成分にわたって重み付けされた MSE であり、それぞれの色成分のサンプル数に従って重み付けされたMSE_AVGから導出されます。
また、 analyze_encoding_results.pyというスクリプトも含まれています。
スクリプトは 2 つの引数を取ります。
python3 analyze_encoding_results.py [metric_name like vmaf OR ssim] [db file name]
BD レートは、ターゲット品質の全範囲にわたって 1 つの集計された数値を提供することに注意してください。 BD レートだけを見ると、特定の洞察が失われる可能性があります。たとえば、圧縮効率は、具体的には VMAF=95 動作点とどのように比較されるのでしょうか?
別の例として、BD レートがゼロだとします。レート品質曲線がクロスオーバーし、たとえば VMAF=95 の動作点では一方のコーデックが他方のコーデックよりも大幅に優れ、低ビットレート領域では悪化する可能性は十分にあります。
理想的には、画像アセットが UI で使用するためにエンコードされる場合、VMAF=95 などの明確に定義された動作品質が必要になります。そしておそらく、低品質領域からの結果は重要ではない可能性があります。したがって、(b) で説明されている洞察は、BD レートによってもたらされる「全体的な」洞察を強化します。
同時ワーカープロセスの数は次のように指定できます。
pool = multiprocessing.Pool(processes=4, initializer=initialize_worker)
実行しているシステムを考慮すると、適切な同時実行性は、プロセッサ コアの数または使用可能な RAM の量と、テスト対象のコーデックのアンサンブルで最も要求の厳しいエンコーダ プロセスによって消費されるメモリによって制限される可能性があります。たとえば、encoder_A インスタンスが通常 5 GB の RAM を消費し、合計 RAM が 32 GB の場合、24 (または 6 を超える) プロセッサ コアがある場合でも、妥当な同時実行数は 6 (32 / 5) に制限される可能性があります。
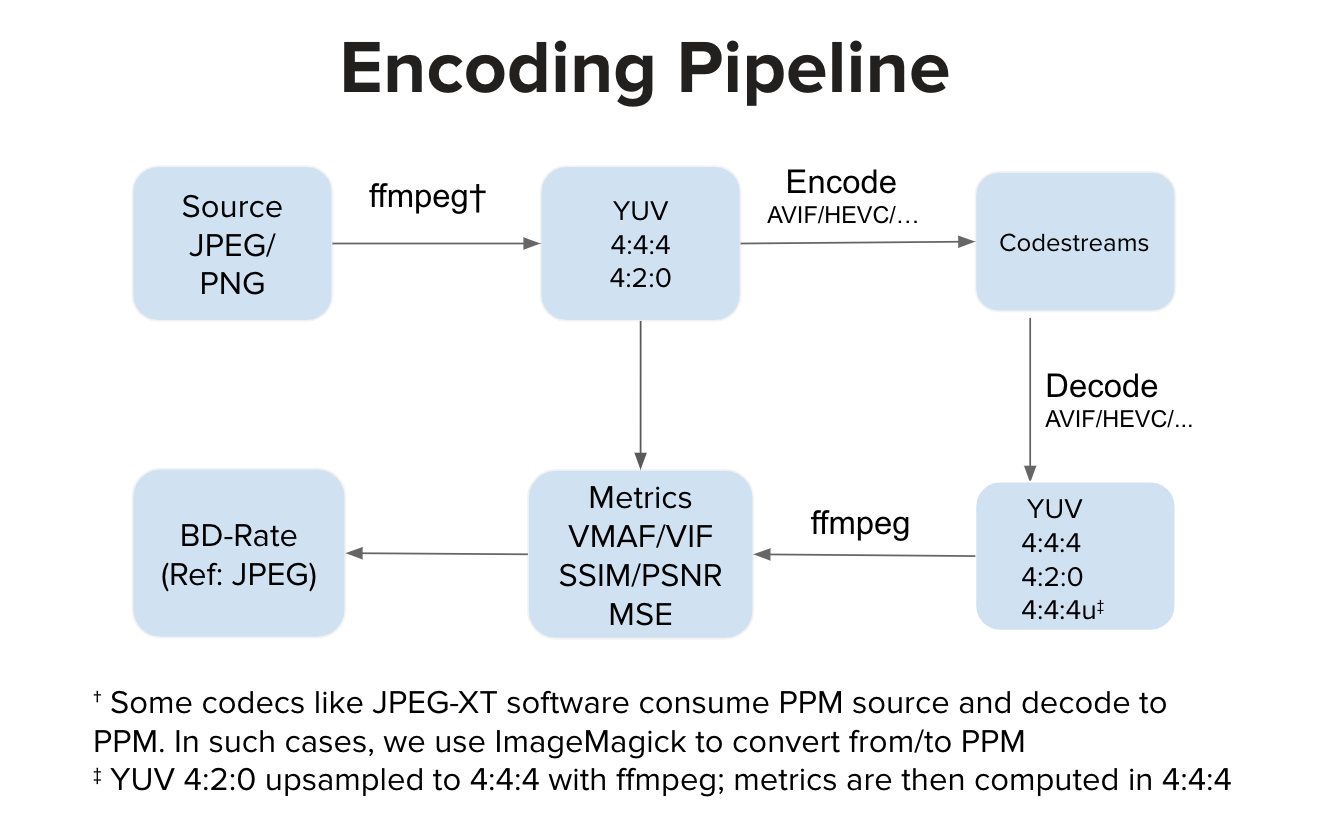
理想的には、エンコーダーの実装は YUV 入力を消費し、コードストリームを生成します。理想的には、デコーダ実装はコードストリームを消費し、YUV 出力にデコードします。次に、YUV 空間でメトリクスを計算します。ただし、JPEG-XT ソフトウェアのように、PPM 入力を消費して PPM 出力を生成する実装もあります。このような場合、YUV 空間での高品質な計算の前に、ソース PPM から YUV への変換と、デコードされた PPM から YUV への変換が行われる可能性があります。通常のパイプラインと比較して、追加の変換ステップによりわずかな歪みが生じる可能性がありますが、実験ではこれらのステップによって VMAF スコアに目立った低下は生じませんでした。