[論文] [プロジェクトページ] [miniFLUXモデル] [SD3モデル⚡️] [デモ?]
これは、フロー マッチングに基づいたトレーニング効率の高い自己回帰ビデオ生成メソッドである Pyramid Flow の公式リポジトリです。オープンソース データセットのみでトレーニングすることにより、解像度 768p、24 FPS で高品質の 10 秒ビデオを生成でき、画像からビデオへの生成も当然サポートします。
| 10秒、768p、24fps | 5秒、768p、24fps | 画像からビデオへ |
|---|---|---|
花火.mp4 | トレーラー.mp4 | 日曜日.mp4 |
2024.11.13 768p miniFLUX チェックポイント(最大 10 秒)をリリースしました。
人間の構造の問題を修正するためにモデル構造を SD3 から mini FLUX に切り替えました。1024p 画像チェックポイント、384p ビデオ チェックポイント (最大 5 秒)、および 768p ビデオ チェックポイント (最大 10 秒) をお試しください。新しい miniflux モデルは、人間の構造と動作の安定性が大幅に向上していることを示しています
2024.10.29 ⚡️⚡️⚡️ VAE のトレーニング コード、DiT の微調整コード、およびゼロからトレーニングされた FLUX 構造の新しいモデル チェックポイントをリリースします。
2024.10.13マルチ GPU 推論と CPU オフロードがサポートされています。 8 GB 未満の GPU メモリで使用すると、複数の GPU で大幅な高速化が実現します。
2024.10.11 ???ハグフェイスのデモが利用可能です。 @multimodalart のコミットに感謝します!
2024.10.10 Pyramid Flowのテクニカルレポート、プロジェクトページ、モデルチェックポイントを公開しました。
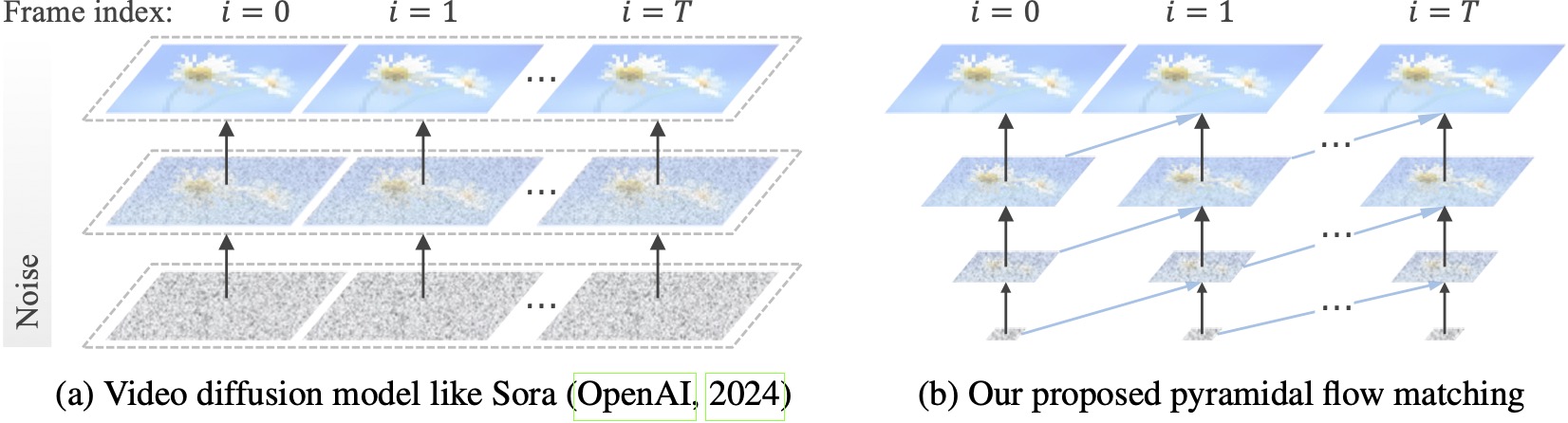
既存のビデオ拡散モデルはフル解像度で動作し、非常にノイズの多い潜在に多くの計算を費やします。対照的に、私たちの方法は、フローマッチング(Lipman et al., 2023; Liu et al., 2023; Albergo & Vanden-Eijnden, 2023)の柔軟性を利用して、異なる解像度とノイズレベルの潜在要素間を補間し、同時生成とノイズレベルを可能にします。より良い計算効率でビジュアルコンテンツを解凍します。フレームワーク全体は単一の DiT でエンドツーエンドで最適化されており (Peebles & Xie、2023)、20.7k A100 GPU トレーニング時間内で 768p 解像度および 24 FPS の高品質 10 秒ビデオを生成します。
conda で環境を構築することをお勧めします。コードベースは現在 Python 3.8.10 と PyTorch 2.1.2 (ガイド) を使用しており、より幅広いバージョンをサポートするために積極的に取り組んでいます。
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow
# create env using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txt次に、Huggingface からモデルをダウンロードします (miniFLUX または SD3 の 2 つのバリエーションがあります)。 miniFLUX モデルは 1024p 画像、384p および 768p ビデオの生成をサポートし、SD3 ベースのモデルは 768p および 384p ビデオの生成をサポートします。 384p チェックポイントは 24FPS で 5 秒のビデオを生成し、768p チェックポイントは 24FPS で最大 10 秒のビデオを生成します。
from huggingface_hub import snapshot_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download ( "rain1011/pyramid-flow-miniflux" , local_dir = model_path , local_dir_use_symlinks = False , repo_type = 'model' )開始するには、まず Gradio をインストールし、モデル パスを #L36 に設定して、ローカル マシンで実行します。
python app.pyGradio デモはブラウザで開きます。 @tpc2233 のコミットに感謝します。詳細については #48 を参照してください。
または、Hugging Face Space で簡単に試してみませんか? @multimodalart によって作成されました。 GPU の制限により、このオンライン デモは 25 フレームしか生成できません (8FPS または 24FPS でエクスポート)。スペースを複製して、より長いビデオを生成します。
Google Colab で Pyramid Flow をすぐに試すには、以下のコードを実行します。
# Setup
!git clone https://github.com/jy0205/Pyramid-Flow
%cd Pyramid-Flow
!pip install -r requirements.txt
!pip install gradio
# This code downloads miniFLUX
from huggingface_hub import snapshot_download
model_path = '/content/Pyramid-Flow'
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
# Start
!python app.py
私たちのモデルを使用するには、このリンクにあるvideo_generation_demo.ipynbの推論コードに従ってください。人間の構造と動作の安定性が大幅に向上していることが示されている、最新の公開済みのピラミッドミニフラックスを試してみることを強くお勧めします。使用するパラメータmodel_name pyramid_fluxに設定します。これをさらに単純化し、次の 2 段階の手順にします。まず、ダウンロードしたモデルをロードします。
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers . utils import load_image , export_to_video
torch . cuda . set_device ( 0 )
model_dtype , torch_dtype = 'bf16' , torch . bfloat16 # Use bf16 (not support fp16 yet)
model = PyramidDiTForVideoGeneration (
'PATH' , # The downloaded checkpoint dir
model_name = "pyramid_flux" ,
model_dtype ,
model_variant = 'diffusion_transformer_768p' ,
)
model . vae . enable_tiling ()
# model.vae.to("cuda")
# model.dit.to("cuda")
# model.text_encoder.to("cuda")
# if you're not using sequential offloading bellow uncomment the lines above ^
model . enable_sequential_cpu_offload ()その後、独自のプロンプトでテキストからビデオへの生成を試すことができます。 384p バージョンは現在 5 秒のみをサポートしていることに注意してください (設定温度は 16 まで)。
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate (
prompt = prompt ,
num_inference_steps = [ 20 , 20 , 20 ],
video_num_inference_steps = [ 10 , 10 , 10 ],
height = height ,
width = width ,
temp = 16 , # temp=16: 5s, temp=31: 10s
guidance_scale = 7.0 , # The guidance for the first frame, set it to 7 for 384p variant
video_guidance_scale = 5.0 , # The guidance for the other video latent
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./text_to_video_sample.mp4" , fps = 24 )自己回帰モデルとして、私たちのモデルは、(テキスト条件付き) 画像からビデオへの生成もサポートしています。
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
image = Image . open ( 'assets/the_great_wall.jpg' ). convert ( "RGB" ). resize (( width , height ))
prompt = "FPV flying over the Great Wall"
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate_i2v (
prompt = prompt ,
input_image = image ,
num_inference_steps = [ 10 , 10 , 10 ],
temp = 16 ,
video_guidance_scale = 4.0 ,
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./image_to_video_sample.mp4" , fps = 24 )また、GPU メモリ要件を削減するために 2 種類の CPU オフロードもサポートしています。効率が犠牲になる可能性があることに注意してください。
cpu_offloading=Trueパラメーターを生成関数に追加すると、 12 GB 未満のGPU メモリで推論が可能になります。この機能は @Ednaordinary によって提供されました。詳細については #23 を参照してください。model.enable_sequential_cpu_offload()を呼び出すと、 8 GB 未満の GPU メモリで推論が可能になります。この機能は @rodjjo によって提供されました。詳細については #75 を参照してください。 @niw のおかげで、Apple Silicon ユーザー (M2 24GB を搭載した MacBook Pro など) も、MPS バックエンドを使用してモデルを試すことができます。詳細は#113をご覧ください。
複数の GPU を使用するユーザー向けに、シーケンス並列処理を使用して各 GPU のメモリを節約する推論スクリプトを提供します。これにより大幅な高速化も実現し、4 つの A100 GPU で 5 秒、768p、24fps のビデオを生成するのにかかる時間はわずか 2.5 分です (一方、単一の A100 GPU では 5.5 分)。次のコマンドを使用して 2 つの GPU で実行します。
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.sh現在、2 または 4 GPU (SD3 バージョンの場合) をサポートしており、元のスクリプトではさらに多くの構成が利用可能です。 @tpc2233 が作成したマルチ GPU Gradio デモを起動することもできます。詳細については #59 を参照してください。
ネタバレ: 効率的なピラミッド フロー設計のおかげで、トレーニングでシーケンスの並列処理さえ使用しませんでした。
guidance_scaleパラメーターは、視覚的な品質を制御します。テキストからビデオへの生成中の 768p チェックポイントには [7, 9] 以内のガイダンスを使用し、384p チェックポイントには 7 以内のガイダンスを使用することをお勧めします。video_guidance_scaleパラメータはモーションを制御します。値を大きくするとダイナミック度が増し、自己回帰生成による劣化が軽減され、値を小さくするとビデオが安定します。VAE をトレーニングするためのハードウェア要件は、少なくとも 8 つの A100 GPU です。このドキュメントを参照してください。これは MAGVIT-v2 のような連続 3D VAE であり、非常に柔軟です。 VAE トレーニング コードのこの部分に独自のビデオ生成モデルを自由に構築してください。
DiT を微調整するためのハードウェア要件は、少なくとも 8 つの A100 GPU です。このドキュメントを参照してください。 Pyramid Flow の自己回帰バージョンと非自己回帰バージョンの両方の手順を提供します。前者はより研究指向であり、後者はより安定しています (ただし、時間ピラミッドなしでは効率が低下します)。
次のビデオの例は、5 秒、768p、24fps で生成されています。詳しい結果については、プロジェクト ページをご覧ください。
東京.mp4 | エッフェル.mp4 |
波.mp4 | レール.mp4 |
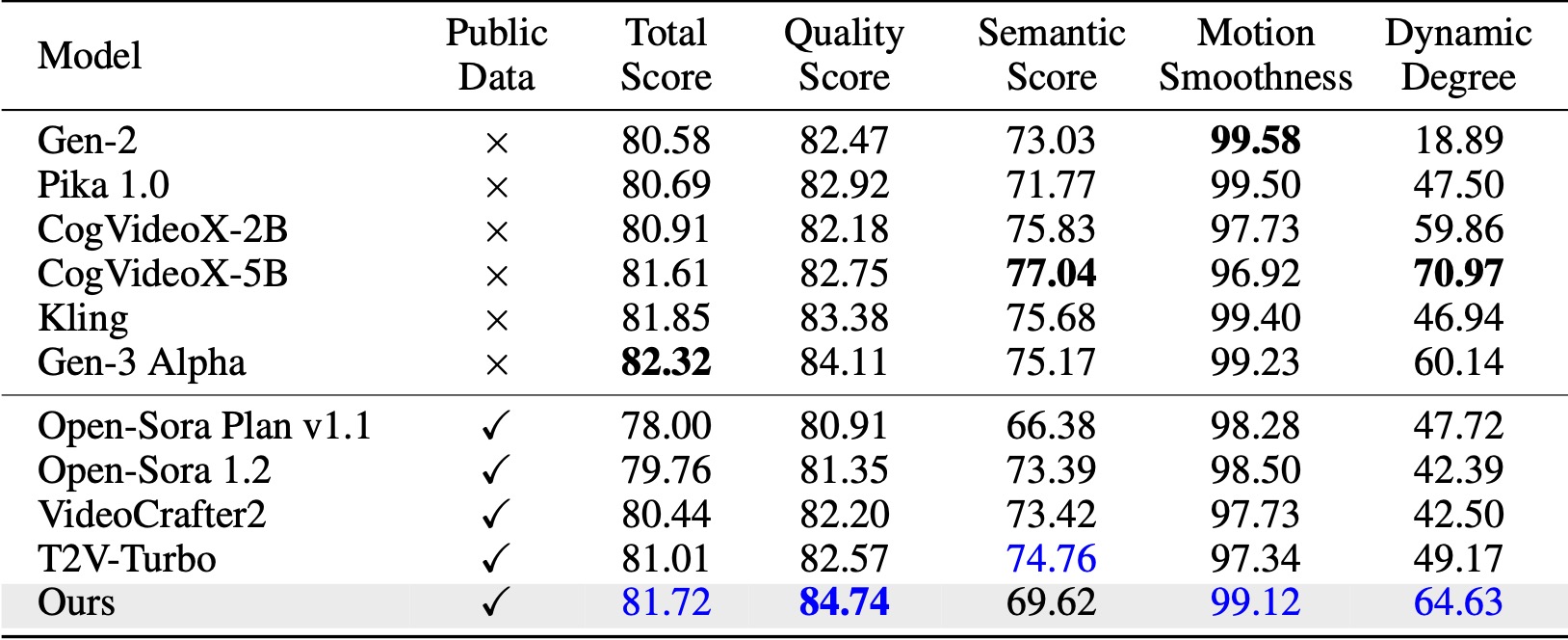
VBench (Huang et al., 2024) では、私たちの手法は比較されたすべてのオープンソース ベースラインを上回っています。公開されているビデオ データのみでも、特に品質スコア (Gen-3 の 84.74 対 84.11) とモーションの滑らかさにおいて、Kling (Kuaishou、2024) や Gen-3 Alpha (Runway、2024) などの商用モデルと同等のパフォーマンスを達成します。 。
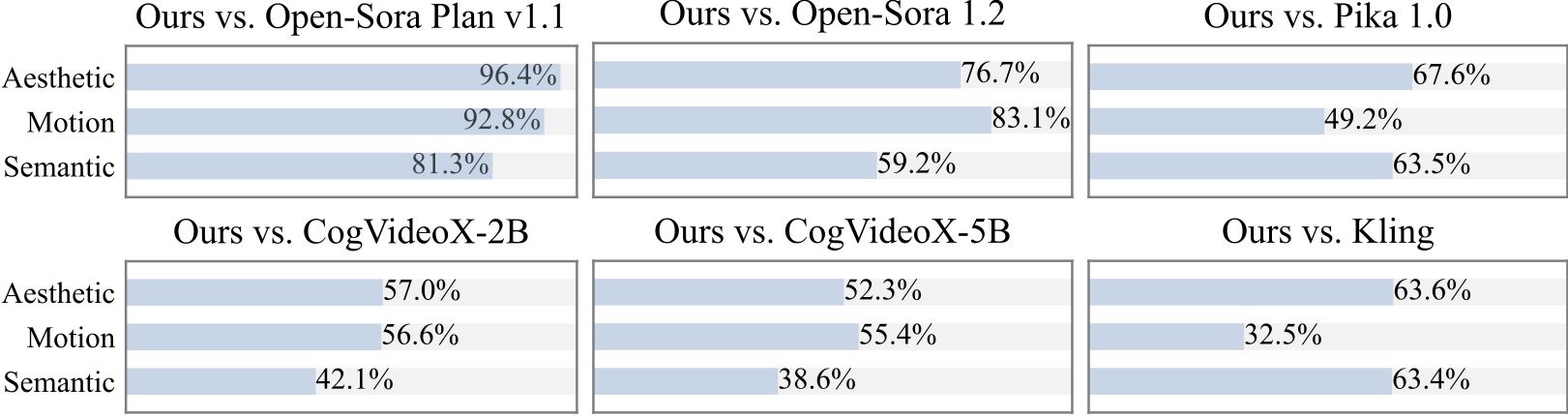
20 人以上の参加者を対象に追加のユーザー調査を実施します。ご覧のとおり、特に動きの滑らかさの点で、私たちの方法は Open-Sora や CogVideoX-2B などのオープンソース モデルよりも好まれています。
Pyramid Flow を実装する際に、次の素晴らしいプロジェクトに感謝します。
研究に役立つ場合は、このリポジトリに星を付け、出版物の中で Pyramid Flow を引用することを検討してください。
@article{jin2024pyramidal,
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
jounal={arXiv preprint arXiv:2410.05954},
year={2024}
}


